论文解读:3D ResNet 与视频动作识别
条评论3D ResNet 对视频理解的重要性,很像 2D ResNet 对图像理解的重要性。它不是最早的 3D CNN,也不是最花哨的结构,但它非常关键地回答了一个问题:只要数据集足够大,3D CNN 能不能像 2D CNN 一样,通过更深的网络学到可迁移的通用表示?
论文:Can Spatiotemporal 3D CNNs Retrace the History of 2D CNNs and ImageNet?
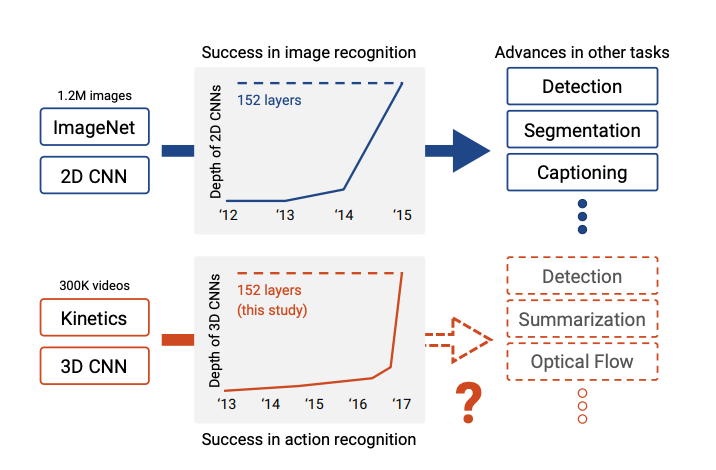
一、先看这篇论文在回答什么问题
2017 年前后,视频理解已经有不少方向在推进,比如 C3D、双流网络、I3D、LSTM 融合等,但大家普遍有一个现实困难:视频模型很重,数据却不够大。
图像领域之所以能爆发,很大程度上是因为 ImageNet 既足够大,又能支撑 VGG、GoogLeNet、ResNet 这类深层网络训练。作者于是提出一个很自然的问题:
视频领域能不能也走一遍类似路径?
也就是:Kinetics 这样的数据集,能不能像 ImageNet 一样,支撑深层 3D CNN 的训练和迁移?
这篇论文的题目看起来像在问历史能否重演,本质上是在做一件基础设施级别的验证:
- 小数据集为什么训练不好 3D CNN;
- Kinetics 是否足够大到可以支撑深层 3D ResNet;
- 在 Kinetics 上预训练后,3D ResNet 能否迁移到 UCF-101、HMDB-51 这样的下游任务。
所以它的价值不只是提出一个模型,而是明确了 3D CNN 的训练范式。
二、为什么视频任务要从 2D 卷积走向 3D 卷积
图像分类处理的是单帧输入,输入张量通常可以写成:
$$
C \times H \times W
$$
视频动作识别多了时间维度,输入张量变成:
$$
C \times T \times H \times W
$$
如果仍然只做 2D 卷积,那么模型每次只能看一帧,时序关系需要交给后面的池化、RNN 或其他模块处理;但动作的本质恰恰来自“连续变化”,例如挥手、跳跃、投掷、起身,这些语义都离不开时间维度。
因此 3D 卷积把卷积核从:
$$
k_h \times k_w
$$
扩展成:
$$
k_t \times k_h \times k_w
$$
其中:
| 维度 | 作用 |
|---|---|
| $k_t$ | 建模短时间窗口内的动作变化 |
| $k_h$ | 建模垂直方向空间结构 |
| $k_w$ | 建模水平方向空间结构 |
这样做之后,卷积核不再只看“这张图长什么样”,还会看“前后几帧是怎么变的”。
论文使用的 clip 输入尺寸通常是:
$$
3 \times 16 \times 112 \times 112
$$
也就是 16 帧 RGB 小视频块。模型不是直接看完整视频,而是把视频切成很多 clip 学习局部时空模式,再在测试时对多个 clip 的预测做聚合。
三、3D ResNet 和 2D ResNet 到底是什么关系
如果已经熟悉 2D ResNet,这篇论文其实很好懂。核心思想几乎没变,只是把卷积算子从 2D 换成了 3D。
2D ResNet 的残差单元写成:
$$
y = F(x) + x
$$
3D ResNet 仍然写成:
$$
y = F(x) + x
$$
差别在于 $F(x)$ 这条主分支中,卷积由二维卷积变成了三维卷积。
1. Basic Block
对于较浅的网络,如 ResNet-18、ResNet-34,作者使用的是 basic block。
对应到 3D 版本,就是两层 3 x 3 x 3 卷积堆叠,再加 shortcut。
2. Bottleneck Block
对于 ResNet-50/101/152/200,则使用 bottleneck 结构,基本形式是:
$$
1 \times 1 \times 1 \rightarrow 3 \times 3 \times 3 \rightarrow 1 \times 1 \times 1
$$
它的思想和 2D ResNet 一样:
- 先降维,减少中间计算量;
- 在中间做最核心的空间时间特征提取;
- 再升维,恢复通道表达能力。
这让网络能变得更深,而计算量不会失控。
四、论文到底做了哪些模型比较
很多人提到这篇论文时,会只记得 “3D ResNet”。但如果认真看实验,其实作者做的是一整套“把 2D CNN 时代的成功经验搬到 3D 世界里再验证一遍”的工作。
论文比较了:
| 模型 | 特点 |
|---|---|
| ResNet-18 / 34 | 浅层 3D 残差网络 |
| ResNet-50 / 101 / 152 / 200 | 逐步加深的 3D bottleneck 网络 |
| Pre-activation ResNet-200 | 预激活残差结构 |
| Wide ResNet-50 | 不只加深,还增加通道宽度 |
| ResNeXt-101 | 使用 group convolution,引入 cardinality |
| DenseNet-121 / 201 | 使用密集连接 |
作者真正想比较的是三件事:
- 深度增加是否仍然有效;
- 更宽的网络是否有效;
- ResNeXt 这种“多分支聚合”思想在 3D 卷积里是否还成立。
这也是为什么这篇论文常被视为视频版 “ResNet/ResNeXt 经验总结”。
五、为什么小数据集训练不好 3D CNN
这是论文非常关键的一点。
作者先在四个数据集上训练 ResNet-18:
| 数据集 | 特点 |
|---|---|
| UCF-101 | 小规模动作分类数据集 |
| HMDB-51 | 更小,类别较少 |
| ActivityNet | 中等规模,但视频更复杂、背景更多 |
| Kinetics | 大规模动作识别数据集 |
实验发现:
- 在 UCF-101、HMDB-51 上,从头训练时训练误差下降很快,但验证误差很差,明显过拟合;
- ActivityNet 虽然比前两者大,但对深层 3D CNN 仍不够理想;
- 只有 Kinetics 明显具备支撑深层 3D CNN 训练的能力。
这件事的重要性在于,它告诉我们:
3D CNN 的难点不只是结构,更是数据规模。
很多“3D CNN 效果不好”的结论,本质上可能是“数据太小,模型没训开”。
换句话说,视频模型比图像模型更吃数据,因为它不仅要学空间特征,还要学时间模式。
六、Kinetics 为什么这么关键
Kinetics 在这篇论文中的地位,几乎就是视频版 ImageNet。
它关键在于:
- 类别多,覆盖大量日常动作;
- 视频数量大,足以减少 3D CNN 的过拟合;
- 每个样本不是静态图,而是自然视频片段,时序信息充足。
这让 3D CNN 首次有机会像 2D CNN 那样:
- 先在大规模通用数据集上学习底层通用表征;
- 再迁移到小数据集和下游任务上。
这就是论文题目里 “retracing the history of 2D CNNs and ImageNet” 的真正含义。
七、核心实验结果应该怎么读
1. 深度增加确实有收益
Kinetics 上,3D ResNet 随着深度增加整体持续变好:
| 模型 | Top-1 | Top-5 | Average |
|---|---|---|---|
| ResNet-18 | 54.2 | 78.1 | 66.1 |
| ResNet-34 | 60.1 | 81.9 | 71.0 |
| ResNet-50 | 61.3 | 83.1 | 72.2 |
| ResNet-101 | 62.8 | 83.9 | 73.3 |
| ResNet-152 | 63.0 | 84.4 | 73.7 |
| ResNet-200 | 63.1 | 84.4 | 73.7 |
这个结果很像 2D ResNet 在 ImageNet 上的走势:
- 从浅层到中深层提升明显;
- 到非常深之后,收益开始变小;
- “能训很深” 本身已经是一个巨大突破。
这说明 3D 残差结构确实把深层时空网络的优化难题压下去了。
2. 加宽和 ResNeXt 更进一步
论文中综合表现最强的是更宽的网络和 ResNeXt:
| 模型 | Top-1 | Top-5 | Average |
|---|---|---|---|
| Wide ResNet-50 | 64.1 | 85.3 | 74.7 |
| ResNeXt-101 | 65.1 | 85.7 | 75.4 |
这说明在 3D CNN 中:
- 不是只有“加深”有效;
- 增加宽度同样有效;
- group convolution 带来的 cardinality 也有效。
也就是说,2D CNN 时代关于深度、宽度、分组卷积的经验,很多都可以平移到视频领域。
3. 更长时间窗口还能继续提升
作者又把 ResNeXt-101 从 16 帧输入扩展到 64 帧输入,性能从 average 74.5 提升到 78.4。
这点很直观:
某些动作仅看 16 帧可能只能捕捉局部姿态,而 64 帧能让模型看到更完整的动作过程。
这也提示我们,视频任务除了网络深度,还要关心“时间感受野”。
八、迁移学习结果为什么特别重要
如果只看 Kinetics 的精度提升,这篇论文还只是 “3D CNN 很强”。
真正让它成为经典的,是迁移学习实验。
作者把 Kinetics 预训练模型迁移到 UCF-101 和 HMDB-51:
| 模型 | UCF-101 | HMDB-51 |
|---|---|---|
| ResNet-18 scratch | 42.4 | 17.1 |
| ResNet-18 pretrained | 84.4 | 56.4 |
| ResNet-50 pretrained | 89.3 | 61.0 |
| ResNet-152 pretrained | 89.6 | 62.4 |
| ResNet-200 pretrained | 89.6 | 63.5 |
| ResNeXt-101 pretrained | 90.7 | 63.8 |
| ResNeXt-101 64f pretrained | 94.5 | 70.2 |
这里最值得记住的不是某个单点数值,而是趋势:
- 从头训练的小模型效果很差;
- Kinetics 预训练一加上去,性能立刻大幅跃升;
- 预训练过的更深、更宽、更长时间窗口模型收益更明显。
这说明 Kinetics 预训练学到的不是数据集特有技巧,而是具有泛化性的时空表示。
九、怎么理解它和 C3D、I3D、P3D 的区别
为了不把几篇经典视频论文混在一起,可以这样区分:
| 模型 | 代表思路 |
|---|---|
| C3D | 证明 3D 卷积可行,是早期强基线 |
| I3D | 把成熟的 2D 卷积核 inflate 到 3D,并借助 ImageNet 预训练 |
| P3D / R(2+1)D | 把 3D 卷积分解为空间卷积和时间卷积 |
| 3D ResNet | 把 ResNet 体系完整搬到视频建模里 |
其中 3D ResNet 的优势不是“第一次提出 3D”,而是:
- 结构规整,工程上容易实现;
- 易于扩展成 18/34/50/101/152/200 层;
- 易于作为统一 backbone;
- 有清楚的预训练和迁移学习结论。
所以它特别适合作为视频理解入门论文。
十、这篇论文最深的一层启发
我觉得这篇论文最重要的启发不是 “3D ResNet 比某个模型高几点”,而是它把视频模型的发展逻辑理顺了:
- 先有足够大的通用视频数据;
- 再有统一、可扩展的 backbone;
- 再做预训练和迁移;
- 最后才有更复杂的下游任务体系。
后面无论是 SlowFast、X3D、Video Swin Transformer,还是各种视频 MAE、视频多模态模型,本质上都继承了这种思路:
先把通用时空表示学出来,再把它迁移到具体任务。
十一、这篇论文也有哪些局限
它当然也有局限:
- 3D 卷积计算量大,训练和部署都偏重;
- 输入分辨率较低,很多实验用的是
112 x 112; - 主要验证的是动作分类,不是更复杂的视频定位、视频问答等任务;
- 对长时依赖的建模能力仍有限,本质上还是局部卷积窗口。
所以后来的研究才会继续往两个方向走:
- 把 3D 卷积做得更高效,比如分解卷积、轻量化设计;
- 引入 Transformer 和更大规模预训练,增强长时程建模。
十二、如何把这篇论文和 2D ResNet 放在一起理解
可以把两篇论文看成同一条演化线上的两个节点:
1 | AlexNet -> VGG -> ResNet |
2D ResNet 解决的是“深层图像网络怎么稳定训练”;
3D ResNet 解决的是“深层时空网络在大规模视频数据上能不能也稳定训练,并且可迁移”。
前者给出了方法论,后者证明这套方法论在视频领域同样成立。
十三、简短总结
如果只用一句话总结这篇论文:
它让视频理解第一次真正拥有了类似 ImageNet 预训练 backbone 的训练范式。
它的意义不是把 2D ResNet 简单改成 3D,而是证明了:
- 残差学习可以稳定训练深层时空网络;
- Kinetics 足以承担视频版 ImageNet 的角色;
- 3D CNN 预训练能够形成可迁移的通用视频表示。
这也是为什么今天回头看,它仍然是视频动作识别里非常值得精读的一篇基础论文。