DeepLearner
DeepLearnerDeep Learning & AI · Optoelectronics · Materials Analysis · Semiconductor Physics
AIGC-大模型微调-LLama2-Lora医学大模型微调【风格学习】

大模型预训练成本高昂,需要庞大的计算资源和大量的数据资源,一般个人和企业难以承受。为解决这一问题,谷歌率先提出Parameter-Efficient Fine-Tuning (PEFT)技术,旨在通过最小化微调参数的数量和计算复杂度,来提高预训练模型在新任务上的性能,从而缓解大型预训练模型的训练成本。这样一来,即使计算资源受限,也可以利用预训练模型的知识来迅速适应新任务,实现高效的迁移学习。其中Lora微调为常用的PEFT技术。
AIGC-大模型微调-OpenAI-GPT3.5 Turbo医学大模型微调【风格学习】



通过微调训练,让模型从更多的提示(Prompt)数据中进行少量学习,从而让模型具备特定的任务能力,可改变模型的风格、语调、输出格式等,并提高预期输出结果的可靠性。**对模型进行微调后,您将不再需要在提示(prompt)中提供示例。**这样可以节省成本并实现更低延迟的请求。



AIGC-大模型微调-LLama2-Lora医学大模型微调



LLama2:meta-llama/Llama-2-7b-chat-hf
基础模型:conghao/llama2-7b-chat-hf
Lora模型:conghao/llama2-qlora-med-zh
基础模型为基于Llama-2-7b-chat-hf将LLama的原始权重文件转换为Transformers库对应的模型文件格式。可基于此模型进行微调。
Lora模型llama2-qlora-med-zh为基于医学数据集训练好的模型权重,损失函数收敛至0.2924。
AIGC-大模型微调-LLama2-QLoRA微调
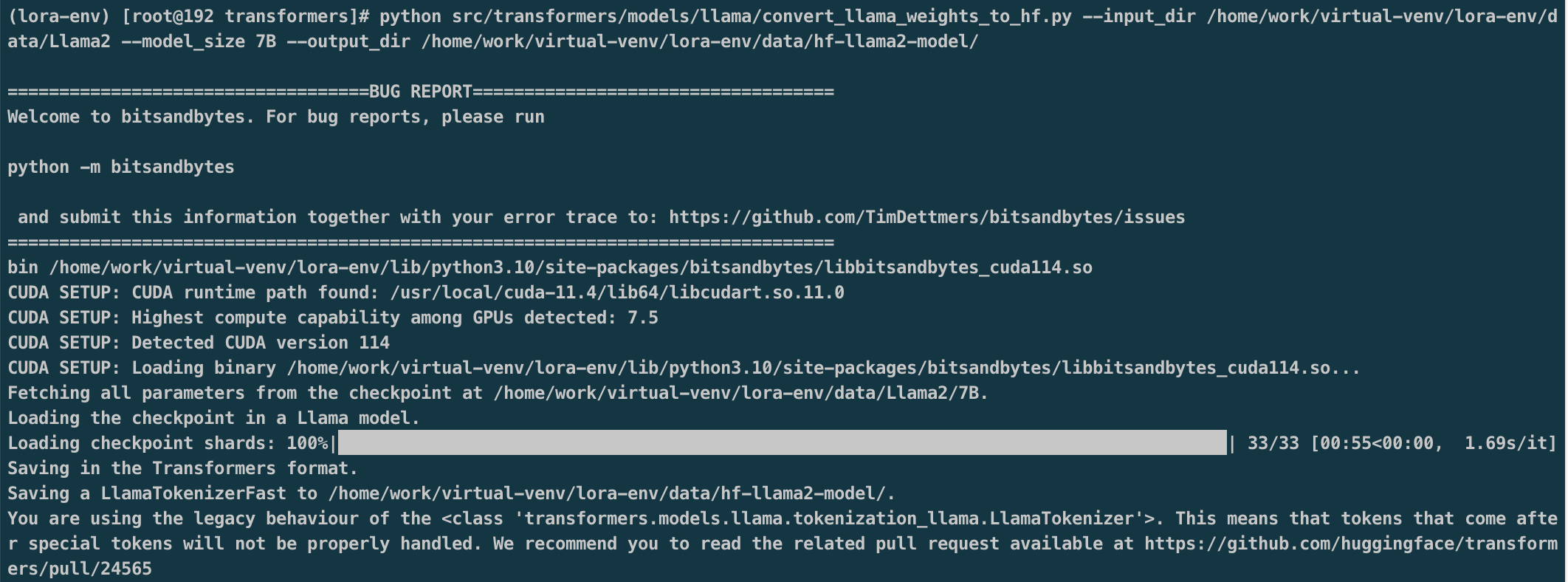
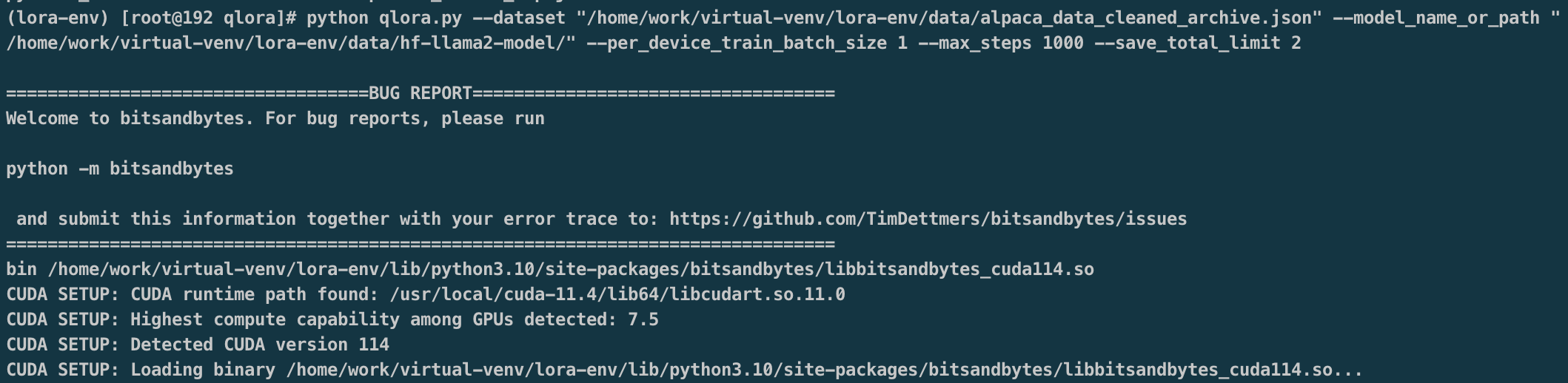
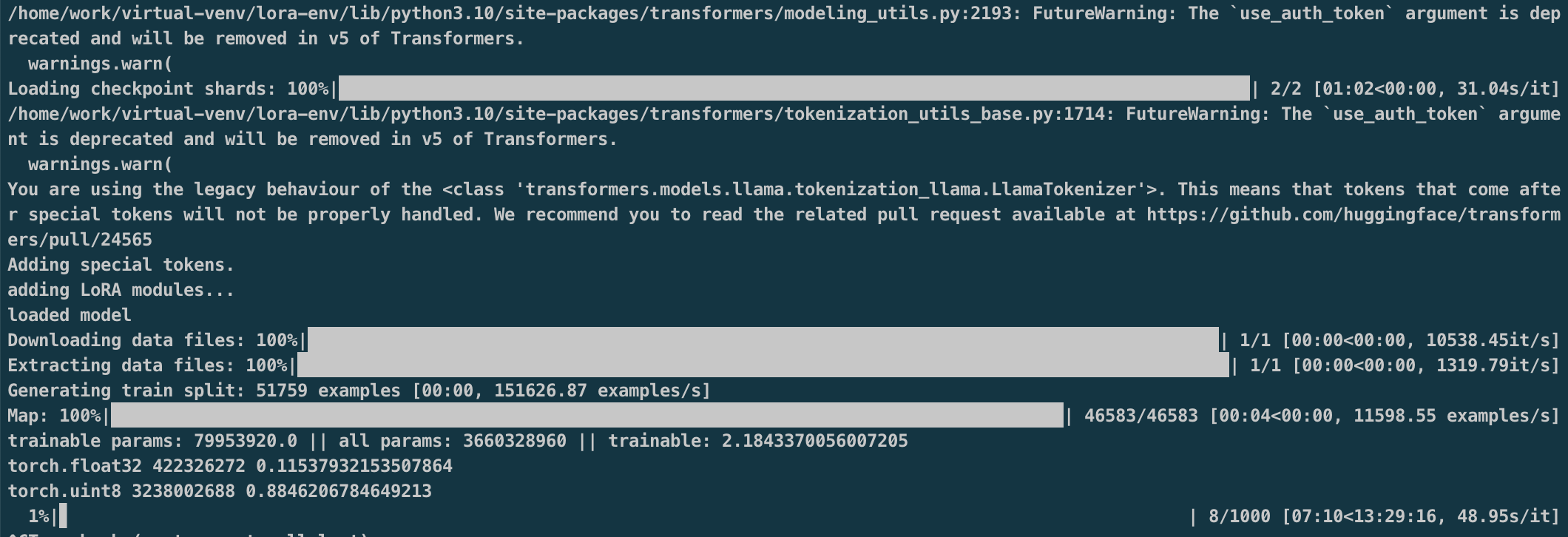
QLoRA, 它是一种”高效的微调方法”, 以LLama 65B参数模型为例,常规16 bit微调需要超过780GB的GPU内存,而QLoRA可以在保持完整的16 bit微调任务性能的情况下, 将内存使用降低到48GB,即可完成微调。
AIGC-大模型微调-PEFT技术简介

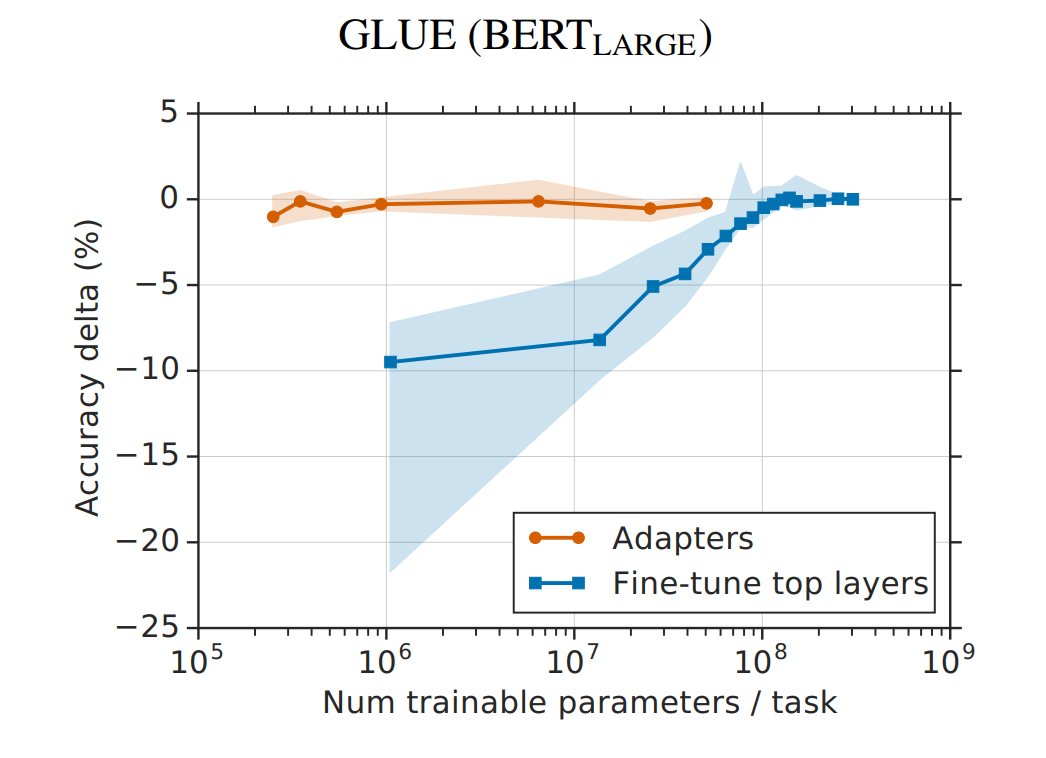
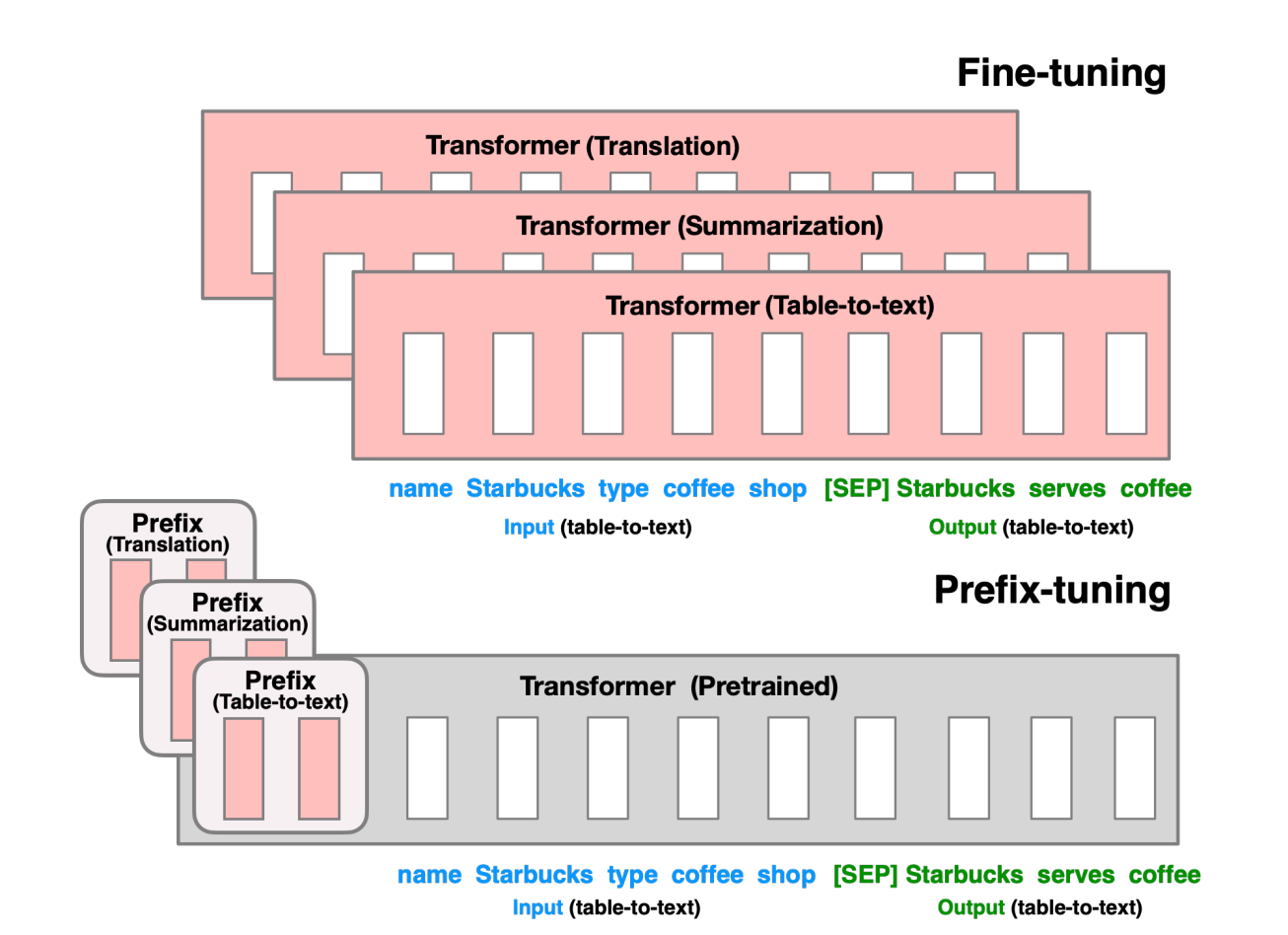
最近,基于LLama2对垂类领域的数据集做了LoRA微调,在微调过程中,系统学习了下微调方案,并对Fine Tuning方案做了对比总结。
因大模型预训练成本高昂,需要庞大的计算资源和大量的数据资源,一般个人和小企业难以承受(百度、头条花了上百亿购买显卡)。为解决这一问题,谷歌率先提出Parameter-Efficient Fine-Tuning (PEFT)技术,旨在通过最小化微调参数的数量和计算复杂度,来提高预训练模型在新任务上的性能,从而缓解大型预训练模型的训练成本。这样一来,即使计算资源受限,也可以利用预训练模型的知识来迅速适应新任务,实现高效的迁移学习。 因此PEFT技术在提升大模型效果的同时,缩短模型训练时间和成本。