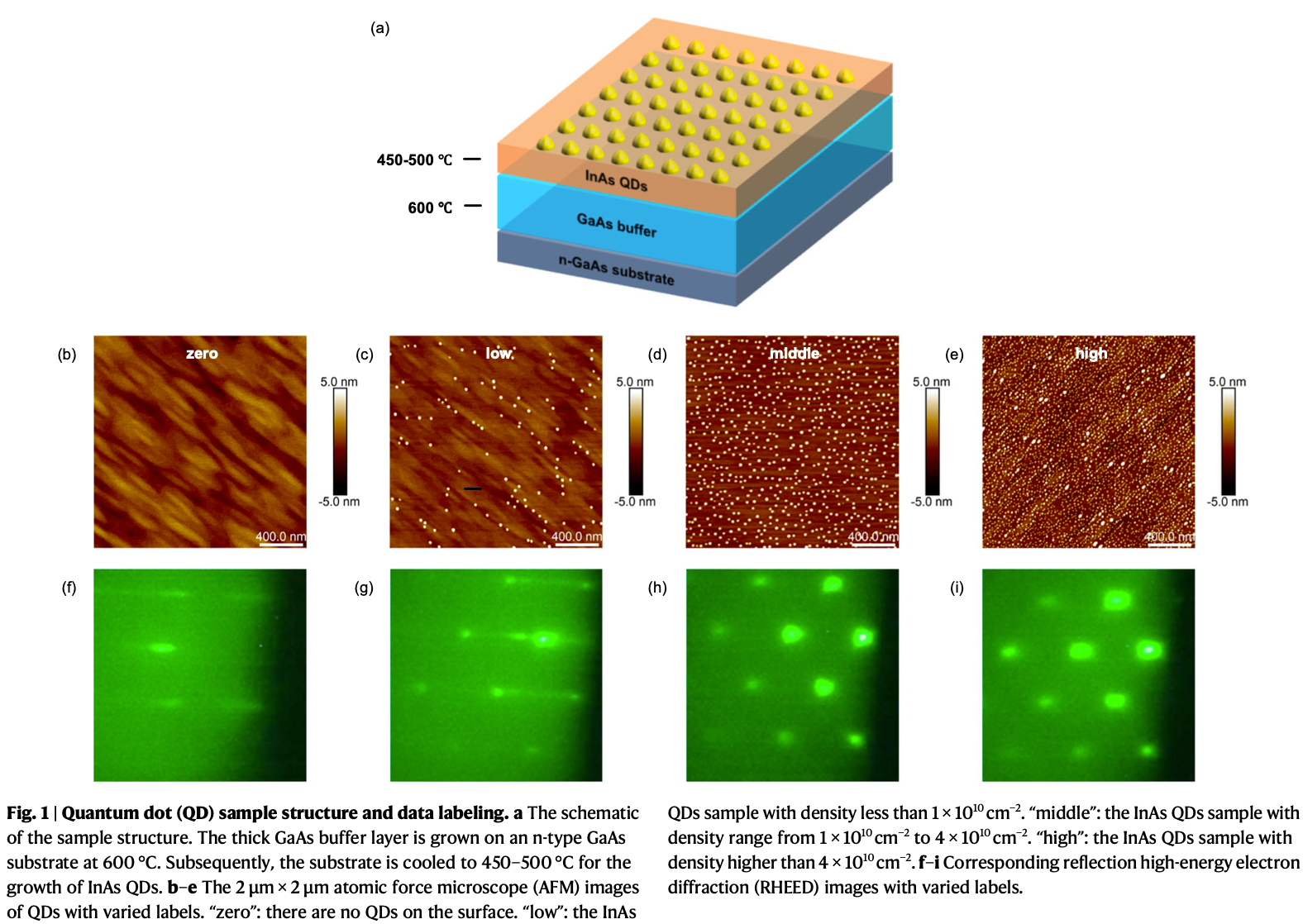
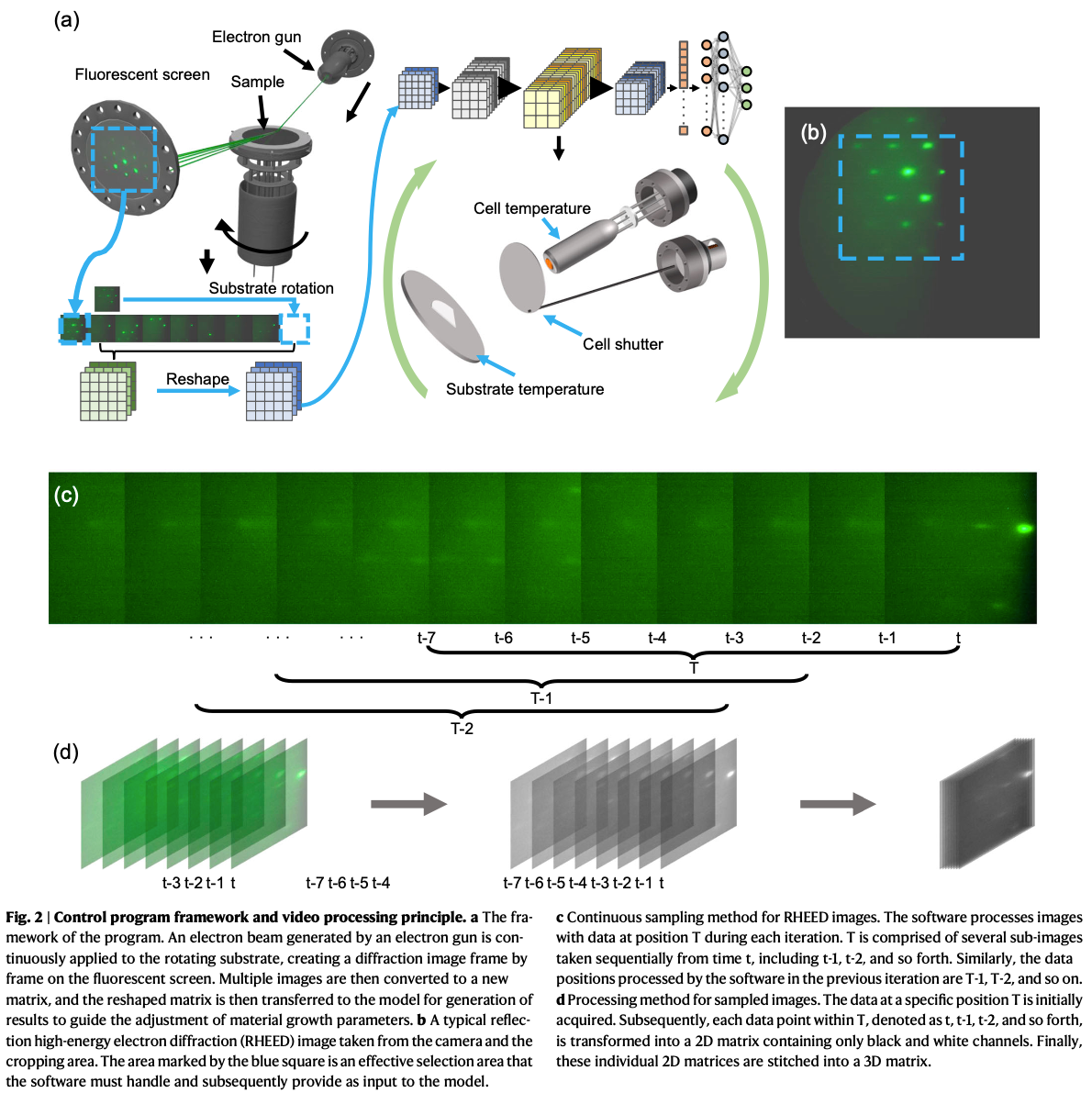
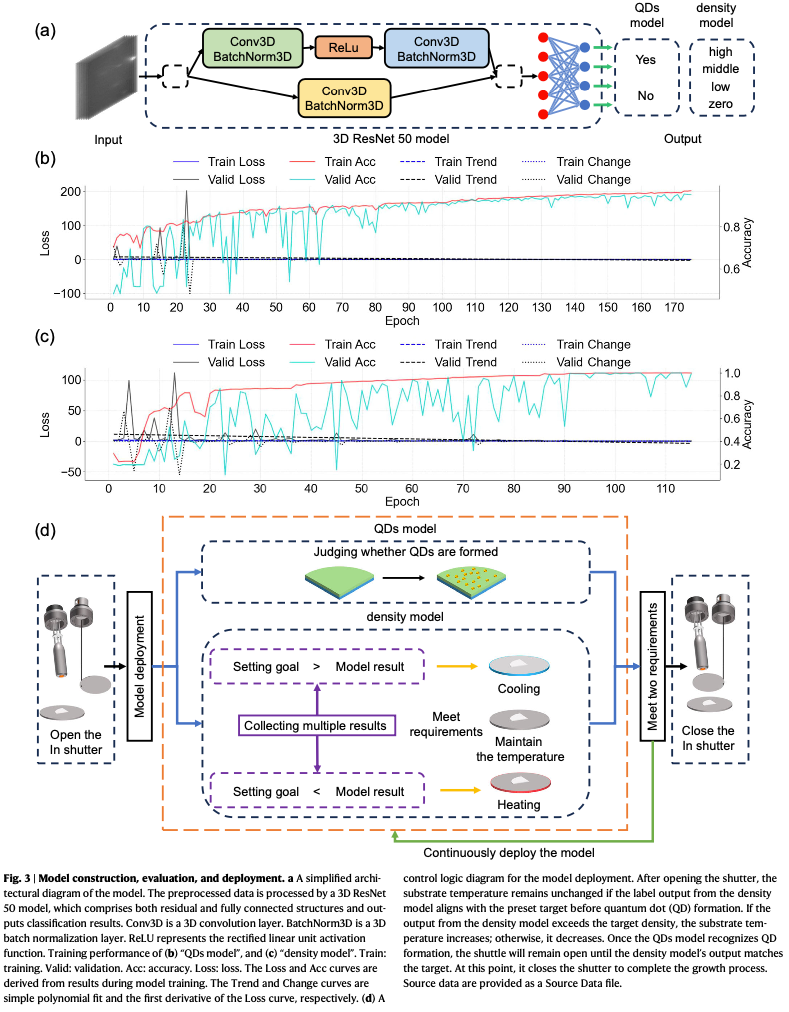
长波红外探测器科普:从热成像原理到 InAs/GaSb 超晶格、MBE 与 AI
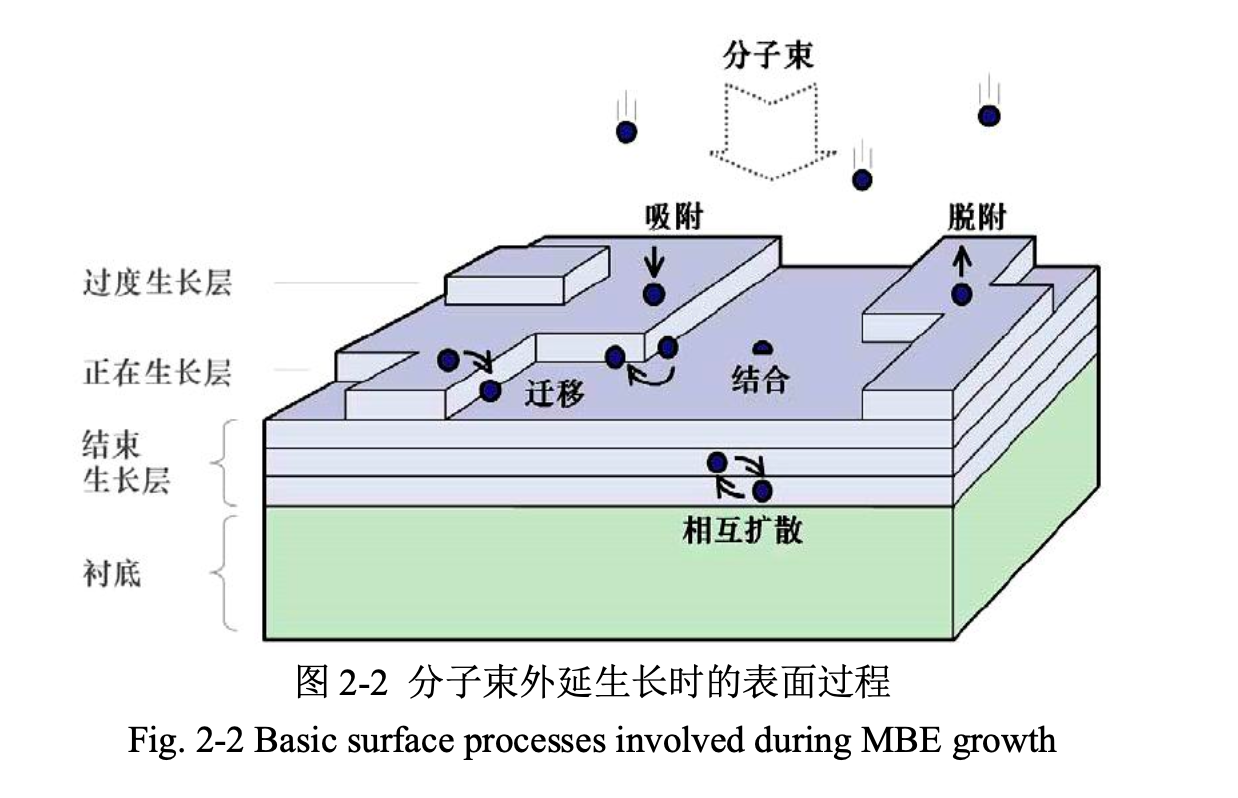
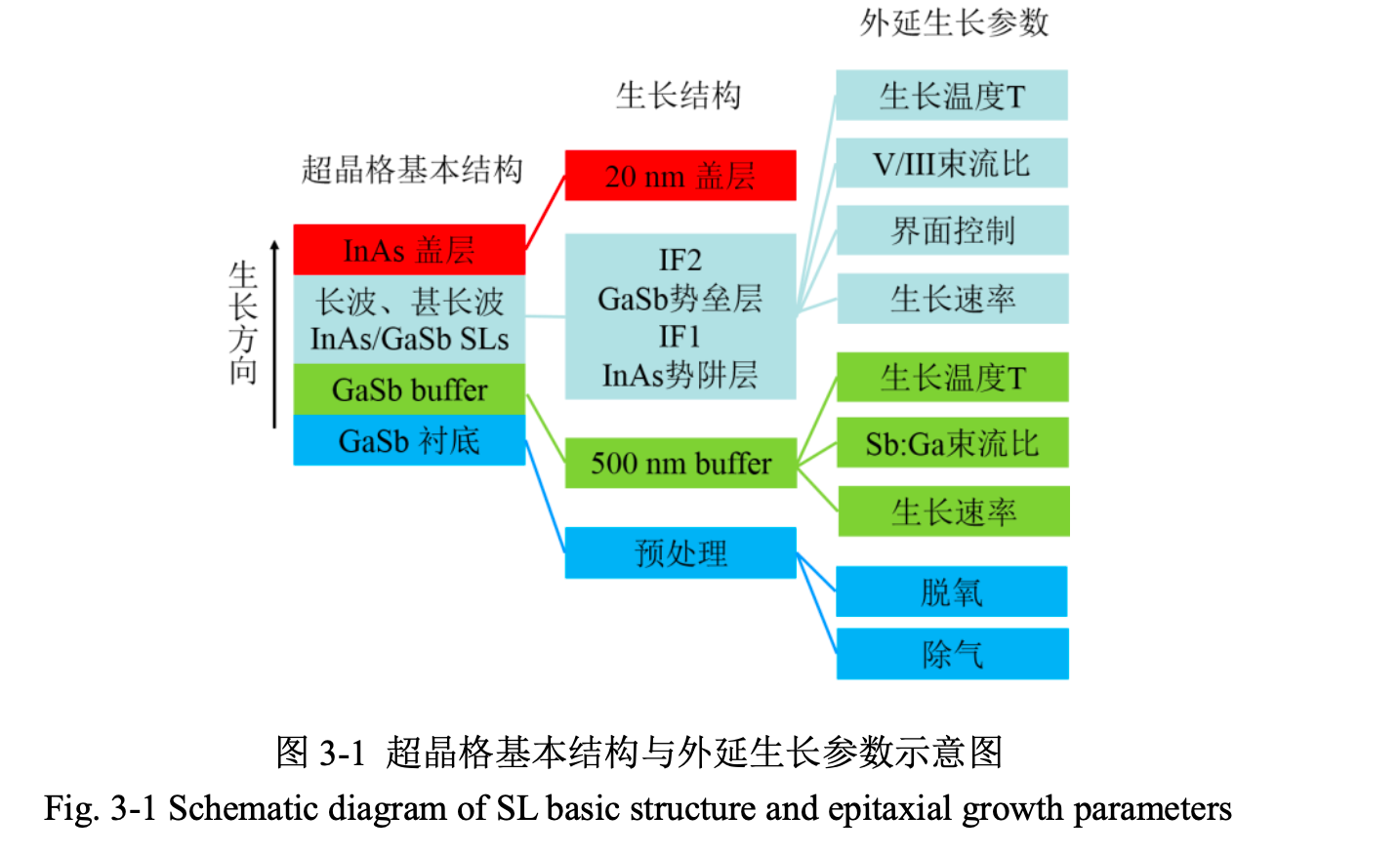
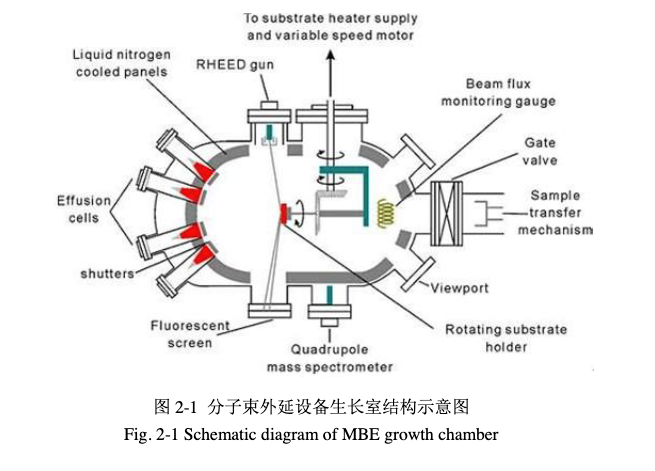
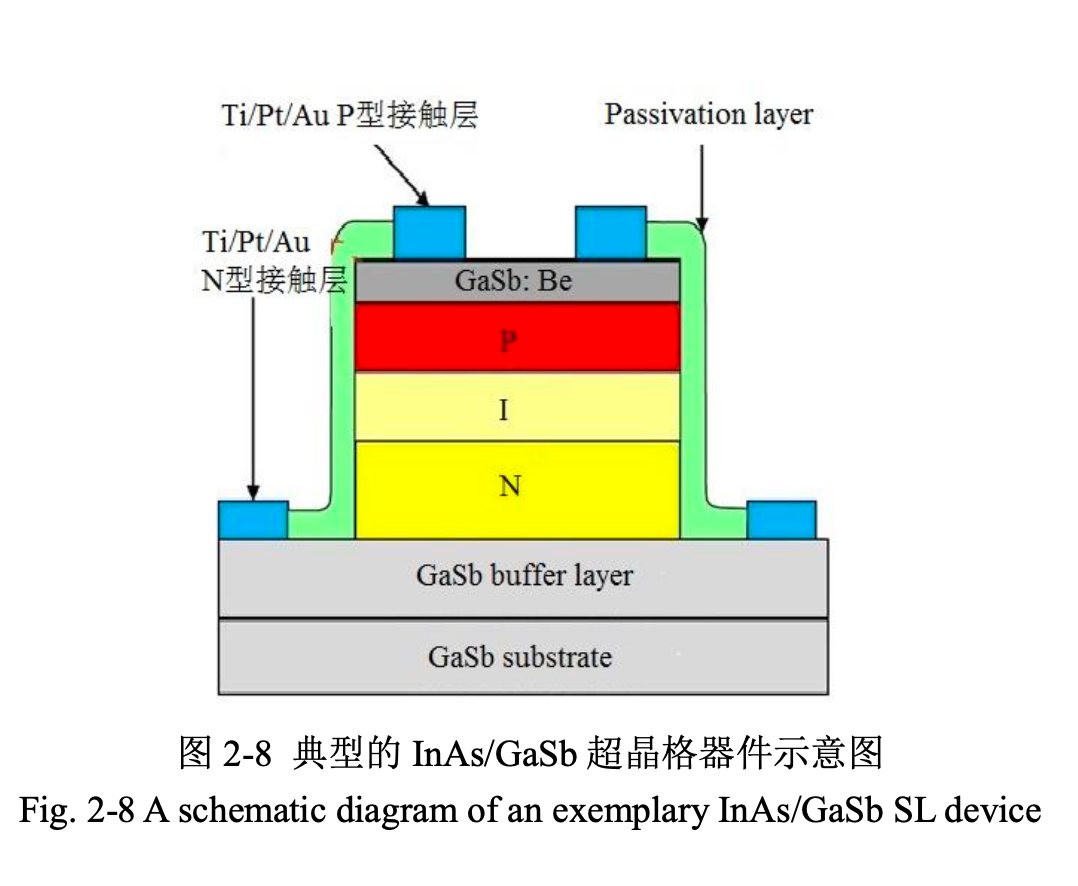
合并长波红外探测器工作原理与 InAs/GaSb 二类超晶格 MBE 生长学习笔记,从热辐射、制冷/非制冷路线、微测辐射热计、HgCdTe、QWIP、T2SL、器件工艺、表征方法一直串到 AI 辅助材料生长和红外图像理解。
Research Hub
本页面记录在 人工智能 (AI)、光电技术 (Optoelectronics)、材料分析 (Materials Analysis) 及 半导体物理 (Semiconductor Physics) 等领域的研究动态、学术笔记及深度思考,探索跨学科前沿技术的足迹。

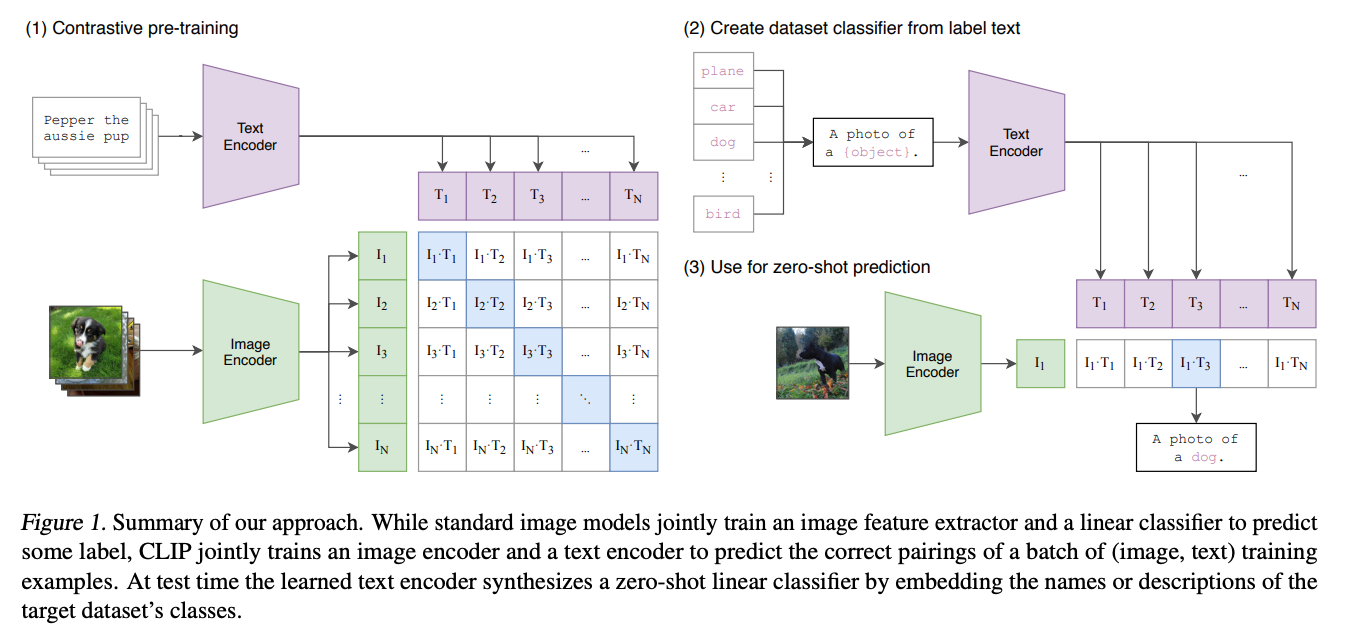
论文:Learning Transferable Visual Models From Natural Language Supervision (Radford et al., OpenAI, 2021)
论文地址:https://arxiv.org/pdf/2103.00020
代码:https://github.com/OpenAI/CLIP
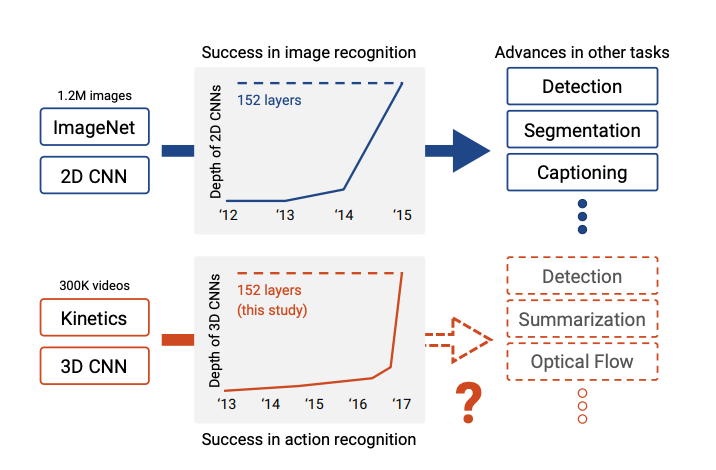
3D ResNet 对视频理解的重要性,很像 2D ResNet 对图像理解的重要性。它不是最早的 3D CNN,也不是最花哨的结构,但它非常关键地回答了一个问题:只要数据集足够大,3D CNN 能不能像 2D CNN 一样,通过更深的网络学到可迁移的通用表示?
论文:Can Spatiotemporal 3D CNNs Retrace the History of 2D CNNs and ImageNet?