论文解读:CLIP-从自然语言监督中学习可迁移的视觉模型
条评论论文:Learning Transferable Visual Models From Natural Language Supervision (Radford et al., OpenAI, 2021)
论文地址:https://arxiv.org/pdf/2103.00020
代码:https://github.com/OpenAI/CLIP
一、背景与动机
1.1 传统计算机视觉的三⼤痛点
尽管深度学习⾰命了计算机视觉,但在 CLIP 论文发表时(2021年初),主流⽅法存在三个核⼼问题:
- 标注数据集昂贵且狭窄:ImageNet 数据集的构建需要 25,000+ ⼯作者标注 1400 万张图像覆盖 22,000 个物体类别。即便如此,它也只能监督有 限的预定义视觉概念。
- 模型通⽤性差:标准视觉模型是”单任务专家”——⽐如 ImageNet 模型只能识别 1000 个类别,换⼀个任务就需要重新构建数据集、添加输出头、微调模 型。
- 基准性能与实际性能脱节(稳健性差距):模型在基准测试上表现优秀甚至超越⼈类,但在真实场景或分布偏移(distribution shift)下性能急剧下降。论⽂将这种现 象称为”作弊式学习”——模型学会了考试题的答案,但没学会真正的视觉理解。
1.2 核心思路:从自然语言中学习视觉
CLIP 的核⼼思想⾮常直接——利⽤互联⽹上⼤量存在的”图像-⽂本”配对数据作为监督信号,让模型学会将视觉概念与⾃然语⾔描述关联起来。
这样的好处:
- 不需要⼈⼯标注:互联⽹上有⼤量免费且多样的图像-⽂本对(如 Instagram 图⽚+描述、新闻图⽚+标题)
- 不受类别数量限制:⾃然语⾔可以描述任意视觉概念
- 零样本泛化:训练完成后,只需提供新任务的类别名称(或描述),模型就能进⾏分类,不需要额外 训练数据
- 学习到更鲁棒的特征:由于没有直接针对特定基准训练,模型不会过拟合特定分布的偏置
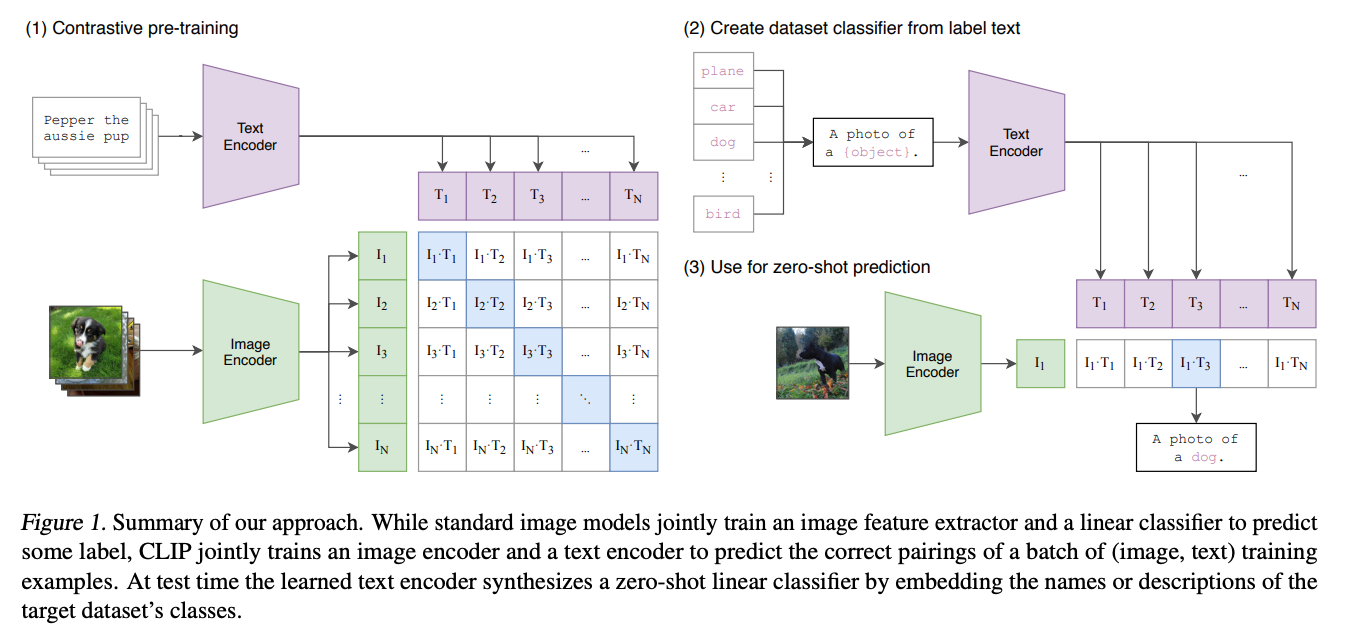
二、方法:对比语言-图像预训练
2.1 数据集:WIT (WebImageText)
CLIP 使⽤了⼀个⾃建的数据集 **WIT (WebImageText)**,包含 4 亿对(图像, ⽂本),从互联⽹上收集。
构建⽅式:
- 以 Wikipedia 中出现⾄少 100 次的单词作为查询词
- 加上⾼互信息(pointwise mutual information)的单词对作为查询词
- 补充所有 WordNet synsets
- 每个查询词最多保留 20,000 对 (image, text)
- 总词数与 GPT-2 训练的 WebText 数据集规模相当
2.2 对比学习目标函数
CLIP 的核⼼训练⽬标:给定⼀个 batch 的 N 个 (image, text) 对,模型需要预测哪 N 个配对是真实的。
具体来说:
- 通过图像编码器提取图像特征 $I_f$,通过⽂本编码器提取⽂本特征 $T_f$
- 分别通过线性投影映射到联合多模态嵌⼊空间:$I_e = \text{L2_Normalize}(W_i \cdot I_f)$,$T_e = \text{L2_Normalize}(W_t \cdot T_f)$
- 计算成对余弦相似度,乘以可学习的温度参数 $\tau$:$\text{logits} = I_e \cdot T_e^T \times \exp(\tau)$
- 对称交叉熵损失:图像到⽂本 + ⽂本到图像的交叉熵损失取平均
1 | # CLIP 核心训练的 Numpy 伪代码 |
为什么选对比学习而不是生成式?
论⽂实验证明:
- 预测 BoW (Bag-of-Words) 的基线⽐ Transformer 语⾔模型 快 3 倍
- CLIP 的对比⽬标⼜⽐预测 BoW 快 4 倍
- 总体上,CLIP 对⽐⽬标⽐图像描述⽣成 (image-to-caption) ⾼效 4-10 倍
原因:预测图⽚配⻚的准确完整⽂本是⼀个⾮常困难的任务(描述⽅式⼏乎⽆限),⽽只需要判断”哪个⽂本 与这张图最匹配”是⼀个更简单、更有效的代理任务。
2.3 模型架构
图像编码器:两种选择
- ResNet:采⽤ ResNet-50, ResNet-101, 以及遵循 EfficientNet 的 scaled 版本(RN50x4, RN50x16, RN50x64),计算量按宽、深、分辨率等⽐例分配
- **Vision Transformer (ViT)**:采⽤ ViT-B/32, ViT-B/16, ViT-L/14,在 patch + position embedding 后添加了额外的 layer normalization
文本编码器:Transformer
- 基于 GPT-2 的 63M-parameter 12 层 512 宽的 Transformer,8 个注意⼒头
- 词汇量:49,152 (BPE),最⼤序列⻓度:76
- 使⽤ masked self-attention(保留了使⽤预训练语⾔模型初始化的可能性)
- 取 [EOS] token 对应最⾼层的激活值作为⽂本特征表⽰
- 使⽤ layer normalization 后线性投影到多模态空间
2.4 训练规模
- 训练时间:在 256 个 GPU 上训练 2 周(与当时最⼤规模的视觉模型相当)
- CLIP 系列模型从 RN50 到 RN50x64,计算量跨越 44 倍
- 零样本性能随模型计算量呈 log-log 线性提升
三、零样本推理
3.1 零样本推理流程
CLIP 实现零样本分类的步骤:
- 构造分类器:将每个类别的名称转成句⼦(如 “a photo of a {label}”),通过文本编码器得到类别嵌入向量
- 计算相似度:输入图像通过图像编码器得到图像嵌入,与所有类别嵌入计算余弦相似度
- softmax 分类:选择相似度最高的类别作为预测结果
这使得 CLIP 可以零样本应⽤于任意的视觉分类任务,不需要任何该任务 的训练数据。
3.2 prompt 工程和 Ensembling
CLIP 发现零样本性能对⽂本 prompt 的措辞很敏感。简单的类别名(如 “dog”)不如完 整的句⼦效果好。
Prompt 工程示例:
- 细粒度分类:
"A photo of a {label}, a type of pet."(Oxford-IIIT Pets) - 食物分类:
"A photo of {label}, a type of food."(Food101) - OCR 数据集:在⽂本或数字周围加引号
- 卫星图像:
"A satellite photo of {label}." - ImageNet:使⽤ 80 种不同的 prompt 模板进⾏集成
Prompt Ensembling:
- ⽣成多个零样本分类器(⽐如使⽤不同上下⽂ prompt),在 嵌⼊空间 上进⾏平均
- 好处:只需缓存平均后的⽂本嵌⼊,推理开销与使⽤单个分类器相同
效果:Prompt 工程 + ensembling 在 ImageNet 上额外提升近 5% 精度。
3.3 零样本性能亮点
- ImageNet 零样本准确率 76.2% :与原始 ResNet-50 在有监督训练下的表现相当,但没使⽤任何 ImageNet 训练样本
- 在 27 个数据集上与 ResNet-50 线性分类器对⽐:零样本 CLIP 在 16 个数据集上表现更好
- 零样本 ≈ 4-shot 线性分类器:在相同特征空间上,零样本 CLIP 匹配 4-shot 逻辑回归的性能。在某些数据集上,需要 16-184 个有标签样本/类别才能匹配 CLIP 的零样本效果
- 在 aYahoo 上 98.4% (远超 Visual N-Grams 的 72.4%)、SUN 上 58.5% (远超 23.0%)
四、表征学习:线性探测评估
除了零样本迁移,论⽂也通过线性探测(linear probe)评估了 CLIP 学习到的表征质量。
4.1 与最先进模型的对比
在 Kornblith et al. 的 12 个数据集上:
- CLIP 最⾼分模型 (ViT-L/14) 超越所有对比⽅法(包括 Noisy Student EfficientNet-L2, BiT-M, SimCLRv2, BYOL, MoCo)
- CLIP 模型是计算效率最高的:相⽐其他⽅法,在相同前向传播计算量下,CLIP 模型的线性探测性能明显更⾼
在更⼴泛的 27 个数据集上,结论更加显著:
- 最好的 CLIP 模型在 21/27 个数据集上超越 Noisy Student EfficientNet-L2
- 尤其在 OCR (SST2, HatefulMemes)、地理定位 (Country211)、动作识别 (Kinetics700, UCF101)、细粒度分类 (Stanford Cars, GTSRB) 上表现突出
4.2 为何 CLIP 表征更好?
论⽂推测关键原因在于监督信号的宽度:
- ImageNet 只有 1000 个类别,对⻋辆只有⼀个 “car” 标签
- 这导致监督表征将不同⻋型的内部差异压缩,在细粒度下游任务上表现差
- CLIP 的⾃然语⾔监督天然包含了更细粒度的语义信息
五、鲁棒性:分布偏移下的表现
5.1 有效稳健性 (Effective Robustness)
CLIP 最令⼈振奋的发现之⼀是零样本模型在分布偏移下的表现远优于监督模型。
论⽂在 7 个评估⾃然分布偏移的数据集上进⾏测试:ImageNetV2, ImageNet Sketch, ImageNet-R, ImageNet-A, ObjectNet, Youtube-BB, ImageNet-Vid。
核⼼发现:
- 零样本 CLIP 将”稳健性差距(robustness gap)”缩⼩了 75%
- 对⽐同样 ImageNet 准确率的 ResNet-101,CLIP 在 ObjectNet 上提⾼了 **+51.2%**,在 ImageNet-A 上提⾼了 +74.4%
- 所有零样本 CLIP 模型的有效稳健性(ImageNet 准确率 vs 分布偏移准确率的对应关系)都⾮常接近理想 $y=x$ 线
5.2 “适应 ImageNet”的代价
让 CLIP 适应 ImageNet(训练线性分类器)后:
- ImageNet 准确率提⾼ 9.2% (达到 85.4%,匹配 2018 年 SOTA)
- 但在 7 个分布偏移数据集上的平均准确率略有下降
- 这意味着监督适应带来的提升可能主要是”学会了 ImageNet 特有的偏置”,⽽不是通⽤视觉理解的 增强
启发:减少模型接触数据集的分布特 定信息,虽然可能降低在该数据集上的分数,但能提升泛化能⼒。CLIP 零样本评估⽐标准 ImageNet 基准更能代表模型的真实能⼒。
5.3 Few-Shot 与鲁棒性
- 少样本 CLIP(线性探测)⽐标准 ImageNet 模型更鲁棒,但不如零样本 CLIP 鲁棒
- 随着适应数据增加,有效稳健性逐渐降低
- 这表明:最小化分布特定的训练数据量 → 更高的有效稳健性,但代价是降低数据集特定的性能
六、实验发现拾遗
6.1 与人类对照实验
在 Oxford-IIIT Pets 数据集上的⼈类对照实验:
| 设置 | ⼈类准确率 | CLIP 准确率 |
|---|---|---|
| 零样本 | 53.7% | 93.5% |
| 单样本 | 75.7% | - |
| 双样本 | 75.7% | - |
关键发现:
- ⼈类零样本时犹豫不确定的图像,在获得 1 个示例后准确率⼤幅提升——⼈类”知道⾃⼰不知道什么”
- CLIP 的零样本强但少样本提升有限,与⼈类形成鲜明对⽐——说明 CLIP 并未有效利⽤先验知识进⾏ 少样本学习
- 在 最难类别上的排序,⼈类和 CLIP 差异较⼩(CLIP 难的任务⼈也难)
6.2 about数据泄露的检验
论⽂仔细检验了预训练数据和下游评估数据之间的重叠问题:
- 35 个数据集中,9 个完全⽆重叠(⼈造/专⽤数据集如 MNIST, CLEVR, GTSRB)
- 中位数重叠率 2.2% ,平均重叠率 3.2%
- 最⼤的整体准确率提升仅为 0.6% (Birdsnap),⼤多数 <0.1%
- 结论:数据泄露并未显著影响 CLIP 的零样本性能
七、局限性
论⽂坦诚地讨论了 CLIP 的多⽅⾯局限性:
7.1 任务层面
| 弱点 | 表现 |
|---|---|
| 抽象/系统化任务 | 计数(CLEVRCounts)仅略好于随机猜测 |
| 复杂推理 | 预测”最近⻋的距离”(KITTI Distance)接近随机 |
| ⾮常细粒度的分类 | ⻋型号、⻜机型号、花种区分能⼒远弱于专⼯模型 |
| 分布外数据 | MNIST ⼿写数字仅 88%(远低于⼈类 99.75% 和专⼯模型) |
7.2 方法层面
- 计算资源需求巨⼤:约需要 1000 倍⽬前的计算量才能达到整体 SOTA,在当前硬件下不可⾏
- 数据效率低:32 个 epoch 处理 128 亿张图⽚,不解决深度学习的数据效率问题
- Prompt 依赖:零样本分类器对 prompt 措辞敏感,需要反复”prompt 工程”
- 验证集泄漏:虽然声称零样本,开发过程中反复查询验证集来指导模型开发
- 评估数据集选择:部分与 CLIP 的能⼒共同适应(co-adapted)
7.3 应⽤层面
- 许多复杂视觉概念和任务难以仅通过⽂本描述来指定
- 零样本到少样本过渡时性能反降(与⼈类学习⽅式相反)
- 存在社会偏见问题(⻅下⽂)
八、社会影响与偏见
论⽂⽤了相当篇幅分析 CLIP 的社会影响:
8.1 人口统计偏见
- 零样本 CLIP 在 FairFace 种族分类上准确率仅为 58.3% (远低于专⼯模型的 93.7%)
- ⽽在性别分类上达到 95.9% ,说明模型对不同属性的掌握程度不均匀
- 在”非白人”群体上准确率反⽽更⾼(91.3%),但在不同种族亚群上存在差异
8.2 标签设计的敏感性
论⽂进⾏了⼀项颇具启发性的实验:
- 当标签集包含 “thief”, “criminal”, “animal”, “gorilla” 等贬义标签时,0-20 岁⼈群的约 32.3% 被归类到这些不当标签
- 当加⼊ “child” 标签后,这⼀⽐例降到 8.7%
- 这揭示了类别设计对 CLIP 模型⾏为的深远影响——任⼚开发者可以定义任意类别,模型就会产⽣结果
8.3 监控与隐私
- CCTV 粗糙分类(停车场、校园……)准确率 91.8%,但添加 “close” 干扰选项后降到 51.1%
- 零样本名⼈脸识别:100 类别 top-1 准确率 59.2%(与⾕歌 Celeb Rec 等⽣产级模型⽐仍有差距)
- 潜在⻛险:CLIP 降低了构建定制化监控应⽤的门槛
九、关键洞察与总结
核⼼贡献
- 证明大规模自然语言监督可以学习高质量、可迁移的视觉表征——将 NLP 的”预训练 + 任务无关”范式成功移植到计算机视觉
- 对比学习⽬标远⾼效于预 测/生成⽅法——相⽐图像描述⽣成,效率提升 4-10 倍
- 零样本评估更接近真实能⼒——不针对特定基准优化,表现更具代表性,有效稳健性提升 75%
- 开放更灵活的任务交互⽅式——仅通过修改 prompt ⽂本即可定制分类器
技术路线图
1 | 互联⽹图像+⾃然语⾔描述(400M 对) |
⽭待解决的⽅向
- 提升模型在抽象推理、计数、结构化任务上的能⼒
- 改善数据效率和计算效率
- 发展更好的 prompt ⾃动化⽅法,减少⼿⼯ prompt 工程
- 结合自我监督、自训练方法弥补数据效率短板
- ⽣态监测和缓解社会偏见
总体来看,CLIP 不仅提出了⼀种具体的技术⽅案,更是开创了”⾃然语⾔监督学习”的新范式,为后续的多模态模型(如 DALL·E、Stable Diffusion 等图像⽣成模型,以及 GPT-4V 等多模态⼤语⾔模型)奠定了基础。