AI基础方法
条评论AI基础方法调研。转自刘**整理资料。
1. 博弈论
1.1 综合及其他
- UCL:
a. 2021年7月,一个求解零和博弈的通用框架:让人工智能自己发现算法。https://mp.weixin.qq.com/s/ggCvTTAg_1mkWJfW9wY4iA
i. https://arxiv.org/abs/2106.02745 - 2019年11月,这三个博弈论新趋势,正深刻影响深度强化学习。https://mp.weixin.qq.com/s/2jzArMEN2Sd7vjY0xY17nQ,https://towardsdatascience.com/new-game-theory-innovations-that-are-influencing-reinforcement-learning-24779f7e82b1
a. 平均场博弈(Mean Field Games)
i. 平均场博弈论是一套方法和技术的组合,它被用来研究由「理性博弈方」组成的大群体下的差异化博弈。这些智能体不仅对自身所处的状态(如财富、资金)有偏好,还关注其他智能体在整个样本分布中所处的位置。平均场博弈理论正是针对这些系统对广义纳什均衡进行了研究。平均场博弈的经典案例是,如何训练鱼群朝相同方向游,或者以协作方式游。
b. 随机博弈(Stochastic games)
i. 理论上随机博弈的规则是,让有限多个博弈者在有限个状态空间中进行博弈,每个博弈者在每个状态空间都从有限个行为中选出一个行为,这些行为的组合结果会决定博弈者所获得的奖励,并得出下一个状态空间的概率分布。随机博弈的经典案例是哲学家的晚餐问题:n+1 位哲学家(n 大于等于 1)围坐在一个圆桌周围,圆桌中间放了一碗米饭。每两位邻座的哲学家之间会放一支筷子以供这两位取用。因为桌子是圆形的,筷子的数量与哲学家的数量一样多。为了从碗中取到东西吃,哲学家需要同时从两边各取一支筷子组成一双,因此,在一位哲学家吃东西时,他的两位邻座就无法同时进食。哲学家的生活简单到只需要吃和思考,而为了存活下来,哲学家需要不断地思考和吃东西。这场博弈的任务就是设计出一个可以让所有的哲学家都活下来的制度。
c. 进化博弈(Evolutionary Games)
i. 进化博弈理论(EGT)是从达尔文进化论中得到的启发。从概念上来说,EGT 是博弈论在进化场景中的应用。在这种博弈中,一群智能体通过重复选择的进化过程,与多样化的策略进行持续交互,从而创建出一个稳定的解决方案。它背后的思路是,许多行为都涉及到群体中多个智能体间的交互,而其中某一个智能体是否获得成功,取决于它采取的策略与其他智能体的策略如何交互。经典博弈论将关注点放在静态策略上,即参与者采取的策略不会随着时间改变,而进化博弈与经典博弈论不同,它关注策略如何随着时间演化,以及哪个动态策略是进化进程中最成功的那一个。EGT 的经典案例是鹰鸽博弈(Howk Dove Game),它模拟了鹰与鸽之间对可共享资源的竞争。 - 2019年10月,当博弈论遇上机器学习:一文读懂相关理论。https://mp.weixin.qq.com/s/1t6WuTQpltMtP-SRF1rT4g
1.2 Libratus
- 论文:
a. Libratus团队,教授 Tuomas Sandholm和其博士生 Noam Brown 获得了 NIPS-17 最佳论文奖,只是重点讲述这个德扑AI中的子博弈求解算法:Safe and Nested Subgame Solving for Imperfect-Information Games.pdf
b. 称霸德州扑克赛场的Libratus,是今年最瞩目的AI明星之一。2017.12.18《科学》最新发布的预印版论文,详细解读了AI赌神背后系统的全貌。Superhuman AI for heads-up no-limit poker Libratus beats top professionals.pdf - 德扑 AI 之父托马斯·桑德霍姆(http://www.cs.cmu.edu/~sandholm/):扑克 AI 如何完虐人类,和 AlphaGo 大不同:https://www.leiphone.com/news/201711/FQ92gUQNfj2hGUtv.html
- CMU 教授 Tuomas Sandholm 的个人主页显示,他和其博士生 Noam Brown 获得了 NIPS-17 最佳论文奖。
- 2018年11月,Arxiv上的一篇题为《Solving Imperfect-Information Games via Discounted Regret Minimization》引发关注,原因主要在于本文的两位作者的鼎鼎大名,CMU计算机系博士生Noam Brown,以及该校计算机系教授Tuomas Sandholm。这两位就是去年的著名的德州扑克AI程序“冷扑大师”(Libratus)的缔造者,堪称德州扑克AI之父。论文介绍了CFR算法的变体,可以对先前的迭代进行discount,并表现出比之前最先进的CFR +类算法更强大的性能,在涉及重大错误的环境中表现的更加明显。
a. 注:Counterfactual regret minimization(CFR)是目前很流行的一系列迭代算法,实际上也是近似解决大型不完美信息游戏的最快的AI算法。本算法系列中提出了一个“后悔值” (regrets)的概念,即在当前状态下,选择行为A,而不是行为B,后悔的值是多少。论文地址:Solving Imperfect-Information Games via Discounted Regret Minimization,https://arxiv.org/abs/1809.04040,中文参考:https://mp.weixin.qq.com/s/aHyvY3j33EdZwuumrS7dGQ
1.3 非对称博弈
- DeepMind 最新在nature的子刊 Scientific Report 上发表了一篇论文《Symmetric Decomposition of Asymmetric Games》,检验了两个智能系统在非对称博弈游戏(asymmetric game,包括 Leduc 扑克和多种棋牌游戏)的特定类型情景下的行为和反应。表明一个非对称博弈可以分解为多个对称博弈,从而将博弈降维,并且非对称博弈和对称变体的纳什均衡也有非常简单的对应关系研究人员认为AI 系统在现实世界中扮演的角色越来越重要,理解不同系统之间如何交互变得非常关键。这些结果还可以应用到经济学、进化生物学和经验博弈论(empirical game theory)等。该方法被证明在数学上是很简单的,允许对非对称博弈进行快速、直接的分析:s41598-018-19194-4.pdf
2. 启发式算法、模仿学习等
2.1 综述
- 从遗传算法到强化学习,一文介绍五大生物启发式学习算法:https://mp.weixin.qq.com/s/JiSixpo4xlVPgIdGsXdCsA,https://towardsdatascience.com/5-ways-mother-nature-inspires-artificial-intelligence-2c6700bb56b6
a. 人工神经网络、遗传算法、集群智能、强化学习和人工免疫系统 - 从Q学习到DDPG,一文简述多种强化学习算法:https://mp.weixin.qq.com/s/_dskX5U8gHAEl6aToBvQvg,https://towardsdatascience.com/introduction-to-various-reinforcement-learning-algorithms-i-q-learning-sarsa-dqn-ddpg-72a5e0cb6287
- DeepMind 综述深度强化学习:智能体和人类相似度竟然如此高!Reinfocement Leaming , Fast and Slow.pdf
a. 第一代 Deep RL:强大但缓慢,Deep RL 缓慢的原因:
i. 第一个原因是增量式的参数更新
ii. 第二个原因是弱归纳偏倚
b. Episodic deep RL:通过情景记忆进行快速学习
c. Meta-RL:通过学习如何学习来加速 Deep RL
d. Episodic Meta-RL:整合 Episodic deep RL 和 Meta-RL 的方法
e. 对神经科学和心理学的启示,快速和慢速 RL:更深远的意义
f. 参考:https://mp.weixin.qq.com/s/rhOIWYyPFpJFvg_Esh8Sxw,https://www.cell.com/trends/cognitive-sciences/fulltext/S1364-6613(19)30061-0
2.2 模仿学习(Imitation Learning)
- 模仿学习领域的综述文章:Global overview of Imitation Learning .pdf,https://mp.weixin.qq.com/s/naq73D27vsCOUBperKto8A
- 2019年11月,NeurIPS 2019分享:清华大学孙富春组提出全新模仿学习理论。
2.3 多智能体/群智能(Multi-agent,Swarm Intelligence)
- 上海交大:
a. 2021年7月,上海交大开源MALib多智能体并行训练框架,支持大规模基于种群的多智能体强化学习训练。https://mp.weixin.qq.com/s/DxOanlWZSdJreJmOy1dm-Q
i. https://malib.io
ii. 论文链接:https://arxiv.org/abs/2106.07551
iii. GitHub:https://github.com/sjtu-marl/malib - 善于单挑却难以协作,构建多智能体AI系统为何如此之难?https://mp.weixin.qq.com/s/0v57oHMEDcJuUivs8D5pnQ
a. https://hackernoon.com/why-coding-multi-agent-systems-is-hard-2064e93e29bb - 德国马普研究所:
a. 2019年9月,新研究登上Scientific Report,通过构建最小化的智能体模型,对生物体适应环境的集体行为的产生和变化进行了模拟,有望给相关的AI系统,如自主微型机器人等模仿生物体的集体行为的系统设计和研究提供重要参考价值。https://mp.weixin.qq.com/s/L6p7gUWXzrEqCtIrIlIkpQ
i. https://www.nature.com/articles/s41598-019-48638-8 - 德国波恩大学等:
a. 2021年6月,AI新算法登Nature封面!解决医疗数据隐私问题,超越联邦学习?https://mp.weixin.qq.com/s/75VjJkJvCmLpor2GZURZpQ
i. 德国波恩大学的研究人员联合惠普公司以及来自希腊、德国、荷兰的多家研究机构共同开发了一项结合边缘计算、基于区块链的对等网络协调的分布式机器学习方法——群体学习(Swarm Learning,以下简称SL),用于不同医疗机构之间数据的整合
ii. https://www.nature.com/articles/s41586-021-03583-3
2.4 强化学习(Reinforcement Learning)
Google
a. AlphaGo zero & AlphaZero & MuZero
i. 论文:
1. AlphaGo:Mastering the Game of Go without Human Knowledge.pdf
2. AlphaGoZero:Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm.pdf
ii. 2020年12月,超越Alpha Zero!DeepMind升级版MuZero:无需告知规则,观察学习时即可掌握游戏。https://mp.weixin.qq.com/s/ZcAYxn0oRxjv5JCCZEWElw
1. https://deepmind.com/blog/article/muzero-mastering-go-chess-shogi-and-atari-without-rules
iii. 2020年11月,AlphaGo原来是这样运行的,一文详解多智能体强化学习的基础和应用。https://mp.weixin.qq.com/s/qnAXhfGb74ivRwlGcdApOQ
iv. AI要完爆人类?解密AlphaGo Zero中的核心技术: https://www.leiphone.com/news/201710/6s3jQfFaolobG6Yx.html
v. AlphaGo Zero为何如此备受瞩目?这是8位教授和同学们的独家见解: https://www.leiphone.com/news/201710/5QuIbcYljAWKa7y5.html
vi. Deepmind AMA:关于最强ALphaGo如何炼成的真心话,都在这里了!: https://www.leiphone.com/news/201710/sNUJzuAEdSgOOEA4.html
vii. 李开复、马少平、周志华、田渊栋都是怎么看AlphaGo Zero的?: https://www.leiphone.com/news/201710/ghMwmg6CUa80PTiJ.html
viii. 不只是围棋!AlphaGo Zero之后DeepMind推出泛化强化学习算法AlphaZero: https://www.jiqizhixin.com/articles/2017-12-07
ix. UC Berkeley 讲座教授王强:Deep Learning 及 AlphaGo Zero:
1. http://mp.weixin.qq.com/s/FNWlzzAj06fDrT3iNTPPUw,http://mp.weixin.qq.com/s/oosYHyN-AlbPHBVnyIflmgb. 谷歌大脑:
i. 2019年10月,花最少的钱,训超6的机器人:谷歌大脑推出机器人强化学习平台,硬件代码全开源。https://mp.weixin.qq.com/s/Xg8U_QtvI95ABuYImSTqOg
1. https://sites.google.com/view/roboticsbenchmarks/platforms
2. https://arxiv.org/abs/1909.11639
ii. 提出了一种新的算法来解决任何的强化学习算法都需要解决三个主要的问题(才能在所有的游戏中取得出色的表现):处理各种各样的奖励分布,进行长期推理,展开高效的探索。
1. 在本文中,能在几乎所有的雅达利游戏中习得与人类水平相当的策略。
2. Observe and Look Further: Achieving Consistent Performance on Atari,论文地址:https://arxiv.org/pdf/1805.11593.pdf
iii. QT-Opt算法,机器人探囊取物成功率96%,Jeff Dean大赞:https://zhuanlan.zhihu.com/p/38642300
iv. 深度强化学习方面最好的阶段性总结(来自谷歌大脑机器人团队的软件工程师Alex Irpan):https://mp.weixin.qq.com/s/_lmz0l1vP_CQ6p6DdFnHWA,https://www.alexirpan.com/2018/02/14/rl-hard.html
1. 深度强化学习的样本效率可能极低
2. 如果你只关心最终的性能,许多问题更适合用其他方法解决
3. 强化学习通常需要奖励函数
4. 奖励函数设计难
5. 即使奖励函数设计得很好,也很难避免局部最优解
6. 当深度 RL 有效时,它可能过拟合环境中奇怪的模式
7. 即使忽略泛化问题,最终结果也可能不稳定而且难复现
8. 深度 RL 目前还不能即插即用
9. 更容易进行强化学习的属性(非必须):很容易产生近乎无限量的经验(数据更多),问题可以简化成更简单的形式,有一个方法可以将自我博弈引入学习过程,有一种简单的方式来定义一个可学习的、不可竞争的奖励,如果需要定义奖励,至少应该形式丰富。c. DeepMind
i. 2021年7月,超越AlphaZero!DeepMind让AI制霸「元宇宙」,玩转70万个独立游戏。https://mp.weixin.qq.com/s/amd9o7YNaYAV99T7jgSOEg
1. https://deepmind.com/blog/article/generally-capable-agents-emerge-from-open-ended-play
ii. 2021年6月,Acme框架真香!用过一次后,伦敦博士撰文大赞DeepMind强化学习框架。https://mp.weixin.qq.com/s/8bkj8NUVG3a_iOwboBlafQ
1. https://towardsdatascience.com/deepminds-reinforcement-learning-framework-acme-87934fa223bf
iii. 2021年3月,DeepMind提出基于视觉的强化学习模型,十八般兵器对机器人不在话下。https://mp.weixin.qq.com/s/eWn9NRMg-n0X7WwJc99IyQ
1. https://arxiv.org/pdf/2103.09016.pdf
iv. 2020年6月,DeepMind 发布 Acme 框架,用于强化学习算法开发的分布式框架。https://mp.weixin.qq.com/s/LKqVkxYqX7TB8WOLshu-jg
v. 2020年1月,重要理论更新!DeepMind研究表明,大脑使用与AI类似的分布奖励机制。https://mp.weixin.qq.com/s/6Yjvtig52hxfTGTtODcBoA
vi. 2019年5月,DeepMind 综述深度强化学习:智能体和人类相似度竟然如此高!https://mp.weixin.qq.com/s/rhOIWYyPFpJFvg_Esh8Sxw
1. https://www.cell.com/trends/cognitive-sciences/fulltext/S1364-6613(19)30061-0
vii. 2018年9月,DeepMind和Unity双方宣布,将合作开发一个虚拟环境,以供AI用来训练。这个虚拟世界可以实现在真实的物理环境中运行强化学习等机器学习算法。https://mp.weixin.qq.com/s/-CKFli_9b836_twA76fMyg
viii. 2018年9月,Deepmind研究了学习掌握多个而不是一个序列决策任务的问题,提出了PopArt。
1. 背景:强化学习领域在设计能够在特定任务上超越人类表现的算法方面取得了很大进展。这些算法大多用于训练单项任务,每项新任务都需要训练一个全新的智能体。这意味着学习算法是通用的,但每个解决方案并不通用;每个智能体只能解决它所训练的一项任务。
2. 多任务学习中的一个普遍问题是,如何在竞争单个学习系统的有限资源的多个任务需求之间找到平衡。许多学习算法可能会被一系列任务中的某些待解决任务分散注意力,这样的任务对于学习过程似乎更为突出,例如由于任务内奖励的密度或大小的原因。这导致算法以牺牲通用性为代价关注那些更突出的任务。
3. DeepMind建议自动调整每个任务对智能体更新的贡献,以便所有任务对学习动态产生类似的影响,这样做使得智能体在学习玩 57 种不同的 Atari 游戏时表现出了当前最佳性能。令人兴奋的是,Deepmind的方法仅学会一个训练有素的策略(只有一套权重),却超过了人类的中等表现,据deepmind所知,这是单个智能体首次超越此多任务域的人类级别性能。同样的方法还在 3D 强化学习平台 DeepMind Lab 的 30 项任务中实现了当前最佳性能。
4. 论文:Multi-task Deep Reinforcement Learning with PopArt,论文链接:https://arxiv.org/abs/1809.04474
ix. David Silver:http://videolectures.net/rldm2015_silver_reinforcement_learning/, deep_rl_tutorial.pdf
x. DeepMind提出强化学习新算法,教智能体从零学控制:https://mp.weixin.qq.com/s/kk0U7u1KNeKYOZiYnVx39w
1. 对于一些控制类的任务,比如整理桌面或堆叠物体,智能体需要在协调它的模拟手臂和手指的九个关节时,做到三个 W,即如何(how),何时(when)以及在哪里(where),以便正确地移动,最终完成任务。
2. 在任何给定的时间内,需要明确各种可能的运动组合的数量,以及执行一长串正确动作,这些需求引申出一个严肃的问题,这成为强化学习中一个特别有趣的研究领域。
3. 诸如奖赏塑形(reward shaping)、学徒学习(Apprenticeship learning)或从演示中学习(Learning from Demonstration)等技术可以帮助解决这个问题。然而,这些方法依赖于大量与任务相关的知识,而从零开始,通过最少的预先知识学习复杂的控制问题仍然是一个众所周知的挑战。
xi. 2018年11月,DeepMind重磅论文:通过奖励模型,让AI按照人类意图行事。https://mp.weixin.qq.com/s/4yGQtHtMqWlaB7MAsr8T_gd. Dreamer:
i. 2020年3月,谷歌重磅开源RL智能体Dreamer,仅靠图像学习从机器人到Atari的控制策略,样本效率暴增20倍。https://mp.weixin.qq.com/s/3qWN6DjuGUZgCpxH7XF4fg
1. 论文地址:https://arxiv.org/pdf/1912.01603.pdf
2. GitHub 博客地址:https://dreamrl.github.io
3. GitHub 项目地址:https://github.com/google-research/dreamer
ii. 2019年12月,谷歌新智能体Dreamer将亮相NeurIPS 2019,数据效率比前身PlaNet快8个小时。https://mp.weixin.qq.com/s/ms3ZRGt7wx_IsDopKtZAyQe. Google AI 与 DeepMind 合作推出深度规划网络 (PlaNet):https://mp.weixin.qq.com/s/qbBYoLttPAfb3BohGwKF8w
i. 这是一个纯粹基于模型的智能体,能从图像输入中学习世界模型,完成多项规划任务,数据效率平均提升50倍,强化学习又一突破。
ii. 论文:https://danijar.com/publications/2019-planet.pdf
iii. 源代码:https://github.com/google-research/planetf. IMPALA:
i. 2020年3月,谷歌推出分布式强化学习框架SEED,性能“完爆”IMPALA,可扩展数千台机器,还很便宜。https://mp.weixin.qq.com/s/nfsm1v7MuI6mSpRb-rGBBQ
ii. 分布式深度强化学习架构IMPALA,让一个Agent学会多种技能:IMPALA- Scalable Distributed Deep-RL with Importance Weighted Actor-Learner Architectures .pdfg. 2021年2月,李飞飞团队从动物身上get AI新思路,提出RL计算框架,让机器在复杂环境学习和进化。https://mp.weixin.qq.com/s/2AnmhRNYhJrG6J6WHnrWpg
i. https://arxiv.org/abs/2102.02202h. 2020年4月,谁说RL智能体只能在线训练?谷歌发布离线强化学习新范式,训练集相当于200多个ImageNet。https://mp.weixin.qq.com/s/byJAaD2cspiHzjazKb4Cxw
i. 谷歌的这项最新研究从优化角度,为我们提供了离线强化学习研究新思路,即鲁棒的 RL 算法在足够大且多样化的离线数据集中训练可产生高质量的行为。该论文的训练数据集与代码均已开源。
ii. 论文链接:https://arxiv.org/pdf/1907.04543.pdf
iii. 项目地址:https://github.com/google-research/batch_rli. Dopamine:
i. 2018年8月,谷歌发布博客介绍其最新推出的强化学习新框架 Dopamine,该框架基于 TensorFlow,可提供灵活性、稳定性、复现性,以及快速的基准测试。
1. 开源地址:https://github.com/google/dopaminej. 2018年7月,用强化学习训练机械臂,从模拟到现实。https://mp.weixin.qq.com/s/QGT-Sq9ACVR1bbsLmmt7HA
Salesforce:
a. 2021年9月,一块V100运行上千个智能体、数千个环境,这个「曲率引擎」框架实现RL百倍提速。https://mp.weixin.qq.com/s/LjJ5b1gtt8-DFqihaTZ2hwUber
a. 2018年5月,Uber AI Lab 开源了一组进化算法代码,它的特点是可以高速(同时也更廉价地)进行进化策略研究。训练神经网络玩 Atari 游戏的时间可以从原来在 720 个 CPU 组成的集群上花费 1 个小时,到现在在一台桌面级电脑上只需要 4 个小时。https://eng.uber.com/accelerated-neuroevolution/
i. Deep Neuroevolution_Genetic Algorithms Are a Competitive Alternative for Training Deep Neural Networks for Reinforcement Learning.pdf
b. Uber AI Lab 从多个角度展现了进化算法解决强化学习问题的能力,也展现了进化策略 ES(evolution strategies)与梯度下降之间的联系。这些研究成果非常精彩、给人启迪。但这些成果消耗了相当多的计算资源。
i. https://mp.weixin.qq.com/s/misLn2NVegt2on_nt2UhKQ
ii. 五篇论文:
1. On the Relationship Between the OpenAI Evolution Strategy and Stochastic Gradient Descent.pdf
2. Deep Neuroevolution_Genetic Algorithms Are a Competitive Alternative for Training Deep Neural Networks for Reinforcement Learning.pdf
3. Safe Mutations for Deep and Recurrent Neural Networks through Output Gradients.pdf
4. ES Is More Than Just a Traditional Finite-Difference Approximator.pdf
5. Improving Exploration in Evolution Strategies for Deep Reinforcement Learning via a Population of Novelty-Seeking Agents.pdfOpenAI
a. 2018年8月,提出一种新的强化学习模型训练方式,以agent的“好奇心”作为内在奖励函数,在训练中无需外部奖励,泛化性好,经过54种环境测试,效果拔群。
i. 背景:强化学习模型往往依赖对外部奖励机制的精心设计,在模型训练成本控制和可扩展性上都存在局限。
ii. 论文地址:https://pathak22.github.io/large-scale-curiosity/resources/largeScaleCuriosity2018.pdf
iii. Github相关资源:https://github.com/openai/large-scale-curiosity
b. 2018年7月,用强化学习训练机械臂,从模拟到现实。https://mp.weixin.qq.com/s/MaTDw0IZzpKGtq-ygVpgjw
c. OpenAI 近日发布了完整版游戏强化学习研究平台——Gym Retro。在本次发布之后,OpenAI 公开发布的游戏数量将从大约 70 个雅达利和 30 个世嘉游戏增加到了 1000 多个游戏,其中包括对任天堂 Game boy 等各种模拟器的支持。此外,OpenAI 还将发布用于向 Gym 平台添加新游戏的工具。https://github.com/openai/retro/tree/develop
d. 2017年,OpenAI提出层级强化学习,给长序列动作学习带来新的曙光:https://www.leiphone.com/news/201710/TnK0EOljSWMCrbG6.html微软:
a. 2020年4月,超越99.9%人类玩家,微软专业十段麻将AI论文细节首次公布。https://mp.weixin.qq.com/s/-3BwCDfjKWeNz_FGLECg0g
i. 一直以来,麻将都因其复杂的出牌、得分规则和丰富的隐含信息,被视为 AI 研究中极具挑战性的领域。微软亚洲研究院副院长刘铁岩曾表示:”可以说 Dota 这类游戏更「游戏」,而麻将这类棋牌游戏更「AI」”。
ii. Suphx 代表着 AI 系统在麻将领域取得的最好成绩,它也是首个在国际知名专业麻将平台「天凤」上荣升十段的 AI 系统,其实力超越了该平台与之对战过的 99.9% 的人类选手。
iii. https://arxiv.org/abs/2003.13590
b. 【强化学习中的可靠性问题】如何得到稳定可靠的强化学习算法?微软两篇顶会论文带来安全的平滑演进。https://mp.weixin.qq.com/s/S7xjoc43GhPMZBtv6lnWFQ
i. 《Reinforcement Learning Algorithm Selection》,ICLR 2018,https://arxiv.org/abs/1701.08810
ii. 《Safe Policy Improvement with Baseline Bootstrapping》,ICML 2019,https://arxiv.org/abs/1712.06924百度
a. 净利润大涨三倍、股价飙升,百度新上了一个秘密武器:强化学习:https://mp.weixin.qq.com/s/kSQocM0TWK2Mgpgo4CPBrg
i. 这一季度里,百度首次在广告系统凤巢里,部署了强化学习技术,这是更精准营销的原因。他说,这达到了一个工程上的新里程碑。陆奇介绍说,作为机器学习的一个分支,强化学习有三个重要的特点:
1. 一是不需要标注的数据,可以直接读取实际活动中的浏览、点击、转化等等数据,因此更加高效。
2. 二是可以利用更多数据信号,也就可以更好地提升经济效益和广告质量。
3. 三是可以实现“在线学习”,不用先离线训练、再上线发布,能加快开发的速度。阿里
a. 2018年,阿里开放了一本描述强化学习在实践中应用的书籍《强化学习在阿里的技术演进与业务创新》,reinforcement_learning.pdf
i. 这本书重点描述了阿里巴巴在推动强化学习输出产品及商业化的实践过程。例如在在搜索场景中对用户的浏览购买行为进行 MDP 建模、在推荐场景中使用深度强化学习与自适应在线学习帮助每⼀个用户迅速发现宝贝、在智能客服中赋予阿里⼩蜜这类的客服机器⼈对应的决策能力、在广告系统中实现了基于强化学习的智能调价技术,根据顾客的当前状态去决定如何操作调价。
ii. 高T点评:类似的思路,2014年时,我们在搜索推荐中也用到过了,我们用了online learning,不管是RL还是ol,本质都是去探索并不断拓展用户未知的新兴趣点。快手:
a. 2021年6月,快手开源斗地主AI,入选ICML,能否干得过「冠军」柯洁?https://mp.weixin.qq.com/s/Q_Dd4JKRg0JNy9fqOZZPtQ
i. 论文链接:https://arxiv.org/abs/2106.06135
ii. GitHub 链接:https://github.com/kwai/DouZero
iii. 在线演示:(电脑打开效果更佳;如果访问太慢,可从 GitHub 上下载并离线安装:https://github.com/datamllab/rlcard-showdown)
b. 2021年2月,设计简单有效的强化学习探索算法,快手有新思路。https://mp.weixin.qq.com/s/1EXp3OzNkTgJbcyDNc_DPA
i. 论文:https://openreview.net/forum?id=MtEE0CktZht
ii. 代码:https://github.com/daochenzha/rapid
c. 2020年8月,首家强化学习大规模落地工业应用,快手是如何做到的?https://mp.weixin.qq.com/s/F6mGZaE4Du2igFq2VFeU8A
i.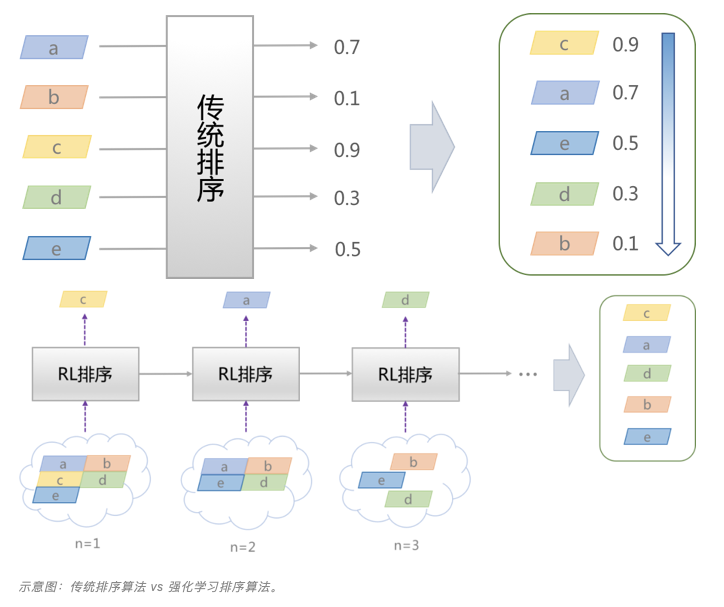
Facebook
a. 2021年10月,强化学习从未如此方便!Facebook发布沙盒MiniHack,内置史上最难游戏。https://mp.weixin.qq.com/s/WS1YusQzcOhW-RkHDZFMzA
i. https://ai.facebook.com/blog/minihack-a-new-sandbox-for-open-ended-reinforcement-learning/
ii. 强化学习沙盒MiniHack
b. 2020年7月,人类玩德州扑克也扑街了?Facebook开发玩德州扑克的AI,大比分击败顶尖人类选手!https://mp.weixin.qq.com/s/zFXLkhVaflkbCxapcaJSGg
i. https://arxiv.org/pdf/2007.13544.pdf
ii. https://venturebeat.com/2020/07/28/facebook-develops-ai-algorithm-that-learns-to-play-poker-on-the-fly/
c. 2020年2月,Facebook创建Habitat,一个极具世界真实感的模拟系统。https://mp.weixin.qq.com/s/oY_uVyKFljqq-1r5OgflHw
i. Facebook创建的Habitat可以构建足够真实感的虚拟环境,以至于AI在导航中学习到的东西也可以应用于现实世界。
d. 2019年12月,Facebook成功打破纸牌游戏Hanabi的AI系统得分纪录。https://mp.weixin.qq.com/s/DSHPu5V-_WWdsrkJkmSGJg,https://mp.weixin.qq.com/s/dlA97ICKR01uJueC33my5w
i. 通过将搜索技术与深度强化学习结合起来实现了这一壮举。搜索算法把一个代理之外的所有代理执行商定的策略将问题转换为单个代理设置,这是一种被称为“蓝图”(blueprint)的强化学习算法。根据一篇题为“通过在合作部分可观察的游戏中搜索来改进策略” 的论文,这一算法允许搜索代理“将其他代理的已知策略作为环境的一部分进行处理,并基于其他行为来维护对隐藏信息的信念。”
ii. Facebook AI的研究人员制造出一个机器人,可以在一款需要团队作战的游戏Hanabi中获得高分,这表明AI可以与其他机器人或者人类合作来达到目标。
e. 2019年2月,Facebook人工智能研究所(FAIR)的ELF OpenGo预训练模型与代码已经开源。https://ai.facebook.com/blog/open-sourcing-new-elf-opengo-bot-and-go-research/,https://research.fb.com/facebook-open-sources-elf-opengo/,https://github.com/pytorch/ELF
i. 田渊栋等人重现了DeepMind围棋程序AlphaZero,这是超级围棋AI的首次开源。OpenGo的最新版本使用2000块GPU训练了15天实现了超人类的性能。在只有一块GPU的情况下,OpenGo在与4个人类排名前30的的职业选手进行比赛时,在慢棋赛中取得了20比0全胜的战绩
f. 2018年11月,从Zero到Hero,OpenAI重磅发布深度强化学习资源。https://mp.weixin.qq.com/s/781fVvKr4yuq4q2GI1Y1gA
g. 2018年11月,Facebook 开源了适合大规模产品和服务的强化学习平台 Horizon,这是第一个使用强化学习在大规模生产环境中优化系统的开源端到端平台。Horizon 包含的工作流程和算法建立在开放的框架上(PyTorch 1.0、Caffe2、Spark),任何使用 RL 的人都可以访问 Horizon。去年,Facebook 内部已经广泛应用 Horizon,包括帮助个性化 M suggestions、提供更有意义的通知、优化流视频质量。
i. GitHub 地址:https://github.com/facebookresearch/Horizon,原文链接:https://code.fb.com/ml-applications/horizon/,中文参考:https://mp.weixin.qq.com/s/cDfuasM7CzQxIefjFNNt6QSea:
a. 2021年11月,100万帧数据仅1秒!AI大牛颜水成团队强化学习新作,代码已开源。https://mp.weixin.qq.com/s/YusIuUtvTwoskNRV_OV7iw
i. 颜水成团队公开了最新的强化学习训练环境引擎,256核CPU的运行速度直接达到1秒1百万帧!就连笔记本上的i7-8750H也能有5万帧每秒。
ii. https://github.com/sail-sg/envpool
iii. GTC 2021演讲:https://events.rainfocus.com/widget/nvidia/nvidiagtc/sessioncatalog/session/1630239583490001Z5dE加州大学伯克利分校
a. 2021年8月,替代离线RL?Transformer进军决策领域,「序列建模」成关键。https://mp.weixin.qq.com/s/wNL-QhzfAt3TVYZwOqgNqw
i. 论文链接:https://arxiv.org/pdf/2106.01345.pdf
ii. GitHub 链接:https://github.com/kzl/decision-transformer
b. 2018年4月,用强化学习教生活在模拟器中的机器人通过模仿人类,学会武打、跑酷、杂技等复杂技能。https://mp.weixin.qq.com/s/Ovwv25nJtjnEI0wmeSnaJw
i. Example-Guided Deep Reinforcement Learning of Physics-Based Character Skills, https://arxiv.org/pdf/1804.02717.pdf斯坦福大学:
a. 2021年10月,李飞飞团队创建深度学习「游乐场」:AI也在自我进化,细思极恐!https://mp.weixin.qq.com/s/ZoL2MS8I8SuipgU2U-GUCg
i. 在李飞飞的带领下,斯坦福大学的研究小组创建了一个计算机模拟的「游乐场」——DERL(深度进化强化学习),其中被称为「Unimals」(通用动物)的智能体在经历不断变异和自然选择。论文刊登在《自然通讯》杂志上。研究结果显示,虚拟生物的身体形状影响了它们学习新任务的能力,在更具挑战性的环境中学习和进化的形态,或者在执行更复杂的任务时,比那些在更简单的环境中学习和进化的形态学习进化得更快、更好。在这项研究中,具有最成功的形态的Unimal也比前几代更快地掌握了任务,尽管它们最初的基线智力水平与前代相同。也就是说,「具身化」是智能进化的关键。
ii. https://www.nature.com/articles/s41467-021-25874-z
iii. https://hai.stanford.edu/news/how-bodies-get-smarts-simulating-evolution-embodied-intelligence
b. 2020年7月,无惧雨雪风霜?斯坦福找到一种更适应动态环境的强化学习方法。https://mp.weixin.qq.com/s/RxM7VH8Au8nER_hKONbUew
i. 研究人员最近设计了一种方法,能处理那些会随时间变化的数据和环境,性能优于一些领先的强化学习方法,它被命名为LILAC(Lifelong Latent Actor-Critic)。这一方法使用了潜在变量模型和最大熵策略,以此利用过去的经验,在动态环境中获得更好的采样效率和性能。德州农工大学
a. 2019年10月,卡牌游戏八合一,华人团队开源强化学习研究平台RLCard。https://mp.weixin.qq.com/s/jqW8YcezhPqXbDuYU6Y4Nw
i. Github:https://github.com/datamllab/rlcard,官方网站:http://rlcard.org,论文:https://arxiv.org/abs/1910.04376清华大学:
a. 2020年4月,清华大学深度强化学习框架“天授”,开源后已获900星标。https://mp.weixin.qq.com/s/6ppS1jjslDtCsK1yj4wudA
i. 清华大学人工智能研究院基础理论研究中心发布了深度强化学习框架“天授”。这也是继“珠算”可微分概率编程库之后,该中心推出的又一个面向复杂决策任务的编程库。
ii. https://github.com/thu-ml/tianshou北京大学:
a. 2021年8月,北大教授用《星际争霸II》玩警察抓小偷? 对抗性代理强化学习模型教AI如何逃跑!https://mp.weixin.qq.com/s/aSc9TrsN_mL3XvOn910ZAQ
i. 论文地址:https://arxiv.org/pdf/2108.11010.pdf
ii. 项目地址:https://github.com/xunger99/SAAC-StarCraft-Adversary-Agent-Challenge综合性及其他
a. 2021年11月,它让DeepMind、Meta等巨头深陷其中:一文回顾2021年强化学习历程。https://mp.weixin.qq.com/s/49zepV0ySGHuZ6Bm0eZbZQ
i. https://analyticsindiamag.com/what-happened-in-reinforcement-learning-in-2021/
ii.
b. 2021年11月,深度强化学习探索算法最新综述,近200篇文献揭示挑战和未来方向。https://mp.weixin.qq.com/s/_-WSoeOqXMhR7S0PtyYixQ
i. https://arxiv.org/pdf/2109.06668.pdf
ii.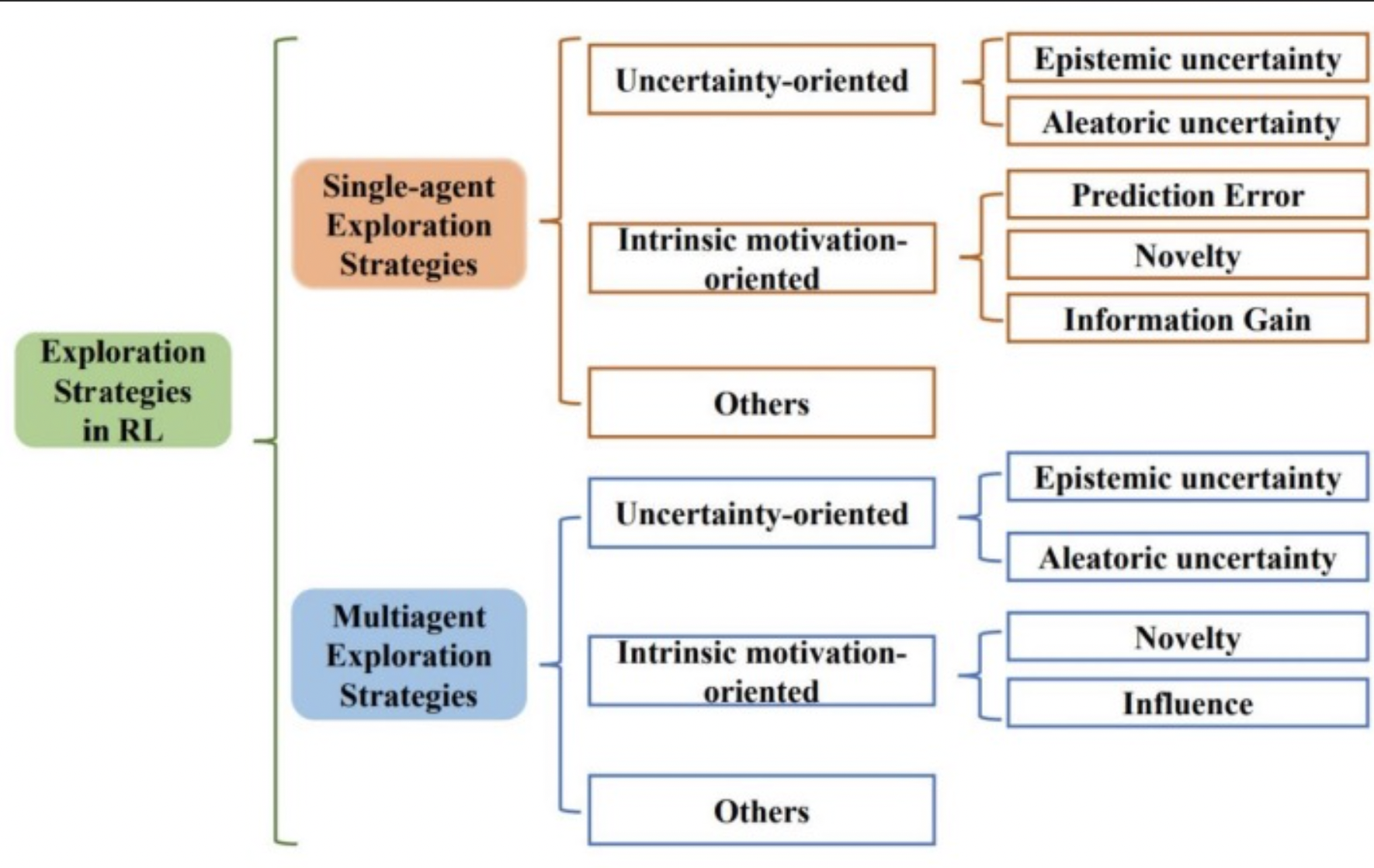
c. 2021年8月,公开反驳!数据科学家直指DeepMind,“强化学习无法实现通用人工智能”。https://mp.weixin.qq.com/s/bi0sUBfyZ1YS7IpEyMjbNg
d. 2021年6月,实现AGI,强化学习就够了?Sutton、Silver师徒联手:奖励机制足够实现各种目标。https://mp.weixin.qq.com/s/XTNyLjZ9KfdtHY4Omb9_4w
i. 《Reward is enough》:https://www.sciencedirect.com/science/article/pii/S0004370221000862
e. 2020年12月,一文看尽系列:分层强化学习(HRL)经典论文全面总结。https://mp.weixin.qq.com/s/Uc1Qsh3BG1PEe4roVqpkYQ
f. 2019年10月,八千字长文深度解读,迁移学习在强化学习中的应用及最新进展。https://mp.weixin.qq.com/s/Rj55EoopzlR71DZ5XrvH_w
i.
g. 2019年6月,论文Modern Deep Reinforcement Learning Algorithms,作者:Sergey Ivanov,Alexander D’yakonov
i. 链接:https://arxiv.org/pdf/1906.10025v1
h. 2018年10月,综述文章《深度强化学习》,Deep Reinforcement Learning,论文地址:https://arxiv.org/abs/1810.06339
i. 2018年7月,关于强化学习的不足的一些综述和分析:https://mp.weixin.qq.com/s/5eWIo4CguvgHjX84Jpibuw,https://mp.weixin.qq.com/s/YAHc_s7qeKbJ8UtiMjy9hQ
j. ICML2018:63篇强化学习论文精华解读:https://mp.weixin.qq.com/s/78fAbPgEv01iBthWimYUqg,https://medium.com/@jianzhang_23841/a-comprehensive-summary-and-categorization-on-reinforcement-learning-papers-at-icml-2018-787f899b14cb
k. 延迟奖励问题:
i. 在强化学习中,延迟奖励的存在会严重影响性能,主要表现在随着延迟步数的增加,对时间差分(TD)估计偏差的纠正时间的指数级增长,和蒙特卡洛(MC)估计方差的指数级增长。针对这一问题,来自奥地利约翰开普勒林茨大学 LIT AI Lab 的研究者提出了一种基于返回值分解的新方法 RUDDER。实验表明,RUDDER 的速度是 TD、MC 以及 MC 树搜索(MCTS)的指数级,并在特定 Atari 游戏的训练中很快超越 rainbow、A3C、DDQN 等多种著名强化学习模型的性能。
ii. 论文链接:https://arxiv.org/abs/1806.07857
l. 2018年3月,模拟机器人的逆天成长:论进化策略在强化学习中的应用。https://mp.weixin.qq.com/s/BPtGm25GI4j-3Q1_M8sgbA
i. OpenAI Gym:https://gym.openai.com/docs/
ii. dgriff777 的双足步行者:https://github.com/dgriff777
iii. CMA-ES:https://arxiv.org/abs/1604.00772
iv. OpenAI ES:https://blog.openai.com/evolution-strategies/
v. 近端策略优化 PPO:https://arxiv.org/abs/1707.06347
vi. MIT 开源赛车:https://mit-racecar.github.io/
vii. estool:https://github.com/hardmaru/estool/
viii. pybullet:https://github.com/bulletphysics/bullet3/tree/master/examples/pybullet/gym/pybullet_envs/bullet
ix. BipedalWalkerHardcore-v2:https://gym.openai.com/envs/BipedalWalkerHardcore-v2/
x. OpenAI Roboschool:https://blog.openai.com/roboschool/
m. 分布式深度强化学习架构IMPALA,让一个Agent学会多种技能:http://mp.weixin.qq.com/s/1zJyw67B6DqsHEJ3avbsfQ,IMPALA- Scalable Distributed Deep-RL with Importance Weighted Actor-Learner Architectures .pdf
n. Importance Weighted Actor-Learner Architectures(IMPALA):AI 系统快速播放一系列电子游戏,并从一组“玩家”中提取训练信息并传递给一组“学习者”。https://mp.weixin.qq.com/s/3HIxMMAVnGggqAPC5D9BOQ,https://thenextweb.com/artificial-intelligence/2018/02/08/deepmind-taught-ai-how-to-multitask-using-video-games/
i. 就像多名玩家(30名或以上)共用一个“博格”(borg)大脑,一起摸索《雷神之锤》的玩法,共享所有经验。比其他算法提高 10 倍效率,还能同时玩多个游戏
o. 加州大学欧文分校的一个研究小组,发布了基于强化学习的魔方复原AI。这个AI 完全不需要依靠人类的知识来解魔方,有速度有准度。https://mp.weixin.qq.com/s/oYPpyiHHM-__D-eQHKipMw
p. Nature论文This Robot Adapts Like Animals.pdf,提出一种智能试错法算法,算法允许机器人快速适应破坏,完全不需要自我诊断或是提前准备应急措施。(基于一个六组机器人和一个机械手臂)
i. 与传统强化学习(RL)方法相比,论文中的方法更加有效率,机器人上只需要花上几分钟和几次物理试验,而 RL 算法通常必须进行数百次测试才能学会如何完成任务。机器人有一个(simulated childhood),在这里它学习了移动身体的不同方式,在经过几次测试和大约两分钟后就可以适应。
ii. 本期论文跟之前的研究有两个主要区别:
1. 机器人不需要知道损伤是什么,它只需要一种方法来衡量其性能;
2. 没有一个大型资料库来指导,遭受各种类型的损害之后应该怎么做。
q. 2019年1月,聚焦强化学习,AAAI 2019杰出论文公布:CMU、斯坦福等上榜。https://mp.weixin.qq.com/s/47NyLLb0cyUD36uotsqmgQ
r. 2019年2月,效率提高50倍!谷歌提出从图像中学习世界的强化学习新方法。https://mp.weixin.qq.com/s/dlOFM7LuOF2npDP_EaITvg
s. 2018年8月,强化学习实验里到底需要多少个随机种子的严格证明。https://mp.weixin.qq.com/s/laINqzOKg2KFJBsQ-C0SsA
i. http://amid.fish/reproducing-deep-rl
ii. https://arxiv.org/abs/1806.08295
t. 2018年11月,CoRL2018最佳论文:抓取新物体成功率96%的深度强化学习机械臂:https://mp.weixin.qq.com/s/A4JZaRkx6Sxx7CdQRQaT4w
u. 2018年11月,超越DQN和A3C:深度强化学习领域近期新进展概览。https://mp.weixin.qq.com/s/GUyZ0U5_JlXCI-5mO796SA
3 元学习(Meta Learning)
元学习的概念:实现通用人工智能的关键。Meta Learning(元学习)或者叫做 Learning to Learn(学会学习)已经成为继Reinforcement Learning(增强学习)之后又一个重要的研究分支(以后仅称为Meta Learning)。对于人工智能的理论研究,呈现出了Artificial Intelligence –> Machine Learning –> Deep Learning –> Deep Reinforcement Learning –> Deep Meta Learning 这样的趋势。https://www.leiphone.com/news/201708/tSXB6oo1mdnbKvkd.html,https://zhuanlan.zhihu.com/p/27629294,https://zhuanlan.zhihu.com/p/27696130
a. 基于记忆Memory的方法,基本思路:既然要通过以往的经验来学习,那么是不是可以通过在神经网络上添加Memory来实现呢?
b. 基于预测梯度的方法,基本思路:既然Meta Learning的目的是实现快速学习,而快速学习的关键一点是神经网络的梯度下降要准,要快,那么是不是可以让神经网络利用以往的任务学习如何预测梯度,这样面对新的任务,只要梯度预测得准,那么学习得就会更快了?
c. 利用Attention注意力机制的方法,基本思路:人的注意力是可以利用以往的经验来实现提升的,比如我们看一个性感图片,我们会很自然的把注意力集中在关键位置。那么,能不能利用以往的任务来训练一个Attention模型,从而面对新的任务,能够直接关注最重要的部分。
d. 鉴LSTM的方法,基本思路:LSTM内部的更新非常类似于梯度下降的更新,那么,能否利用LSTM的结构训练出一个神经网络的更新机制,输入当前网络参数,直接输出新的更新参数?这个想法非常巧妙。
e. 面向RL的Meta Learning方法,基本思路:既然Meta Learning可以用在监督学习,那么强化学习上又可以怎么做呢?能否通过增加一些外部信息的输入比如reward,之前的action来实现?
f. 通过训练一个好的base model的方法,并且同时应用到监督学习和强化学习,基本思路:之前的方法都只能局限在或者监督学习或者增强学习上,能不能搞个更通用的呢?是不是相比finetune学习一个更好的base model就能work?
g. 利用WaveNet的方法,基本思路:WaveNet的网络每次都利用了之前的数据,那么是否可以照搬WaveNet的方式来实现Meta Learning呢?就是充分利用以往的数据呀?
h. 预测Loss的方法,基本思路:要让学习的速度更快,除了更好的梯度,如果有更好的loss,那么学习的速度也会更快,因此,是不是可以构造一个模型利用以往的任务来学习如何预测Loss呢?OpenAI:
a. META LEARNING SHARED HIERARCHIES.pdf
b. 2018年4月,OpenAI提出新型元学习方法EPG,调整损失函数实现新任务上的快速训练。https://mp.weixin.qq.com/s/AhadWUjtgsFmb8uTylTvqg
c. 2018年3月,OpenAI 发表了一篇博客介绍了自己新设计的元学习算法「Reptile」。算法的结构简单,但却可以同时兼顾单个样本和大规模样本的精确学习。OpenAI 甚至还在博客页面上做了一个互动界面,可以直接在四个方框里画出训练样本和要分类的样本,算法可以立即学习、实时更新分类结果。
i. 论文地址: https://d4mucfpksywv.cloudfront.net/research-covers/reptile/reptile_update.pdf
ii. 开源地址: https://github.com/openai/supervised-reptileMIT:
a. 2020年5月,MIT科学家用AI设计「好奇心」算法:基于元学习探索奇妙世界。https://mp.weixin.qq.com/s/zir6yGCweyEpYAWYXThJgg
i. 孩子们通过好奇心解锁世界。相比之下,把计算机放到新环境中通常会卡顿。为此,研究人员尝试将好奇心编码到他们的算法中,希望智能体在探索的驱动下,能够更好地了解他所处的环境。
ii. https://www.csail.mit.edu/news/automating-search-entirely-new-curiosity-algorithms斯坦福:
a. 2020年11月,李飞飞点赞「ARM」:一种让模型快速适应数据变化的元学习方法。https://mp.weixin.qq.com/s/I5M_2wZcpoz6_AQtcjQAJg
i. 论文地址:https://arxiv.org/abs/2007.02931
ii. 博客地址:https://ai.stanford.edu/blog/adaptive-risk-minimization/
iii. 开源地址:https://github.com/henrikmarklund/armUber:
a. 2018年4月,Uber AI论文:利用反向传播训练可塑神经网络,生物启发的元学习范式.https://mp.weixin.qq.com/s/dmRdp2oMn0vGukclJSVZDg综述及其他:
a. 2020年5月,CVPR 2020 | 元学习人脸识别框架详解。https://mp.weixin.qq.com/s/h1Tqbjj_1D67Hs4jWcAr5A
i. https://arxiv.org/abs/2003.07733
b. 2020年4月,何为因?何为果?图灵奖得主Bengio有一个解。https://mp.weixin.qq.com/s/rFHejjK4m55UzvZYqtCuqQ
i. Bengio提出使用一个元学习目标来学习如何将获得的知识模块化,并找到其中的因果关系。
ii. 论文链接:https://openreview.net/forum?id=ryxWIgBFPS
c. 2019年12月,四篇论文,一窥元学习的最新研究进展。https://mp.weixin.qq.com/s/F1MhWTUUdT3qpuZOmKPVbw
d. 2019年8月,图像样本不够用?元学习帮你解决。https://mp.weixin.qq.com/s/xi-u3A1yjsLZb6bFzQudGg
i. https://blog.sicara.com/meta-learning-for-few-shot-computer-vision-1a2655ac0f3a
e. 2018年4月,ICLR 2018最佳论文:基于梯度的元学习算法,可高效适应非平稳环境。https://openreview.net/pdf?id=Sk2u1g-0-
i. 在非平稳环境中根据有限的经验连续地学习和适应对于发展通用人工智能而言至关重要。在本文中,将连续适应的问题在 learning-to-learn 框架中重构。我们开发了一种简单的基于梯度的元学习算法,该算法适用于动态变化和对抗性的场景。
ii. 此外,还设计了一种新的多智能体竞争环境 RoboSumo,并定义了迭代适应的游戏,用于测试连续适应的多个层面。研究表明,在少样本机制下,相比反应性的基线算法,通过元学习可以得到明显更加高效的适应性智能体。对智能体集群的学习和竞争实验表明元学习是最合适的方法。
4 迁移学习(Transfer Learning)
综述及其他
a. 2020年12月,谷歌:引领ML发展的迁移学习,究竟在迁移什么?https://mp.weixin.qq.com/s/RJivQh3SiL8KbhkyERTu4Q
b. 清华大学:2018年9月,智能技术与系统国家重点实验室近期发表的深度迁移学习综述,首次定义了深度迁移学习的四个分类,包括基于实例、映射、网络和对抗的迁移学习方法,并在每个方向上都给出了丰富的参考文献。
i. A Survey on Deep Transfer Learning,论文地址:https://arxiv.org/pdf/1808.01974v1.pdf迁移学习——Fine-tune。https://blog.csdn.net/u013841196/article/details/80919857
a.
2020年5月,仅需少量视频观看数据,即可精准推断用户习惯:腾讯、谷歌、中科大团队提出迁移学习架构PeterRec。https://mp.weixin.qq.com/s/PmVhAthYxiUspWic5Klpog
a. https://arxiv.org/pdf/2001.04253.pdf
5 预训练模型(含大模型)
Switch Transformer:
a. 2021年1月,1.6万亿参数的语言模型:谷歌大脑提出Switch Transformer,预训练速度可达T5的7倍。https://mp.weixin.qq.com/s/PHitKydbEXsJRGb-TwA4zg
b. 论文链接:https://arxiv.org/pdf/2101.03961.pdf
c. 代码链接:https://github.com/tensorflow/mesh/blob/master/mesh_tensorflow/transformer/moe.pyMegatron Turing-NLG(5300亿参数)
a. 2021年10月,5300亿NLP模型“威震天-图灵”发布,由4480块A100训练,微软英伟达联合出品。https://mp.weixin.qq.com/s/XSB3kPIeAYQDXiPWbJtWCQ,https://mp.weixin.qq.com/s/59DelHwrmGGGxHmF5Idv-g
i. https://www.microsoft.com/en-us/research/blog/using-deepspeed-and-megatron-to-train-megatron-turing-nlg-530b-the-worlds-largest-and-most-powerful-generative-language-model/T-ULRv5(22 亿参数)
a. 2021年9月,百倍训练效率提升,微软通用语言表示模型T-ULRv5登顶XTREME。https://mp.weixin.qq.com/s/Nj_3ybzDSOzjG66wmLKXEw
i. 微软打造的最新图灵通用语言表示模型 T-ULRv5 模型再次成为 SOTA 模型,并在 Google XTREME 公共排行榜上位列榜首。这项研究由 Microsoft Turing 团队和 Microsoft Research 合作完成,T-ULRv5 XL 模型具有 22 亿参数,以 1.7 分的平均分优于当前性能第二的模型(VECO)。Turing-NLG:
a. 2020年2月,微软发布史上最大AI模型:170亿参数横扫各种语言建模基准,将用于Office套件。 https://mp.weixin.qq.com/s/hbJ3ddACcT8D12cR2GKg9w
i. 简称T-NLG,是一个基于Transformer的生成语言模型,可以生成单词来完成开放式的文本任务,比如回答问题,提取文档摘要等等。
b. 2018年12月,自 BERT 打破 11 项 NLP 的记录后,可应用于广泛任务的 NLP 预训练模型就已经得到大量关注。最近微软推出了一个综合性模型,它在这 11 项 NLP 任务中超过了 BERT。目前名为「Microsoft D365 AI & MSR AI」的模型还没有提供对应的论文与项目地址,因此它到底是不是一种新的预训练方法也不得而知。在「Microsoft D365 AI & MSR AI」模型的描述页中,新模型采用的是一种多任务联合学习。因此所有任务都共享相同的结构,并通过多任务训练方法联合学习。此外,这 11 项任务可以分为 4 类,即句子对分类 MNLI、QQP、QNLI、STS-B、MRPC、RTE 和 SWAG;单句子分类任务 SST-2、CoLA;问答任务 SQuAD v1.1;单句子标注任务(命名实体识别)CoNLL-2003 NER。T5:
a. 2019年10月,谷歌T5模型刷新GLUE榜单,110亿参数量,17项NLP任务新SOTA。https://mp.weixin.qq.com/s/YOMWNV5BMI9hbB6Nr_Qj8w
i. 2018 年,谷歌发布基于双向 Transformer 的大规模预训练语言模型 BERT,为 NLP 领域带来了极大的惊喜。而后一系列基于 BERT 的研究工作如春笋般涌现,用于解决多类 NLP 任务。预训练模型也成为了业内解决 NLP 问题的标配。今日,谷歌又为大家带来了新的惊喜,新模型在 17 个 NLP 任务中都达到了 SOTA 性能。
ii. 论文链接:https://arxiv.org/abs/1910.10683,Github 链接:https://github.com/google-research/text-to-text-transfer-transformermT5:https://arxiv.org/pdf/2010.11934.pdf
a. 2020年10月,谷歌130亿参数多语言模型mT5重磅来袭,101种语言轻松迁移。https://mp.weixin.qq.com/s/LTGTzN-8vA79GMczTmMbUQM2M-100:https://github.com/pytorch/fairseq/tree/master/examples/m2m_100
a. 2020年10月,150亿参数大杀器!Facebook开源机器翻译新模型,https://mp.weixin.qq.com/s/zcU46m0xYggd-56w8gZY7ALaMDA:对话应用程序的语言模型,相比BERT的最大优势,是可以自然对话
a. https://blog.google/technology/ai/lamda/MUM:多任务统一模型,特色是多模态,用谷歌的话就是“比BERT强了1000倍”
a. https://blog.google/products/search/introducing-mum/BaseLM(1370 亿参数)
a. 2021年9月,全新instruction调优,零样本性能超越小样本,谷歌1370亿参数新模型比GPT-3更强。https://mp.weixin.qq.com/s/q2gVB4OPWL0RASFvU-KQuA
i. Finetuned LANguage Net,或 FLAN
ii. 论文地址:https://arxiv.org/pdf/2109.01652.pdf
ii. GitHub 地址:https://github.com/google-research/flan.
iv. 在 NLP 领域,pretrain-finetune 和 prompt-tuning 技术能够提升 GPT-3 等大模型在各类任务上的性能,但这类大模型在零样本学习任务中的表现依然不突出。为了进一步挖掘零样本场景下的模型性能,谷歌 Quoc Le 等研究者训练了一个参数量为 1370 亿的自回归语言模型 Base LM,并在其中采用了全新的指令调整(instruction tuning)技术,结果显示,采用指令调整技术后的模型在自然语言推理、阅读理解和开放域问答等未见过的任务上的零样本性能超越了 GPT-3 的小样本性能。BERT(3亿参数):
a. Google:
i. 2020年12月,谷歌搜索的灵魂!BERT模型的崛起与荣耀。https://mp.weixin.qq.com/s/nI7sUGQbFc4Nsh53Xgux8w
ii. 2020年11月,谷歌搜索:几乎所有的英文搜索都用上BERT了。https://mp.weixin.qq.com/s/qpPpQTYGBZzqa9nG8Et-oA
iii. 2020年3月,Google发布24个小型BERT模型,直接通过MLM损失进行预训练。https://mp.weixin.qq.com/s/s0ysFH4CRvsHY1Gp3b4DPQ
1. https://storage.googleapis.com/bert_models/2020_02_20/all_bert_models.zip
iv. 2018年11月谷歌终于开源BERT代码:3 亿参数量,全面解读。https://www.jiqizhixin.com/articles/2018-11-01-9,2018年10月,谷歌 AI 的一篇NLP论文引起了社区极大的关注与讨论,被认为是 NLP 领域的极大突破。其性能超越许多使用任务特定架构的系统,在机器阅读理解顶级水平测试SQuAD1.1中,论文中的BERT模型刷新了 11 项 NLP 任务的当前最优性能记录。https://mp.weixin.qq.com/s/W0iDs3jYkYONiZwJ8vzYwA
1. 论文:https://arxiv.org/pdf/1810.04805.pdf
2. 开源地址:https://github.com/google-research/bert
3. 介绍博客和报道:https://www.zhihu.com/question/298203515,https://www.reddit.com/r/MachineLearning/comments/9nfqxz/r_bert_pretraining_of_deep_bidirectional/b. 亚马逊:
i. 2020年10月,亚马逊:我们提取了BERT的一个最优子架构,只有Bert-large的16%,CPU推理速度提升7倍。https://mp.weixin.qq.com/s/kBW4d7aH-LQM1bStrQY_gAc. 腾讯:
i. 2020年1月,内存用量1/20,速度加快80倍,腾讯QQ提出全新BERT蒸馏框架,未来将开源。https://mp.weixin.qq.com/s/W668zeWuNsBKV23cVR0zZQ
1. 腾讯 QQ 团队研究员对 BERT 进行了模型压缩,在效果损失很小的基础上,LTD-BERT 模型大小 22M,相比于 BERT 模型内存、存储开销可降低近 20 倍,运算速度方面 4 核 CPU 单机可以预测速度加速 80 余倍。
ii. BERT解读:https://mp.weixin.qq.com/s/-s1m-zXHo_yz8-tO2t8wPgd. 阿里:
i. 2020年1月,推理速度提升29倍,参数少1/10,阿里提出AdaBERT压缩方法。https://mp.weixin.qq.com/s/mObuD4ijUCjnebYIrjvVdw
1. https://arxiv.org/pdf/2001.04246v1.pdfe. UC伯克利:
i. 2020年1月,超低精度量化BERT,UC伯克利提出用二阶信息压缩神经网络。https://mp.weixin.qq.com/s/0qBlnsUqI2I-h-pFSgcQig
1. https://arxiv.org/pdf/1909.05840.pdff. 华中科技大学、华为诺亚方舟实验室:
i. TinyBERT:2019年9月,一种为基于 transformer 的模型专门设计的知识蒸馏方法,模型大小还不到 BERT 的 1/7,但速度是 BERT 的 9 倍还要多,而且性能没有出现明显下降。https://mp.weixin.qq.com/s/VL7TSHmZPKD-xGdOxNmnHw
1. https://arxiv.org/abs/1909.10351g. 佐治亚理工学院、俄勒冈州立大学、Facebook AI Research:
i. 2019年12月,BERT新转变:面向视觉基础进行预训练!https://mp.weixin.qq.com/s/KlNlcY4pUSU0KQDJaB6IbA
1. 该模型学习图像内容和自然语言的无任务偏好的联合表征。ViLBERT在BERT的基础上扩展为多模态双流模型,在各自的流中处理图像和文本输入,这两个流通过共注意力transformer层进行交互。
2. https://www.aminer.cn/pub/5db9297647c8f766461f745b/
3. https://github.com/jiasenlu/vilbert_betah. 综合及其他:
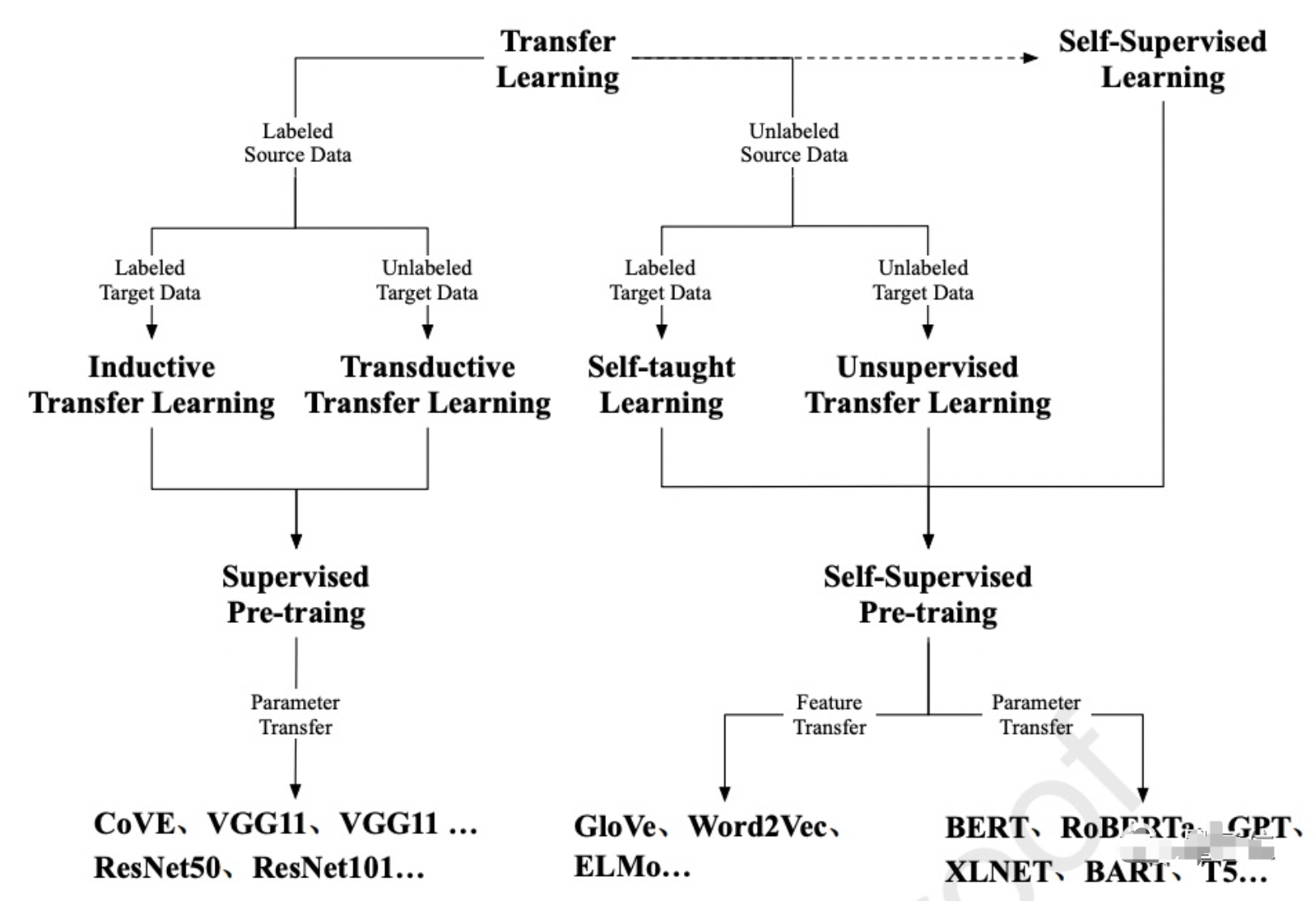
i. 2021年9月,清华唐杰团队:一文看懂NLP预训练模型前世今生。https://mp.weixin.qq.com/s/KfTP4saj6M2HDMso2eArxg
1.
ii. 2020年9月,周明:预训练模型在多语言、多模态任务的进展。https://mp.weixin.qq.com/s/RKA_RxTQkIeJX3_VIKJiRQ
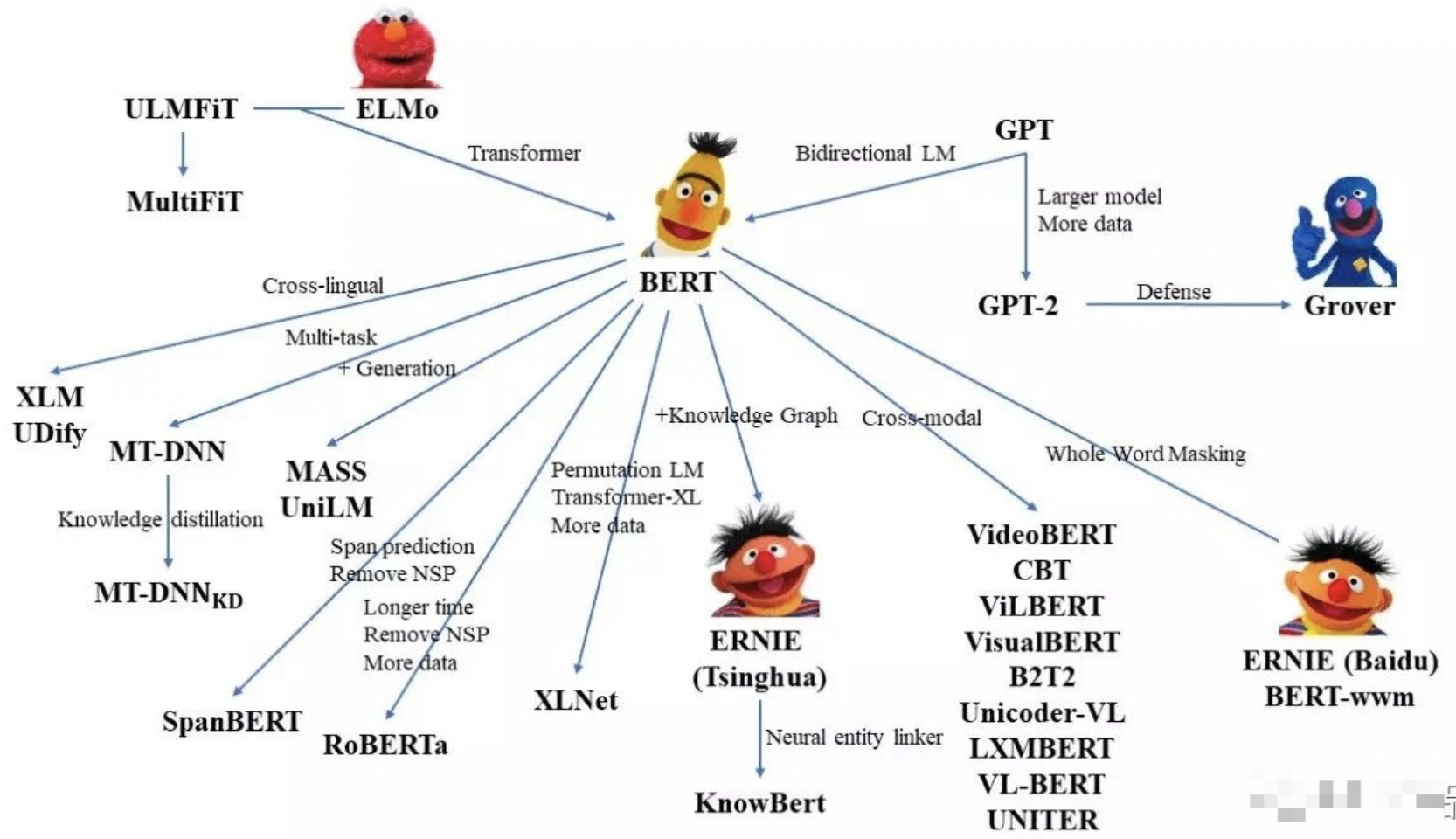
iii. 2020年5月,万字长文带你纵览 BERT 家族。https://mp.weixin.qq.com/s/uvyBnaFB21kqpeCc8u3kvQ
1.
iv. 2019年12月,BERT模型超酷炫,上手又太难?请查收这份BERT快速入门指南!https://mp.weixin.qq.com/s/jVSW0KDhaXuaIeOzoPmCJA
v. 2019年10月,一款超小型、基于BERT的中文预训练模型ALBERT_TINY。参数大小1.8M,模型大小16M,仅为BERT的1/25,训练和推理预测速度提升近10倍。https://mp.weixin.qq.com/s/eVlNpejrxdE4ctDTBM-fiA
1. https://github.com/brightmart/albert_zh
vi. 曾经狂扫11项记录的谷歌NLP模型BERT,近日遭到了网友的质疑:该模型在一些基准测试中的成功仅仅是因为利用了数据集中的虚假统计线索,如若不然,还没有随机的结果好。BERT并不能做出正确“理解”,只能利用统计线索。
1. 论文地址:https://arxiv.org/pdf/1907.07355.pdf
2. Reddit地址:https://www.reddit.com/r/MachineLearning/comments/cfxpxy/berts_success_in_some_benchmarks_tests_may_be/
3. https://mp.weixin.qq.com/s/JO27D-Zet0IJcBZ4uj8BYA
vii. 【干货】BERT模型的标准调优和花式调优。https://mp.weixin.qq.com/s/nVM2Kxc_Mn7BAC6-Pig2UwGPT:
a. GPT-4:
i. 2021年9月,不用1750亿!OpenAI CEO放话:GPT-4参数量不增反减。https://mp.weixin.qq.com/s/-qDwwuwyToN1qIr0p1dZqA
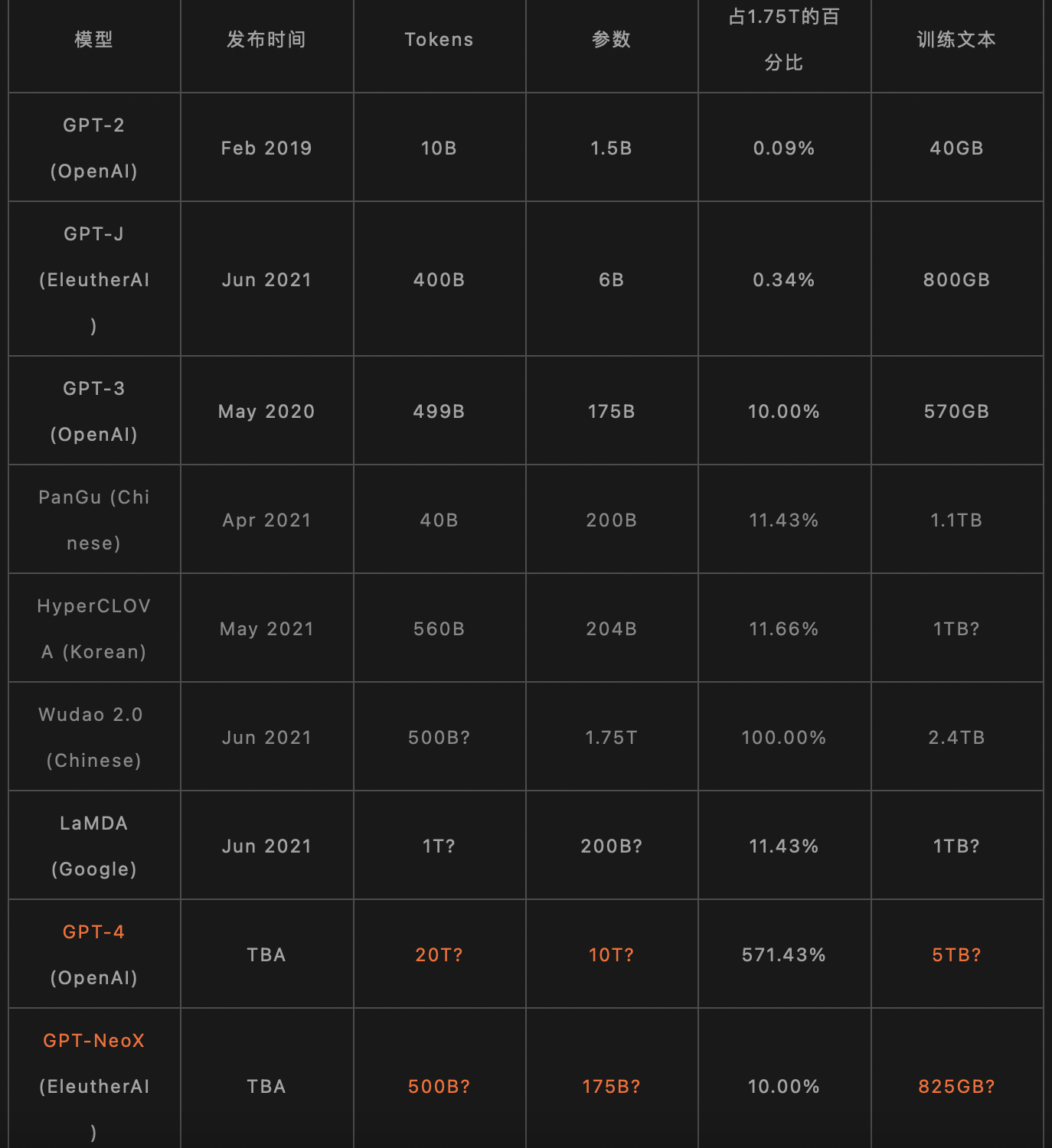
ii. 2021年7月,GPT-4参数将达10兆!这个表格预测全新语言模型参数将是GPT-3的57倍。https://mp.weixin.qq.com/s/NcElG6H_8C0sONDBuOe3kA
1. GPT-4将会有高达10兆个参数?近日,有网友在分析了GPT-3和其他语言模型之后大胆预测,GPT-4将会达到GPT-3的57倍!而「开源版本」则会达到和GPT-3同等的规模。
2.
b. GPT-f:用于数学问题的 GPT-f,利用基于 Transformer 语言模型的生成能力进行自动定理证明
i. 2020年9月,GPT自动证明数学题,结果被专业数据库收录,数学家点赞。https://mp.weixin.qq.com/s/E7yhnCsVYRYx9QMkUX17-g
c. GPT-3(1750亿参数):https://github.com/openai/gpt-3,https://arxiv.org/abs/2005.14165
i. 2021年11月,方向对了?MIT新研究:GPT-3和人类大脑处理语言的方式惊人相似。https://mp.weixin.qq.com/s/_JAe8vEUTlBk1w2tzbab9Q
1. 论文:https://www.pnas.org/content/118/45/e2105646118
2. 论文预印版(Biorxiv):https://www.biorxiv.org/content/biorxiv/early/2020/10/09/2020.06.26.174482.full.pdf
3. GitHub:https://github.com/mschrimpf/neural-nlp
ii. 2021年11月,60亿击败1750亿、验证胜过微调:OpenAI发现GPT-3解决数学题,并非参数越大越好。https://mp.weixin.qq.com/s/8UxFOCUWoMQa3SSAgDUs3g
1. 论文地址:https://arxiv.org/pdf/2110.14168.pdf
2. 数据集地址:https://github.com/openai/grade-school-math
iii. 2021年1月,GPT“高仿”系列开源了!最大可达GPT-3大小,还能自主训练。https://mp.weixin.qq.com/s/r4y2P73yZe4aoJ-VHsd-Yw
1. https://github.com/EleutherAI/gpt-neo
iv. 2020年10月,GPT-3跌下神坛?AI教父Yann LeCun发长文警告:不要对它抱有不切实际的期待!https://mp.weixin.qq.com/s/C2_DrHoGkCz6RIlBab56Iw
v. 2020年9月,GPT-3最新测试出炉:57项任务表现均低于专家水平,最不擅长STEM。https://mp.weixin.qq.com/s/lWAxmZTNoHcAe2nQ8IQHXg
1. 论文地址:https://arxiv.org/pdf/2009.03300.pdf
2. 测试地址:https://github.com/hendrycks/test
vi. 2020年8月,人工智能“大杀器”GPT-3遭严重质疑:它其实是在“胡言乱语”,OpenAI违背科学伦理。https://mp.weixin.qq.com/s/DvgfFbwHstrC4CAn-EMdcw
vii. 2020年7月,GPT-3成精了,万物皆文本时代来临!10年内通过图灵测试?https://mp.weixin.qq.com/s/7RSuxRutygS1HwEeoRnoFQ
1. https://www.technologyreview.com/2020/07/20/1005454/openai-machine-learning-language-generator-gpt-3-nlp/
viii. 2020年6月,OpenAI发布首个商业产品,集成GPT-3的API,已有十几家公司买单。https://mp.weixin.qq.com/s/-RImMW3ng6sf-M-apZWskA
ix. 2020年5月,1750亿参数,史上最大AI模型GPT-3上线:不仅会写文章、答题,还懂数学。https://mp.weixin.qq.com/s/xfLhxPiDLsVLYqpOwVk1yQ
d. GPT-2( 15 亿参数):https://github.com/openai/gpt-2,https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
i. 2019年11月,只需单击三次,让中文GPT-2为你生成定制故事。https://mp.weixin.qq.com/s/FpoSNNKZSQOE2diPvJDHog
1. 项目地址:https://github.com/imcaspar/gpt2-ml
2. Colab 演示地址:https://colab.research.google.com/github/imcaspar/gpt2-ml/blob/master/pretrained_model_demo.ipynb
ii. 2019年11月,模仿川普语气真假难分,康奈尔盲测15亿参数模型:从未如此逼真,最强编故事AI完全体来了。https://mp.weixin.qq.com/s/vUcEgfD-_AXh5zgLd6WW8Q
1. https://transformer.huggingface.co/doc/gpt2-xl
2. https://talktotransformer.com/
3. https://github.com/Morizeyao/GPT2-Chinese
iii. 2019年5月,OpenAI 在其博客上表示:我们正采用两种机制来发布 GPT-2:分阶段发布和基于伙伴关系的共享。
1. 作为分阶段发布的下一步,我们将先公布参数为 3.45 亿的模型。
2. 而对于致力于提高大型语言模型的 AI 和安全社区合作伙伴,我们将与之分享 7.62 亿和 15 亿参数的模型。
3. OpenAI 准备逐步一点点公开 GPT-2 模型,或者基于合作伙伴的关系给对方分享更大参数的模型。
iv. OpenAI:
1. 一个续写故事达到人类水平的AI,OpenAI大规模无监督语言模型GPT-2,狂揽7大数据集最佳纪录。https://mp.weixin.qq.com/s/yXl3XYfDlvrX-UrrgMK9ig,https://mp.weixin.qq.com/s/6VAZ9s_rPjXYcX0kZYHqmA
a. 论文 https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
b. 介绍博客 https://blog.openai.com/better-language-models/
c. 开源地址 https://github.com/openai/gpt-2
v. 2019年2月,有人在得到OpenAI研究人员的帮助下,用完整的、15 亿参数版本的GPT-2模型生成了一个《哈利·波特》的同人剧本,并表示结果超乎想象
1. https://twitter.com/JanelleCShane/status/1097652984316481537,https://www.fast.ai/2019/02/15/openai-gp2/
vi. 2019年2月,关于只有部分开源的负面报道和讨论:https://mp.weixin.qq.com/s/Kn-zRUWjZqy1UqN7hvzMwA
vii. 2019年2月,15亿参数!史上最强通用NLP模型诞生:狂揽7大数据集最佳纪录。https://mp.weixin.qq.com/s/6VAZ9s_rPjXYcX0kZYHqmA
1. 如果说谷歌的BERT代表NLP迈入了一个预训练模型的新时代,OpenAI便用这一成果证明,只要拥有超凡的数据量和计算力,就能实现以往无法想象的事情。XLM-R:
a. 2019年11月,Facebook最新语言模型XLM-R:多项任务刷新SOTA,超越单语BERT。https://mp.weixin.qq.com/s/6oK-gevKLWDwdOy4aI7U7g
i. https://arxiv.org/pdf/1911.02116.pdfBlender:
a. 2020年4月,15亿语料训练的94亿参数大模型更懂我?Facebook开源全球最强聊天机器人Blender。https://mp.weixin.qq.com/s/pkTbl-ezIEsaeMNpA8Pv_Q
i. 这次的改进包括最新的对话生成策略,混合技巧,以及94亿个参数的神经网络模型,这比现有最大的系统大了3.6倍。作为多年来人工智能对话研究的顶峰,这将是第一个把不同的对话技能(包括同理心、知识和个性)融合在一起的聊天机器人。
ii. Blender这次使用了15亿个对话作为训练语料,Transformer模型有94亿个参数。虽然网络很大,但是采用了并行方法对模型进行了分割,使得神经网络更易于管理,同时保持最高的效率。BART:
a. 2019年11月,多项NLP任务新SOTA,Facebook提出预训练模型BART。https://mp.weixin.qq.com/s/1-EJ36-lY9YZSLBG5c2aaQ
i. https://arxiv.org/pdf/1910.13461.pdfXLNet:
a. 2019年6月,来自卡耐基梅隆大学与谷歌大脑的研究者提出新型预训练语言模型 XLNet,在 SQuAD、GLUE、RACE 等 20 个任务上全面超越 BERT。https://mp.weixin.qq.com/s/29y2bg4KE-HNwsimD3aauw
i. 论文地址:https://arxiv.org/pdf/1906.08237.pdf
ii. 预训练模型及代码地址:https://github.com/zihangdai/xlnetERNIE
a. 百度:
i. 2021年9月,刷新4项文档智能任务纪录,百度TextMind打造ERNIE-Layout登顶文档智能权威榜单。https://mp.weixin.qq.com/s/Dfu8kr68r4dq0k8OTa-zCQ
1. 百度智能文档分析平台 TextMind:https://cloud.baidu.com/product/textmind.html
2. 百度文心 ERNIE:https://wenxin.baidu.com/
ii. 2021年7月,刷新50多个NLP任务基准,并登顶SuperGLUE全球榜首,百度ERNIE 3.0知识增强大模型显威力。https://mp.weixin.qq.com/s/Qn1NRSTKEv4Uc80kQnT29Q
iii. 2021年1月,同时掌握96门语言,取得多项世界突破,百度发布预训练模型ERNIE-M。https://mp.weixin.qq.com/s/UIU-X9MzvUBNTuCqLuemVw
iv. 2019年7月,百度正式发布ERNIE 2.0,16项中英文任务超越BERT、XLNet,刷新SOTA。https://mp.weixin.qq.com/s/EYQXM-1WSommj9mKJZVVzw
1. ERNIE 2.0 开源地址:https://github.com/PaddlePaddle/ERNIE
v. 中文任务全面超越BERT:百度正式发布NLP预训练模型ERNIE。https://mp.weixin.qq.com/s/KQHSyIjVrNmvRlwdsa0F9Q
1. https://github.com/PaddlePaddle/LARK/tree/develop/ERNIEPLATO-XL(110 亿)
a. 百度:
i. 2021年9月,超越Facebook、谷歌、微软,百度发布全球首个百亿参数对话预训练生成模型PLATO-XL。https://mp.weixin.qq.com/s/yFH-hwD9FPIqDIOYXBpz4Q
1. 论文名称 : PLATO-XL: Exploring the Large-scale Pre-training of Dialogue Generation
2. 论文地址:https://arxiv.org/abs/2109.09519
3. 超过之前最大的对话模型 Blender,是当前最大规模的中英文对话生成模型M6-10T(10万亿参数):
a. 2021年11月,512张GPU炼出10万亿参数巨模型!5个月后达摩院模型再升级,今年双十一已经用上了。https://mp.weixin.qq.com/s/qNcDsEMwC2f6Tk2GYLgKWA
i. https://arxiv.org/abs/2110.03888悟道:
a. 2021年3月,我国首个超大智能模型「悟道」发布,迎接基于模型的AI云时代。https://mp.weixin.qq.com/s/lsKVS_-aJSFf3shVx_ku7Q盘古(华为):
a. 2021年4月,瞄准GPT-3落地难题,首个千亿中文大模型「盘古」问世,专攻企业级应用。https://mp.weixin.qq.com/s/gHoeUiZ2b4IvAb-S-wMdtw孟子:
a. 2021年7月,四两拨千斤!AI大牛周明率澜舟团队刷新CLUE新纪录,轻量化模型孟子一鸣惊人。https://mp.weixin.qq.com/s/b9HL6kWTCnQ17JrRFYke3Q
i.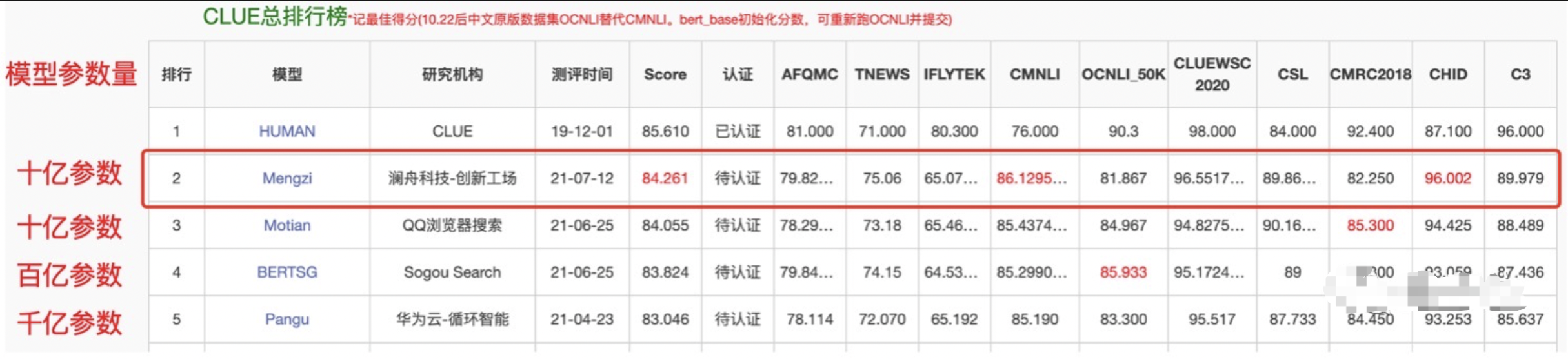
源:
a. 源1.0(2457亿参数)
i. 浪潮:2021年9月,2457亿参数!全球最大AI巨量模型「源1.0」发布,中国做出了自己的GPT-3。https://mp.weixin.qq.com/s/d6wVEM6dUalkITKo8Sly6A,https://mp.weixin.qq.com/s/_RDp7E8HVI2Myotj7YpFzQZEN:
a. 2019年11月,中文预训练模型ZEN开源,效果领域内最佳,创新工场港科大出品。https://mp.weixin.qq.com/s/NLhqVKrPgYBPRjM1uYwM9A
i. ZEN开源地址:https://github.com/sinovation/zen
ii. 论文地址:http://arxiv.org/abs/1911.00720MegatronLM
a. 英伟达:世界上最大的语言模型——MegatronLM,包含83亿参数,比BERT大24倍,比GPT-2大5.6倍
i. https://github.com/NVIDIA/Megatron-LMELECTRA
a. 2019年11月,2019最佳预训练模型:非暴力美学,1/4算力超越RoBERTa。https://mp.weixin.qq.com/s/_R-Bp5lLov-QIoPRl6fFMA
i. 论文:《ELECTRA: PRE-TRAINING TEXT ENCODERS AS DISCRIMINATORS RATHER THAN GENERATORS》
ii. 论文链接:https://openreview.net/pdf?id=r1xMH1BtvB
iii.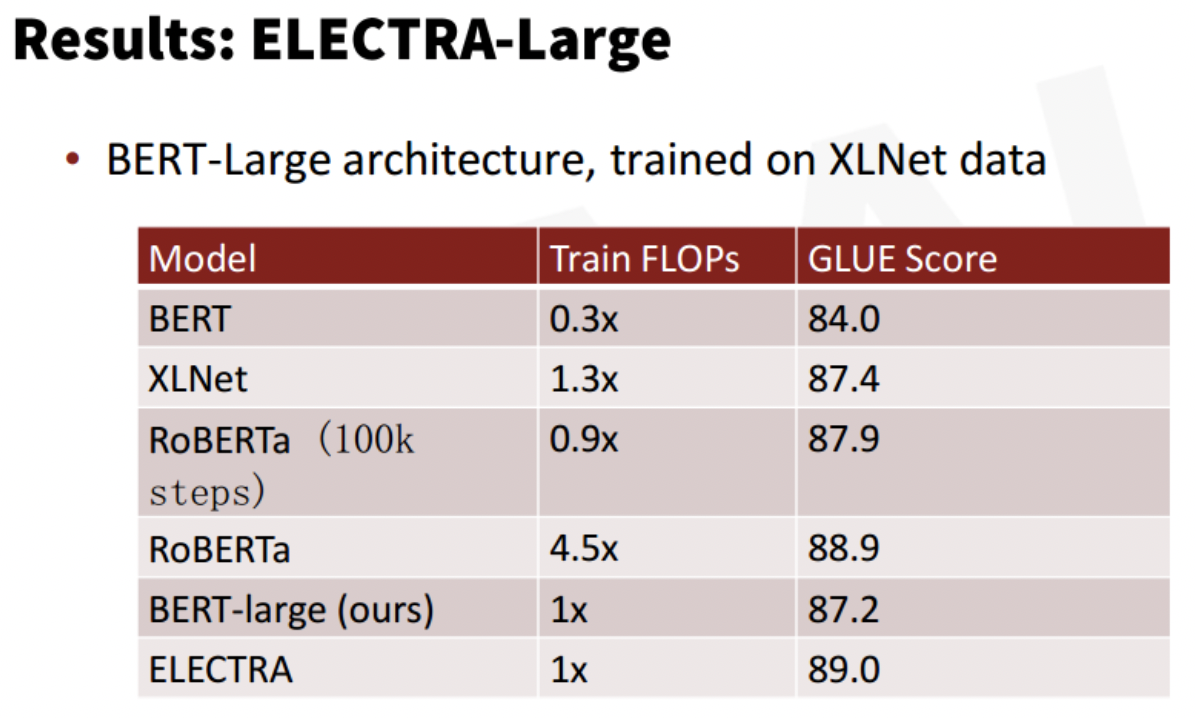
NEZHA(哪吒)
a. 2019年12月,华为开源预训练语言模型「哪吒」:编码、掩码升级,提升多项中文 NLP 任务性能!https://mp.weixin.qq.com/s/m8FMHrguehfDDSTHZb-Ufw
i. https://arxiv.org/pdf/1909.00204.pdf (TinyBERT,https://mp.weixin.qq.com/s/f2vxlhaGW1wnu8UYrvh-tA)
ii. Github 开源地址(包含 NEZHA 与 TinyBERT ):https://github.com/huawei-noah/Pretrained-Language-Modelopen_model_zoo:
a. OpenCV 的 GitHub 页面中有一个称为「open_model_zoo」的资源库,里面包含了大量的计算机视觉预训练模型,并提供了下载方法。使用这些免费预训练模型可以帮助你加速开发和产品部署过程。项目地址:https://github.com/opencv/open_model_zooALBERT:
a. 预训练小模型也能拿下13项NLP任务,谷歌ALBERT三大改造登顶GLUE基准。https://mp.weixin.qq.com/s/kvSoDr0E_mvsc7lcLNKmgg
i. 论文地址:https://openreview.net/pdf?id=H1eA7AEtvS
ii. 嵌入向量参数化的因式分解,跨层参数共享,句间连贯性损失T-ULR
a. 2020年11月,微软多语言预训练模型T-ULRv2登顶XTREME排行榜,https://mp.weixin.qq.com/s/s6nMcYoSAFIBuzZGQ8556g
i. https://www.microsoft.com/en-us/research/publication/towards-language-agnostic-universal-representations/
ii. https://arxiv.org/abs/2007.07834综合及其他
a. 2021年8月,Fine-tune之后的NLP新范式:Prompt越来越火,CMU华人博士后出了篇综述文章。https://mp.weixin.qq.com/s/2eA4PBd-wr9tVyyuzJ66Bw
i. CMU 博士后研究员刘鹏飞:近代自然语言处理技术发展的第四范式可能是预训练语言模型加持下的 Prompt Learning
ii. Prompt 主要有两种主要类型:填充文本字符串空白的完形填空(Cloze)prompt,和用于延续字符串前缀的前缀 (Prefix) prompt
iii. 在 NLP 中,基于 Prompt 的学习方法试图通过学习 LM 来规避这一问题,该 LM 对文本 x 本身的概率 P(x; θ) 进行建模并使用该概率来预测 y,从而减少或消除了训练模型对大型监督数据集的需求。
iv. https://github.com/thunlp/PromptPapers
v. https://arxiv.org/pdf/2107.13586.pdf
b. 2021年5月,语言模型微调领域有哪些最新进展?一文详解最新趋势。https://mp.weixin.qq.com/s/XVZSAxaWM30t9rOeXYM03A
i. https://ruder.io/recent-advances-lm-fine-tuning/
c. 2021年2月,480万标记样本:Facebook提出「预微调」,持续提高语言模型性能。https://mp.weixin.qq.com/s/CP75jWPQl0bJAl9RiSWTYw
i. Facebook的研究人员提出了一种能够改善训练语言模型性能的方法——预微调,在大约50个分类、摘要、问答和常识推理数据集上进行了480万个标记样本。
ii. https://venturebeat.com/2021/02/01/facebook-researchers-propose-pre-fine-tuning-to-improve-language-model-performance/
d. 2020年6月,从BERT、XLNet到MPNet,细看NLP预训练模型发展变迁史。https://mp.weixin.qq.com/s/DJdhJ4r7HZCVTzJZjM-TDA
e. 2020年5月,NLP领域预训练模型的发展。https://blog.tensorflow.org/2020/05/how-hugging-face-achieved-2x-performance-boost-question-answering.html
i.
f. 2019年12月,预训练是AI未来所需要的全部吗?https://mp.weixin.qq.com/s/RCxUhcqLHM1XODRsZQSehg
g. 2019年12月,深度迁移学习在 NLP 中的应用:选 BERT 还是被评逆天的 GPT 2.0?https://mp.weixin.qq.com/s/6WIEItSuI7-dG4if-hL0Yg
h. 2019年10月,预训练语言模型关系图+必读论文列表。https://mp.weixin.qq.com/s/-U_Lu2MMr5QRNe1xpv-_Xg
i. https://github.com/thunlp/PLMpapers
i. 2019年6月,大公司的大模型到底有多贵?有人算了一笔账。https://mp.weixin.qq.com/s/KmadSY9mkq30OJvZVHdlqQ
i. 1语言模型
1. BERT:1.2 万美元
2. GPT-2:4.3 万美元
3. XLNet:6.1 万美元
ii. 高分辨率 GAN
1. BigGAN:2.5 万美元
2. StyleGAN:0.3 万美元
j. 2019年3月,NLP领域最优秀的8个预训练模型。https://mp.weixin.qq.com/s/4jHYCKZqBoA0R6516ceWgA
i. 多用途自然语言处理模型
1. ULMFiT:https://github.com/fastai/fastai/tree/master/courses/dl2/imdb_scripts
2. Transformer:https://github.com/tensorflow/models/tree/master/official/transformer
3. Google BERT:https://github.com/google-research/bert
4. Google Transformer-XL:https://github.com/kimiyoung/transformer-xl
5. OpenAI GPT-2:https://github.com/openai/gpt-2
ii. 词嵌入
1. ELMo:https://github.com/allenai/allennlp/blob/master/tutorials/how_to/elmo.md
2. Flair:https://github.com/zalandoresearch/flair
iii. 其他预训练模型
1. StanfordNLP:https://github.com/stanfordnlp/stanfordnlp
k. 2018年11月,何恺明、Ross Cirshick等大神深夜扔出“炸弹”:ImageNet预训练并非必须。大神们使用随机初始化便得到了媲美COCO冠军的结果,无情颠覆“预训练+微调”思维定式(ImageNet 预训练模型并非必须,ImageNet 能做的只是加速收敛,对最终物体检测的精度或实例分割的性能并无帮助)论文地址:https://arxiv.org/pdf/1811.08883.pdf,知乎讨论:https://www.zhihu.com/question/303234604/answer/536820942
l. 2018年10月,预训练NLP模型和预训练的 ImageNet 模型在计算机视觉中的作用一样广泛:
i. 长期以来,词向量一直是自然语言处理的核心表征技术。然而,其统治地位正在被一系列令人振奋的新挑战所动摇,如:ELMo、ULMFiT、OpenAI transformer、Google双向transformer的BERT、OpenAI的GPT-2。这些方法因证明预训练的语言模型可以在一大批 NLP 任务中达到当前最优水平而吸引了很多目光。这些方法预示着一个分水岭:它们在 NLP 中拥有的影响,可能和预训练的 ImageNet 模型在计算机视觉中的作用一样广泛。
6 对抗生成(GAN:Generative Adversarial Networks)
2019年3月,生成对抗网络GAN论文TOP 10。https://mp.weixin.qq.com/s/gH6b5zgvWArOSfKBSIG1Ww
a. DCGANs:https://arxiv.org/abs/1511.06434
b. Improved Techniques for Training GANs:https://arxiv.org/abs/1606.03498
c. Conditional GANs:https://arxiv.org/abs/1411.1784
d. Progressively Growing GANs:https://arxiv.org/abs/1710.10196
e. BigGAN:https://arxiv.org/abs/1809.11096
f. StyleGAN:https://arxiv.org/abs/1812.04948
g. CycleGAN:https://arxiv.org/abs/1703.10593
h. Pix2Pix:https://arxiv.org/abs/1611.07004
i. StackGAN:https://arxiv.org/abs/1612.03242
j. Generative Adversarial Networks:https://arxiv.org/abs/1406.2661Ian Goodfellow
a. 在CVPR2018的GAN演讲:Introduction to GANs.pdf
b. 在推特上推荐了10篇GAN论文,是跟踪GAN进展,了解最新技术不容错过的。https://mp.weixin.qq.com/s/_ghJerYi8OimO2LrDYzs_Q
i. 主要是图像生成相关的文章
c. 争议、流派,有关GAN的一切:Ian Goodfellow Q&A:https://mp.weixin.qq.com/s/b8g_wNqi4dD5x9whj9ZN4A
i. https://fermatslibrary.com/arxiv_comments?url=https%3A%2F%2Farxiv.org%2Fpdf%2F1406.2661.pdfGoogle:
a. 2020年1月,继Dropout专利之后,谷歌再获批GAN专利,一整套对抗训练网络被收入囊中。https://mp.weixin.qq.com/s/LRJPwg8CqGSLjJDaVpS-6g
b. DeepMind,重新理解GAN,最新算法、技巧及应用:https://mp.weixin.qq.com/s/SPAbCZloiHp2mtGu0IDWDA,Understanding Generative Adversarial Networks.pdf英伟达:
a. 2020年6月,观看5万个游戏视频后,英伟达AI学会了自己开发「吃豆人」。https://mp.weixin.qq.com/s/gt9zgD95Kz0h-lqZxAT2yw
i. 英伟达这个逆向游戏的AI叫GameGAN,顾名思义,就是用来生成游戏的GAN。GAN之前的用途主要是生成图片。5月22日是吃豆人这款游戏的40岁生日,英伟达在这一天推出GameGAN,是和吃豆人的游戏开发商万代南梦宫合作的纪念活动。GameGAN制造的游戏,连万代南梦宫工程师堤光一郎看到后都大吃一惊:“很难想象这是在没有游戏引擎的情况下重新创造出吃豆人。”
ii. 论文地址:https://cdn.arstechnica.net/wp-content/uploads/2020/05/Nvidia_GameGAN_Research.pdf
iii. 项目主页:https://nv-tlabs.github.io/gameGAN/GAN在2017年实现四大突破,未来可能对计算机图形学产生冲击:https://mp.weixin.qq.com/s/LEaY5i37DuF_gjqp1vyD-g
a. 更适合训练GAN 的损失函数:Wasserstein GAN,Improved Training of Wasserstein GANs
b. 复杂高维度数据的 GAN 神经网络结构
c. 训练方式突破,特别是Conditional GAN 训练方式的突破,CycleGAN 打破了以往 Conditional GAN 需要有细致成对标签的限制。
d. 越来越多的深度学习应用引入对抗式思想,增强了原始应用的性能
e. 生成模型是用来逼近真实数据分布,有了更新的思路,基于少量数据进行半监督的学习。
f. 目前 GAN 应用有两种方法,一是完全从无到有的生成:输入随机产生的噪声变量,输出人、动物等各种图像,这类应用难度较高;另一个则是利用 GAN 来改进已有或传统的 AI 应用,例如超分辨率、照片自动美化、机器翻译等,难度相对较低,效果也很实用。33岁 AI 新生代“教父”已崛起,或将成就人类历史上迈向具有类人意识机器的一大步:https://mp.weixin.qq.com/s/13J8rJYnW5zd42i-0M328w
a. 《麻省理工科技评论》公布了 2018 年全球十大突破性技术,“对抗性神经网络”即“生成对抗网络”作为突破性人工智能技术赫然上榜。评价是:它给机器带来一种类似想象力的能力,因此可能让它们变得不再那么依赖人类,但也把它们变成了一种能力惊人的数字造假工具。综述及其他:
a. 2020年6月,历时 6 年发展, GAN 领域当下最热门的“弄潮儿”都有哪些?https://mp.weixin.qq.com/s/NsWmZByiSxNACPspwrwh-w
b. 2020年3月,史上最全GAN综述2020版:算法、理论及应用。https://mp.weixin.qq.com/s/iLAE_WR-rQrqd4dtYWB_gA
i. https://arxiv.org/pdf/2001.06937.pdf
c. 2020年2月,DeepAI 2020 ICLR论文:最新生成模型无需人工注释即可更精确控制。 https://arxiv.org/pdf/2001.10913.pdf
i. 提出一种通过引入新方法来在生成模型的潜在空间中有方向性的寻找,从而进一步改进生成模型的潜在空间的可解释性,通过该方法,可以沿其移动以精确控制生成图像的特定属性,例如图像中对象的位置或比例。该方法不需要人工注释,特别适合搜索对生成的图像进行简单转换(例如平移,缩放或颜色变化)进行编码的方向。定性和定量地证明了该方法对于GAN和变分自动编码器的有效性。
d. 2020年1月,人有多大胆,GAN有多高产 | AI创作利器演变全过程。https://mp.weixin.qq.com/s/5aLdj2PrkGkyT5aMZcLNDg
i. https://venturebeat.com/2019/12/26/gan-generative-adversarial-network-explainer-ai-machine-learning/
ii. https://papers.nips.cc/paper/5423-generative-adversarial-nets.pdf
e. 2019年10月,你真的了解深度学习生成对抗网络(GAN)吗?https://mp.weixin.qq.com/s/HPcLohQlgZKN9B_iw7i_fg
f. 2019年7月,一文看尽 GAN 的前世今生。https://mp.weixin.qq.com/s/K24KT5fykWak6rasUjzaMQ
i. https://blog.floydhub.com/gans-story-so-far/
g. 2019年6月,GAN零基础入门:从伪造视频到生成假脸。https://mp.weixin.qq.com/s/2z1_ocfTD4Jwj7tfMbVQwQ
h. 万字综述之生成对抗网络(GAN)。https://mp.weixin.qq.com/s/fWY2wWUNPHUz_Eu7iJWWfQ
i. Hong, Yongjun, et al. “How Generative Adversarial Networks and its variants Work: An Overview of GAN.”
ii. 中文整理笔记:GAN万字长文综述%28郭晓锋%29.pdf
7 自编码器(AutoEncoder)
综述、概念:
a. 2019年11月,深度学习:AutoEncoder(自编码器)。https://blog.csdn.net/nanhuaibeian/article/details/102905323
b. 2017年,自编码器到生成对抗网络:一文纵览无监督学习研究现状。https://zhuanlan.zhihu.com/p/26751367
c. 2018年,自编码器理论与方法综述.pdf进展:
a. 2021年2月,无监督训练用堆叠自编码器是否落伍?ML博士对比了8个自编码器。https://mp.weixin.qq.com/s/fbVWs05HbRuQV0XwwsNuBg
i. https://krokotsch.eu/autoencoders/2021/01/24/Autoencoder_Bake_Off.html
b. 2020年4月,人脸合成效果媲美StyleGAN,而它是个自编码器。https://mp.weixin.qq.com/s/yB7tq2vcBpVBnM-j9PgRsw
i. 论文地址:https://arxiv.org/pdf/2004.04467.pdf
ii. GitHub 地址:https://github.com/podgorskiy/ALAE
iii. 自编码器(AE)与生成对抗网络(GAN)是复杂分布上无监督学习最具前景的两类方法,它们也经常被拿来比较。人们通常认为自编码器在图像生成上的应用范围比 GAN 窄,那么自编码器到底能不能具备与 GAN 同等的生成能力呢?这篇研究提出的新型自编码器 ALAE 可以给你答案。
8 自动人工智能学习(AutoML、NAS、AutoFL等)
卡耐基梅隆大学(CMU):
a. 寻找最优神经网络架构的任务通常需要机器学习专家花费大量时间来完成,最近人们提出的自动架构搜索方法释放了我们的精力,但却非常消耗算力。卡耐基梅隆大学(CMU)在读博士刘寒骁、DeepMind 研究员 Karen Simonyan 以及 CMU 教授杨一鸣提出的「可微架构搜索」DARTS 方法基于连续搜索空间的梯度下降,可让计算机更高效地搜索神经网络架构。该方法已被证明在卷积神经网络和循环神经网络上都可以获得业内最优的效果,而所用 GPU 算力有时甚至仅为此前搜索方法的 700 分之 1,这意味着单块 GPU 也可以完成任务。https://arxiv.org/abs/1806.09055,https://mp.weixin.qq.com/s/bjVTpdaKFx4fFtT8BjMNewFacebook发布张量理解库,几分钟自动生成ML代码:https://mp.weixin.qq.com/s/3P7XT_M_hdVm_KQ13rzp3A
a. Tensor Comprehensions_Framework-Agnostic High-Performance Machine Learning Abstractions.pdf深度学习论文自动转代码(AAAI 2018):DLPaper2Code Auto-generation of Code from Deep Learning Research Papers.pdf
Google:
a. 2021年2月,AutoML大提速,谷歌开源自动化寻找最优ML模型新平台Model Search。https://mp.weixin.qq.com/s/2p2PtfDaqV2VlLpX8gtLZg
i. https://ai.googleblog.com/2021/02/introducing-model-search-open-source.html
b. 2020年9月,SpineNet:通过神经架构搜索发现的全新目标检测架构。https://mp.weixin.qq.com/s/-u0LS7kgRPCz7L3xaXBWpQ
i. SpineNet:学习用于识别和定位的尺度排列骨干网络https://arxiv.org/abs/1912.05027
ii. 神经架构搜索https://arxiv.org/abs/1611.01578
c. 2020年7月,谷歌AutoML新进展,进化算法加持,仅用数学运算自动找出ML算法。https://mp.weixin.qq.com/s/6nOA8mktkGl1ktCfPW7uxA
i. 谷歌将这项研究进一步扩展,证明从零开始进化 ML 算法是有可能的。谷歌提出了新方法 AutoML-Zero,该方法从空程序(empty program)开始,仅使用基本的数学运算作为构造块,使用进化方法来自动找出完整 ML 算法的代码。
ii. 论文链接:https://arxiv.org/pdf/2003.03384.pdf
iii. GitHub 项目地址:https://github.com/google-research/google-research/tree/master/automl_zero#automl-zero
d. 2020年3月,谷歌大脑提出AutoML-Zero,只会数学运算就能找到AI算法,代码已开源。https://mp.weixin.qq.com/s/1c9-Qj5f_cqtNZNUX1eRYw
i. 论文地址:https://arxiv.org/abs/2003.03384,GitHub地址:https://github.com/google-research/google-research/tree/master/automl_zero
e. 2020年1月,比手工模型快10~100倍,谷歌揭秘视频NAS三大法宝。
i. https://arxiv.org/abs/1811.10636,https://arxiv.org/abs/1905.13209,https://arxiv.org/abs/1910.06961
ii. https://ai.googleblog.com/2019/10/video-architecture-search.html
f. 谷歌大脑多名研究人员发表的最新论文Backprop Evolution,提出一种自动发现反向传播方程新变体的方法。
i. 背景:大神 Geffery Hinton 是反向传播算法的发明者,但他也对反向传播表示怀疑,认为反向传播显然不是大脑运作的方式,为了推动技术进步,必须要有全新的方法被发明出来
ii. 该方法发现了一些新的方程,训练速度比标准的反向传播更快,训练时间也更短。该方法使用了一种进化控制器(在方程分量空间中工作),并试图最大化训练网络的泛化。对于特定的场景,有一些方程的泛化性能比基线更好,但要找到一个在一般场景中表现更好的方程还需要做更多的工作
iii. 论文地址:https://arxiv.org/pdf/1808.02822.pdf
g. 2018年10月,谷歌宣布开源AdaNet,这是一个轻量级的基于TensorFlow的框架,可以在最少的专家干预下自动学习高质量的模型。这个项目基于Cortes等人2017年提出的AdaNet算法,用于学习作为子网络集合的神经网络的结构。谷歌AI负责人Jeff Dean表示,这是谷歌AutoML整体工作的一部分,并且,谷歌同时提供了AdaNet的开源版本和教程notebook。链接:https://ai.googleblog.com/2018/10/introducing-adanet-fast-and-flexible.html
i. 教程:https://github.com/tensorflow/adanet/tree/v0.1.0/adanet/examples/tutorials,中文参考:https://mp.weixin.qq.com/s/HiD-OqAz67cwwchjSyIjWA
ii. Ensemble learning, the art of combining different machine learning (ML) model predictions, is widely used with neural networks to achieve state-of-the-art performance, benefitting from a rich history and theoretical guarantees to enable success at challenges such as the Netflix Prize and various Kaggle competitions.
h. 2018年8月,计算成本降低35倍!谷歌发布手机端自动设计神经网络MnasNet。https://mp.weixin.qq.com/s/cSYCT1I1asaSCIc5Hgu0Jw
i. https://arxiv.org/pdf/1807.11626.pdf
ii. https://mp.weixin.qq.com/s/Mon3rpiLbBVvEhBjCO_ImQ
i. 2018年8月,神经结构自动搜索是最近的研究热点。谷歌大脑团队谷歌大脑(AutoML组),最新提出在一种在移动端自动设计CNN模型的新方法(自动神经结构搜索方法),用更少的算力,更快、更好地实现了神经网络结构的自动搜索。论文MnasNet: Platform-Aware Neural Architecture Search for Mobile:https://arxiv.org/pdf/1807.11626.pdf
i. Jeff Dean在推特推荐了这篇论文:这项工作提出将模型的计算损失合并到神经结构搜索的奖励函数中,以自动找到满足推理速度目标的高准确率的模型。
j. 谷歌放大招!全自动训练AI无需写代码,全靠刚发布的Cloud AutoML:https://mp.weixin.qq.com/s/dIpPNvsOpXL4JKOtxmFZrA
i. 谷歌AutoML背后的技术解析:http://mp.weixin.qq.com/s/D0HngY-U7_fP4vqDIjvaew
k. 2018年3月,AutoML进展,不断进化的AmoebaNet
i. 米巴网络AmoebaNet论文地址:https://arxiv.org/abs/1802.01548
ii. https://mp.weixin.qq.com/s/NPakiT1AXefecXM71Q2Iwg,https://research.googleblog.com/2018/03/using-evolutionary-automl-to-discover.html
l. 2018年3月,进化算法 + AutoML,谷歌提出新型神经网络架构搜索方法。https://mp.weixin.qq.com/s/9qpZUVoEzWaY8zILc3Pl1A,https://research.googleblog.com/2018/03/using-evolutionary-automl-to-discover.html
i. 通过在 AutoML 中结合进化算法执行架构搜索,谷歌开发出了当前最佳的图像分类模型 AmoebaNet。本文是谷歌对该神经网络架构搜索算法的技术解读,其中涉及两篇论文,分别是《Large-Scale Evolution of Image Classifiers》和《Regularized Evolution for Image Classifier Architecture Search》。微软:
a. 2021年8月,三行代码,AutoML性能提高十倍!微软开源FLAMA,比sota还要sota。https://mp.weixin.qq.com/s/W_QFzStKuaBJ0_4xNMBQsQ
i. https://towardsdatascience.com/fast-automl-with-flaml-ray-tune-64ff4a604d1c
b. 2021年1月, 热门开源 AutoML 工具 NNI 2.0 来袭!https://mp.weixin.qq.com/s/4PqGaESvPhJDoeliOLMW_g
i. https://github.com/microsoft/nni
c. 2019年12月,长期盘踞热榜,微软官方AutoML库教你三步学会20+炼金基本功。https://mp.weixin.qq.com/s/MjNs3fVChn01KLQdfr2VKw
i. https://github.com/microsoft/nni
d. 2019年12月,上新了,NNI!微软开源自动机器学习工具NNI概览及新功能详解。https://mp.weixin.qq.com/s/nePmcLLmBneVdVmmTV0UrA
i. 2018年9月,微软亚洲研究院发布了第一版 NNI (Neural Network Intelligence) ,目前已在 GitHub 上获得 3.8K 星,成为最热门的自动机器学习(AutoML)开源项目之一。
ii. 最新版本的 NNI 对机器学习生命周期的各个环节做了更加全面的支持,包括特征工程、神经网络架构搜索(NAS)、超参调优和模型压缩在内的步骤,你都能使用自动机器学习算法来完成。
iii. https://aka.ms/nniis,https://aka.ms/nnizh,https://aka.ms/nnizqSalesforce:
a. 2018年8月,开源了其 AutoML 库 TransmogrifAI:用于结构化数据的端到端AutoML库。
i. GitHub 链接:https://github.com/salesforce/TransmogrifAI,TransmogrifAI 官网:https://transmogrif.ai/MIT:
a. 2020年4月,MIT韩松团队开发「万金油」母网,嵌套10^19个子网,包下全球所有设备。https://mp.weixin.qq.com/s/439I6hHIfq6KpkLEwAgDrw,
i. 近日,MIT韩松带领4个华人学生,搞出来一个“一劳永逸网络”,可以嵌套10^19个子网,一网包下全世界,并且能耗降低两个数量级。http://news.mit.edu/2020/artificial-intelligence-ai-carbon-footprint-0423
ii. 论文原文:https://arxiv.org/abs/1908.09791
iii. 代码已开源:https://github.com/mit-han-lab/once-for-all
b. 2019年9月,AutoML自动模型压缩再升级,MIT韩松团队利用强化学习全面超越手工调参。https://mp.weixin.qq.com/s/IxVMMu_7UL5zFsDCcYfzYA
i. 模型压缩是在计算资源有限、能耗预算紧张的移动设备上有效部署神经网络模型的关键技术,人工探索法通常是次优的,而且手动进行模型压缩非常耗时,韩松团队提出了 AutoML 模型压缩(AutoML for Model Compression,简称 AMC),利用强化学习来提供模型压缩策略
ii. https://arxiv.org/pdf/1802.03494.pdf
iii. https://arxiv.org/pdf/1510.00149.pdf
c. 2019年3月,麻省理工学院(MIT)电子工程和计算机科学系助理教授韩松与团队人员蔡涵和朱力耕设计出的 NAS 算法—ProxylessNAS,可以直接针对目标硬件平台训练专用的卷积神经网络(CNN),而且在 1000 类 ImageNet 大规模图像数据集上直接搜索,仅需 200 个 GPU 小时,如此便能让 NAS 算法能够更广泛的被运用。该论文将在 5 月举办的 ICLR(International Conference on Learning Representations)大会上发表。
i. AutoML 是用以模型选择、或是超参数优化的自动化方法,而 NAS 属于 AutoML 概念下的一个领域,简单来说,就是用“神经网络来设计神经网络”,一来好处是可以加速模型开发的进度,再者,NAS 开发的神经网络可望比人类工程师设计的系统更加准确和高效,因此 AutoML 和 NAS (Neural Architecture Search)是达成 AI 普及化远景的重要方法之一。ProxylessNAS 为硬件定制专属的高效神经网络架构,不同硬件适合不同的模型。
ii. https://arxiv.org/pdf/1812.00332.pdf伍斯特理工学院:
a. 2021年8月,不用亲手搭建型了!华人博士提出few-shot NAS,效率提升10倍。https://mp.weixin.qq.com/s/gmHdbhNNZfbXJENh4qm0TQ
i. https://www.reddit.com/r/MachineLearning/comments/op1ux8/r_facebook_ai_introduces_fewshot_nas_neural/亚马逊:
a. 2020年1月,灵魂调参师被AutoGluon打爆,李沐:调得一手好参的时代要过去了。https://mp.weixin.qq.com/s/ChYLuxGxsQK0g6MImimSDQ
i. 亚马逊AWS推出AutoGluon,只需三行代码自动生成高性能模型,让调参、神经架构搜索等过程实现自动化。一位调参师亲自试了一番,他手工调的faster rcnn就被AutoGluon通过NAS自动搜索的yolo打爆了整整6个点
b. 2019年9月,自动选择AI模型,进化论方法效率更高! https://mp.weixin.qq.com/s/xVhaIEuWUgPP8Va-hkYjFg
i. https://venturebeat.com/2019/09/23/amazon-researchers-say-evolutionary-approach-improves-the-selection-of-ai-models/旷视:
a. 2019年11月,DetNAS:首个搜索目标检测Backbone的方法。https://mp.weixin.qq.com/s/4ByvyNuN2pgr-gHxLmXvJg
i. DetNAS: Backbone Search for Object Detection,https://arxiv.org/abs/1903.10979
ii. https://github.com/megvii-model/DetNAS第四范式
a. 2020年2月,比可微架构搜索DARTS快10倍,第四范式提出优化NAS算法。https://mp.weixin.qq.com/s/w9CjMXRmU_XgwDKmvsKNbg依图:
a. 2020年3月,依图科技再破世界记录!AutoML取代人工调参,刷榜三大权威数据集。https://mp.weixin.qq.com/s/0wZetx_GGPbg4DCkRvXqPQ
i. 中国硬核人工智能独角兽依图科技依靠自研AI云端芯片QuestCore™,通过AutoML取代人工调参,深度优化的ReID算法框架,刷榜全球工业界三大权威数据集,在阿里巴巴、腾讯优图、博观智能等一众强手中取得第一MoBagel
a. 2019年12月,比谷歌AutoML快110倍,全流程自动机器学习平台应该是这样的,https://mp.weixin.qq.com/s/2dBJZLgVICXRmR7JcmnciA悉尼科技大学:
a. 2020年1月,训练15000个神经网络,加速NAS,仅用0.1秒完成搜索。https://mp.weixin.qq.com/s/21K8KiHX6TmX75Bx_VqJjA
i. https://arxiv.org/abs/2001.00326奥卢大学、西安交通大学
a. 2019年12月,基于NAS的GCN网络设计。https://mp.weixin.qq.com/s/Lylfu5kZdZVK89QRzJAfEw
i. https://zhuanlan.zhihu.com/p/97232665
ii. https://arxiv.org/abs/1911.04131综合及其他:
a. 2020年9月,4个AutoML库。https://mp.weixin.qq.com/s/o-uT_gA3fz6RrJ4MDdgD2Q
i. https://automl.github.io/auto-sklearn/master/
ii. https://epistasislab.github.io/tpot/
iii. http://hyperopt.github.io/hyperopt-sklearn/
iv. https://autokeras.com/
b. 2020年5月,从800个GPU训练几十天到单个GPU几小时,看神经架构搜索如何进化。https://mp.weixin.qq.com/s/LsPVpHZeB1v0cDE9owKC8Q
i. https://medium.com/peltarion/how-nas-was-improved-from-days-to-hours-in-search-time-a238c330cd49
c. 2019年12月,神经网络架构搜索(NAS)中的milestones。https://mp.weixin.qq.com/s/3Z1_8jxAPlkabKhIdMJmXQ。https://zhuanlan.zhihu.com/p/94252445
i. 大力出奇迹,平民化,落地
d. 2019年7月,CVPR 2019 神经网络架构搜索进展综述。https://mp.weixin.qq.com/s/QU9ZW9N9xDebjV4irNYX5g
i. https://drsleep.github.io/NAS-at-CVPR-2019/
e. 2019年7月,一文详解神经网络结构搜索(NAS)。https://mp.weixin.qq.com/s/F-Q6ySCGLxhp3ZpRcX1m9g
f. 2019年5月,神经网络架构搜索(NAS)综述。https://mp.weixin.qq.com/s/4cOPIJu2cbgjNwM7TZSBbw
i. https://www.paperweekly.site/papers/2249
g. 2019年5月,德国 USU Software AG 和斯图加特大学,AutoML研究综述:让AI学习设计AI。https://mp.weixin.qq.com/s/tFzbJdW-L342tMNXDiacCg
i. 论文地址:https://arxiv.org/abs/1904.12054
h. 综述:AutoML: A Survey of the State-of-the-Art,作者:Xin He、Kaiyong Zhao、Xiaowen Chu
i. 论文链接:https://arxiv.org/pdf/1908.00709v1
ii. 在特定领域构建高质量的深度学习系统不仅耗时,而且需要大量的资源和人类的专业知识。为了缓解这个问题,许多研究正转向自动机器学习。本文是一个全面的 AutoML 论文综述文章,介绍了最新的 SOTA 成果。首先,文章根据机器学习构建管道的流程,介绍了相应的自动机器学习技术。然后总结了现有的神经架构搜索(NAS)研究。论文作者同时对比了 NAS 算法生成的模型和人工构建的模型。最后,论文作者介绍了几个未来研究中的开放问题。
i. NAS(神经结构搜索)综述。https://mp.weixin.qq.com/s/7ikm_fijepQzcEfGqYlAmw
j. 2019年5月,神经架构搜索方法知多少。https://mp.weixin.qq.com/s/7BktpWWSbWe2DAaS9O0PcA
i. 讨论了常见搜索空间以及基于强化学习原理和进化算法的常用架构优化算法,还有结合了代理模型和 one-shot 模型的方法。
ii. 论文链接:https://arxiv.org/abs/1905.01392
k. 2018年9月,让算法解放算法工程师——NAS 综述。https://mp.weixin.qq.com/s/xRuRvXgZq-ooNQiTh0XqRg
l. 人人都能用的深度学习:当前三大自动化深度学习平台简介。https://mp.weixin.qq.com/s/vPGA3O9VhEu-wypVZ2f-tQ
m. AutoML推荐论文:
i. awesome-automl-papers:https://github.com/hibayesian/awesome-automl-paper
ii. awesome-architecture-search:https://github.com/markdtw/awesome-architecture-search
n. AutoML参考链接:
i. https://www.automl.org/,https://www.automl.org/book/
9 多模态智能、学习(Multimodel Intelligence)
9.1 综合及其他
- 2020年6月,邓力、何晓冬深度解读:多模态智能未来的研究热点。https://mp.weixin.qq.com/s/j7UzZ3iGmG7rKrcDYv_jCw
a. 基于深度学习的机器学习方法已经在语音、文本、图像等单一模态领域取得了巨大的成功,而同时涉及到多种输入模态的多模态机器学习研究有巨大的应用前景和广泛的研究价值,成为了近年来的研究热点
b. 主要基于文本和图像处理的多模态研究,如图像字幕生成、基于文本的图像生成、视觉问答、视觉推理等方向的相关研究,从表征学习、信息融合和具体应用三个角度进行了综述和回顾,并对未来可能的研究热点进行了分析和展望。
c. https://arxiv.org/abs/1911.03977
9.2 多模态、跨模态
百度:
a. 2020年12月,UNIMO:百度提出统一模态学习方法,同时解决单模与多模任务。https://mp.weixin.qq.com/s/Ckh26Fqc3B2pGOOH7uNIiQ
i. 论文名称:UNIMO: Towards Unified-Modal Understanding and Generation via Cross-Modal Contrastive Learning
ii. 论文地址:https://github.com/weili-baidu/UNIMO
b. 2020年12月,人机交互新突破:百度发布主动多模态交互技术。https://mp.weixin.qq.com/s/ThFptNO-P3eduQu416WffQ
c. 2020年6月,重磅!百度多模态模型ERNIE-ViL刷新5项任务记录,登顶权威榜单VCR。https://mp.weixin.qq.com/s/Ag9ttlVFLIzVG-kAH826lQ
i. 近日,百度在多模态语义理解领域取得突破,提出知识增强视觉-语言预训练模型 ERNIE-ViL,首次将场景图(Scene Graph)知识融入多模态预训练,在 5 项多模态任务上刷新世界最好效果,并在多模态领域权威榜单 VCR 上超越微软、谷歌、Facebook 等机构,登顶榜首。此次突破充分借助飞桨深度学习平台分布式训练领先优势。多模态语义理解是人工智能领域重要研究方向之一,如何让机器像人类一样具备理解和思考的能力,需要融合语言、语音、视觉等多模态的信息。
• 论文链接:https://arxiv.org/abs/2006.16934
• ERNIE 开源地址:https://github.com/PaddlePaddle/ERNIE快手:
a. 2019年3月,多模态技术展望:如何跨过语义鸿沟、异构鸿沟、数据缺失三大难关。https://mp.weixin.qq.com/s/tpdYcvx3QsVgthHrlpXkyg
i. 多模态技术会改变人机交互的方式
ii. 多模态技术会带来新的内容形态
iii. 多模态亟需新的算法和大型的数据
b. 2018年11月,快手科技李岩:多模态技术在产业界的应用与未来展望:https://mp.weixin.qq.com/s/84fzdTUUNGmeUSfsIdNd4A,https://baijiahao.baidu.com/s?id=1616648775324621276&wfr=spider&for=pc知乎:
a. 2021年7月,WAIC 2021 | 知乎CTO李大海:基于AI的智能社区多模态数据融合研究与实践。https://mp.weixin.qq.com/s/xe0TcOOrqlt4Yo4eorWu8w谷歌大脑、CMU:
a. 2021年8月,地表最强VLP模型!谷歌大脑和CMU华人团队提出极简弱监督模型,多模态下达到SOTA。https://mp.weixin.qq.com/s/Z3w73EAeXd1Hzg33mJnIuw
i. https://arxiv.org/pdf/2108.10904.pdf
ii. 近年来,视觉-语言预训练(vision-language pretraining, VLP)取得了快速进展。谷歌大脑与CMU华人团队提出全新图像+文本预训练模型SimVLM,在最简单的模型结构与训练方式下也能在6个多模态基准领域达到SOTA,与现有VLP模型相比泛化能力更强。CMU:
a. 2020年8月,CMU 发明“听音识物”机器人,准确率接近 80%。https://mp.weixin.qq.com/s/2cnTB8ZSyQSOz_HaDFdPvA
i. https://techxplore.com/news/2020-08-exploring-interactions-action-vision-robotics.html微软:
a. 2020年10月,情景智能平台:多模态一体化人工智能开源框架。https://mp.weixin.qq.com/s/fXdKaRkuFob7HS6p47I3iAFacebook:
a. 2021年3月,无需卷积,完全基于Transformer的首个视频理解架构TimeSformer出炉。https://mp.weixin.qq.com/s/Z_a-TrwGAxmaGgWP5VOLBA
i. https://arxiv.org/pdf/2102.05095.pdf
b. 2021年3月,13亿参数,无标注预训练实现SOTA:Facebook提出自监督CV新模型。https://mp.weixin.qq.com/s/dDc-ISpV-8oYlKreWrnmOA
i. https://arxiv.org/pdf/2103.01988.pdf
ii. https://github.com/facebookresearch/visslFacebook、哥伦比亚大学
a. 2021年2月,更精准地生成字幕!哥大&Facebook开发AI新框架(Vx2Text),多模态融合,性能更强。https://mp.weixin.qq.com/s/SpzJLhqOc1VUmUH1ILhvPA
i. https://arxiv.org/abs/2101.12059
ii. https://venturebeat.com/2021/02/02/researchers-Vx2Text-ai-framework-draws-inferences-from-videos-audio-and-text-to-generate-captions/谷歌:
a. 2021年8月,DeepMind 开源最强多模态模型Perceiver IO!玩转音频、文本、图片,还会打星际争霸。https://mp.weixin.qq.com/s/qONtKnnnmEXZzciJdS4rpw
i. https://arxiv.org/pdf/2107.14795.pdf
ii. DeepMind最近开源了一个新模型Perceiver IO,除了传统的音频、文本、图片数据可以输入进去以外,还能打星际争霸!作者宣称这可能是迈向通用人工智能的重要一步!
b. 2021年6月,XMC-GAN:从文本到图像的跨模态对比学习。https://mp.weixin.qq.com/s/ntnfLdpIuLeOQ1bPF-Sw3A
i. https://ai.googleblog.com/2021/05/cross-modal-contrastive-learning-for.html
c. 2021年1月,Vision Transformer:用于大规模图像识别的 Transformer。https://mp.weixin.qq.com/s/VwjApRcDZRo9N8glZd_BgA
i. Vision Transformer https
1. Transformerhttps://papers.nips.cc/paper/7181-attention-is-all-you-need.pdf
ii. 代码和模型https://github.com/google-research/vision_transformer华为:
a. 2021年2月,表现优于ViT和DeiT,华为利用内外Transformer块构建新型视觉骨干模型TNT。https://mp.weixin.qq.com/s/bIy1ziH5X9g_9H6GkjRxog
i. https://arxiv.org/pdf/2103.00112.pdf自动化所:
a. 2021年7月,自动化所研发全球首个图文音三模态预训练模型,让AI更接近人类想象力。https://mp.weixin.qq.com/s/gujYTJu_FMBAR74I6n8bGg
i. http://arxiv.org/abs/2107.002492019年9月,专访俞栋:多模态是迈向通用人工智能的重要方向。https://mp.weixin.qq.com/s/ABke902wCz1KjQkUT-Kkaw
a. https://www.yanxishe.com/resourceDetail/9992019年3月,多模态技术展望:如何跨过语义鸿沟、异构鸿沟、数据缺失三大难关?https://mp.weixin.qq.com/s/NtVox5ux8uosQ-85U6RQ1A
a. https://mp.weixin.qq.com/s/tpdYcvx3QsVgthHrlpXkyg2018年4月,视觉信号分离语音:谷歌团队建立了一个深度学习视听模型,用来把某个人的语音从一段混合声音里面提取出来。算法对视频做一些奇妙的改动,就可以让观众需要的声音变得格外显著,其他声音则被削弱。这项技术的独到之处,就是把听觉和视觉信号结合起来用,而不单单靠声波来分离视频中的语音。直观来看,以嘴上的动作为例,人的口型和语音相互对应。这一点会帮助AI判断,哪些声音是哪个人发出的。
a. https://mp.weixin.qq.com/s/sXepEjE1b4szz-Y9auj2kw
b. https://arxiv.org/pdf/1804.03619.pdfOpenAI:
a. 2021年1月,多模态图像版「GPT-3」来了!OpenAI推出DALL-E模型,一句话即可生成对应图像。https://mp.weixin.qq.com/s/T-cKJbexW3jS-excHDrbQQ
i. OpenAI又放大招了!今天,其博客宣布,推出了两个结合计算机视觉和NLP结合的多模态模型:DALL-E和CLIP,它们可以通过文本,直接生成对应图像,堪称图像版「GPT-3」。
1. https://openai.com/blog/dall-e/
9.3 表征学习(Representation Learning)
谷歌:
a. DeepMind的最新研究提出一种新的表示学习方法——对比预测编码。研究人员在多个领域进行实验:音频、图像、自然语言和强化学习,证明了相同的机制能够在所有这些领域中学习到有意义的高级信息,并且优于其他方法。论文地址:https://arxiv.org/pdf/1807.03748.pdf港大、腾讯:
a. 2021年10月,用Transformer振兴CNN骨干网络,港大、腾讯等联合提出视觉自监督表征学习CARE。https://mp.weixin.qq.com/s/oGS4XSjO29fHdDQXV1vyvg
i. 该研究受现有自监督表征学习架构 BYOL 的启示,结合前沿的 Transformer ,提出利用 Transfomer 来提升 CNN 注意力的自监督表征学习算法。
ii. 论文地址:https://arxiv.org/pdf/2110.05340.pdf
iii. Github 地址:https://github.com/ChongjianGE/CARE其他:
a. 2019年3月,四个任务就要四个模型?现在单个神经网络模型就够了!https://mp.weixin.qq.com/s/hRxw4zGL5pPm_kdl7xnjEQ
i. 作者尝试构建一个能同时完成图像描述,相似词、相似图像搜索以及通过描述图像描述搜索图像四项任务的深度神经网络,从实操中让大家感受「表示」的奇妙世界。
ii. https://towardsdatascience.com/one-neural-network-many-uses-image-captioning-image-search-similar-image-and-words-in-one-model-1e22080ce73d
iii. https://github.com/paraschopra/one-network-many-uses
9.4 信息融合(Information Fusion)
10 多任务学习
香港科技大学:
a. 2018年,多任务学习,《国家科学评论(National Science Review)》2018 年 1 月份发布的「机器学习」专题期刊:An overview of multi-task learning.pdf
i. 多任务学习是一个很有前景的机器学习领域,相关的理论和实验研究成果以及应用也在不断涌现。香港科技大学计算机科学与工程系的杨强教授和张宇助理教授发表了概述论文,对多任务学习的现状进行了系统性的梳理和介绍Google:
a. 2021年4月,MIT小哥联合谷歌训练7个多任务机器人,9600个任务成功率高达89%!https://mp.weixin.qq.com/s/4P-Y94nDl3EXssvleIbQ7w
i. https://ai.googleblog.com/2021/04/multi-task-robotic-reinforcement.html
b. 2018年9月,多任务学习使得单个智能体可以学习解决许多不同的问题,是人工智能研究中的长期目标。Deepmind研究了学习掌握多个而不是一个序列决策任务的问题,提出了PopArt。
i. 背景:强化学习领域在设计能够在特定任务上超越人类表现的算法方面取得了很大进展。这些算法大多用于训练单项任务,每项新任务都需要训练一个全新的智能体。这意味着学习算法是通用的,但每个解决方案并不通用;每个智能体只能解决它所训练的一项任务。
ii. 多任务学习中的一个普遍问题是,如何在竞争单个学习系统的有限资源的多个任务需求之间找到平衡。许多学习算法可能会被一系列任务中的某些待解决任务分散注意力,这样的任务对于学习过程似乎更为突出,例如由于任务内奖励的密度或大小的原因。这导致算法以牺牲通用性为代价关注那些更突出的任务。
iii. DeepMind建议自动调整每个任务对智能体更新的贡献,以便所有任务对学习动态产生类似的影响,这样做使得智能体在学习玩 57 种不同的 Atari 游戏时表现出了当前最佳性能。令人兴奋的是,Deepmind的方法仅学会一个训练有素的策略(只有一套权重),却超过了人类的中等表现,据deepmind所知,这是单个智能体首次超越此多任务域的人类级别性能。同样的方法还在 3D 强化学习平台 DeepMind Lab 的 30 项任务中实现了当前最佳性能。
iv. 论文:Multi-task Deep Reinforcement Learning with PopArt,论文链接:https://arxiv.org/abs/1809.04474
c. 尝试用一个通用模型解决跨领域的各类人工智能问题,例如:图像分类(图像 -> 类标)、看图说话(图像 -> 自然语言)、 翻译(自然语言 -> 自然语言)、语义分割(自然语言 -> 分割+类标)。One Model To Learn Them All.pdf华为:
a. 2020年5月,华为突破封锁,对标谷歌Dropout专利,开源自研算法Disout,多项任务表现更佳。https://mp.weixin.qq.com/s/L7DwT5LpfWoS474MwWOiLA
i. 开源链接:https://github.com/huawei-noah/Disout
ii. 论文链接:https://www.aaai.org/Papers/AAAI/2020GB/AAAI-TangY.402.pdf其他:
a. 2019年3月,四个任务就要四个模型?现在单个神经网络模型就够了!https://mp.weixin.qq.com/s/hRxw4zGL5pPm_kdl7xnjEQ
i. 作者尝试构建一个能同时完成图像描述,相似词、相似图像搜索以及通过描述图像描述搜索图像四项任务的深度神经网络,从实操中让大家感受「表示」的奇妙世界。
ii. https://towardsdatascience.com/one-neural-network-many-uses-image-captioning-image-search-similar-image-and-words-in-one-model-1e22080ce73d
iii. https://github.com/paraschopra/one-network-many-uses
b. 多任务深度学习的三个经验教训:https://mp.weixin.qq.com/s/EULwJVlKHpjpgGgn21BgHw,https://engineering.taboola.com/deep-multi-task-learning-3-lessons-learned/
i. 损失合并,调整学习速率,使用评估作为特征
c. 深度学习大神,rnn之父 Juergen Schmidhuber在本月24号提交了一篇名字特别牛的新论文:One Big Net For Everything.pdf
11 联邦学习(Federated Learning,联合学习、联盟学习、协作学习)、分布式AI、共享智能、隐私保护
腾讯:
a. 2019年7月,微众银行将联邦学习开源框架 FATE(Federated AI Technology Enabler)贡献给 Linux 基金会。https://mp.weixin.qq.com/s/AsQAJzoO2bFZnYgKMh3iPw
i. FATE 开源地址:https://github.com/WeBankFinTech/FATE
ii. 早在 2018 年,杨强教授就向机器之心介绍过联邦迁移学习,他表示面对欧盟的「数据隐私保护条例(GDPR)」,我们应该思考如何把 GDPR 囊括在机器学习框架之内,而不是绕着它走。联邦学习就是一种很好的方法,它希望在不共享数据的前提下,利用双方的数据实现模型优化。阿里:
a. 2020年6月,想了解蚂蚁共享智能?看这篇文章就够了。https://mp.weixin.qq.com/s/WIrODusMyCxgrfcZBv6LJw
i.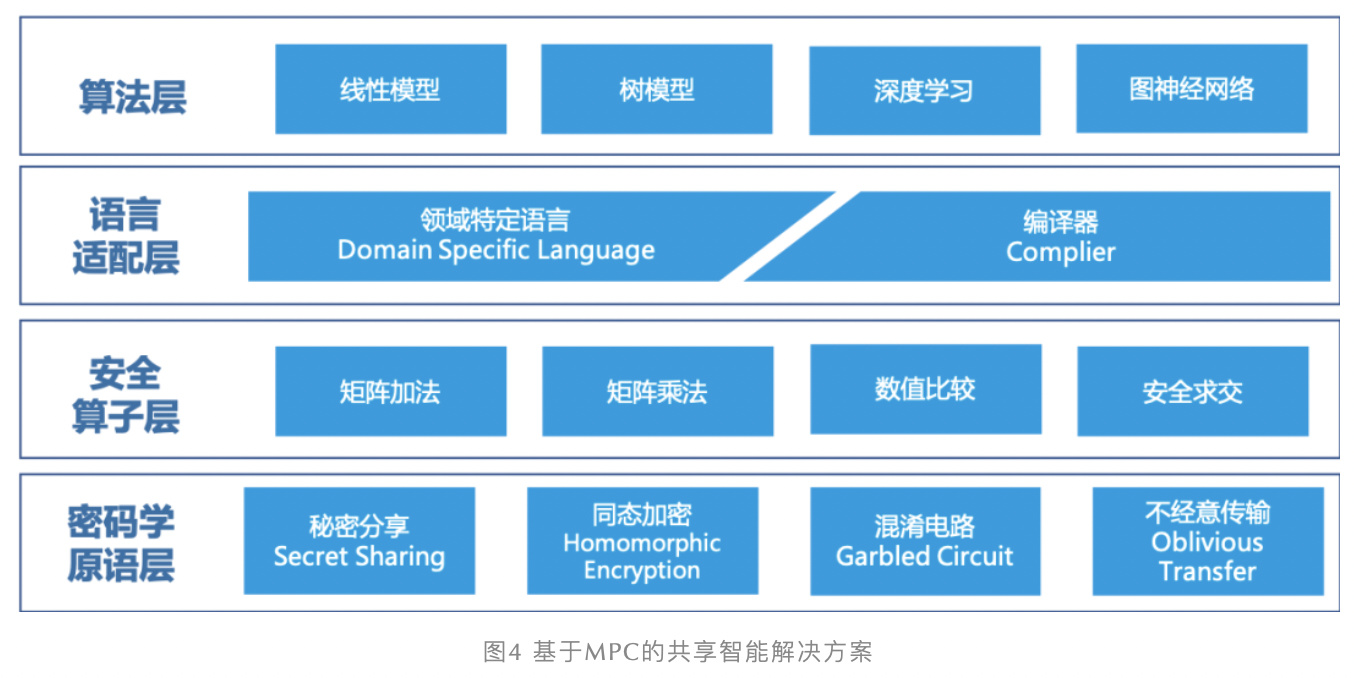
字节跳动:
a. 2020年10月,字节跳动破局联邦学习:开源Fedlearner框架,广告投放增效209%。https://mp.weixin.qq.com/s/MHUpJT1jr71Rt93BhPCvvg杨强:
a. 2020年4月,港科大杨强教授:联邦学习前沿研究与应用。https://mp.weixin.qq.com/s/uEYeL8DZjF6cIkbW-Oyr8Q
b. 2019年7月,联邦学习的最新发展及应用。https://mp.weixin.qq.com/s/Gz6UgBhDIqxA25BSHHfQmA
c. 2018年8月,联邦迁移学习与金融领域的AI落地。https://mp.weixin.qq.com/s/4TwSzTZ1rn2NBuRX3RdW4A分布式AI:
a. 2019年10月,华人主导的首届国际分布式AI大会开幕,最佳论文奖已出炉。https://mp.weixin.qq.com/s/GuD2M6pKTovdFNrJMDdrIQ
i. Rediscovery of Myerson’s Auction via Primal-Dual Analysis,http://www.adai.ai/dai/paper/36.pdf微软:
a. 2021年3月,MobiCom 2021 | 微软亚洲研究院与南大、科大等最新合作研究,助力模型高效推理和隐私保护。https://mp.weixin.qq.com/s/YYtcooKnz0U5LoRQOl665w德国波恩大学等:
a. 2021年6月,AI新算法登Nature封面!解决医疗数据隐私问题,超越联邦学习?https://mp.weixin.qq.com/s/75VjJkJvCmLpor2GZURZpQ
i. 德国波恩大学的研究人员联合惠普公司以及来自希腊、德国、荷兰的多家研究机构共同开发了一项结合边缘计算、基于区块链的对等网络协调的分布式机器学习方法——群体学习(Swarm Learning,以下简称SL),用于不同医疗机构之间数据的整合
ii. https://www.nature.com/articles/s41586-021-03583-3综合及其他:
a. 2021年8月,面向联邦学习的模型测试和调优怎么整?这篇三万字长文给你答案。https://mp.weixin.qq.com/s/0gvLZ2Mp4KpSfRfYAeU4Xw
b. 2021年7月,中国信通院闫树等:隐私计算发展综述。https://mp.weixin.qq.com/s/WoE49L0bomdlLWZJDCXxSA
c. 2021年5月,当联邦学习保护数据隐私,如何保证其自身的安全性?https://mp.weixin.qq.com/s/bYDDHQbpyxnHvY8cPCi2ug
d. 2020年9月,当传统联邦学习面临异构性挑战,不妨尝试这些个性化联邦学习算法。https://mp.weixin.qq.com/s/u5j4NVHSIFac530aHv8bAg
e. 2020年5月,隐私计算和联邦学习技术在多场景的落地实践。https://mp.weixin.qq.com/s/bQ5fBv8dvFA35lfuALXpJA
f. 2020年4月,无标准不协作,一场改变生产关系的多方合作 | 联邦学习 IEEE 国际标准即将出台。https://mp.weixin.qq.com/s/8CrFPQai0pizsvcLmkvlyg
g. 2020年3月,联邦学习最新研究趋势!https://mp.weixin.qq.com/s/dAwSPgFkf6p6k9myER1kkQ
i. https://arxiv.org/pdf/1912.04977.pdf
h. 2020年1月,想了解风头正劲的联邦学习?这篇包含400多个参考文献的综述论文满足你。https://mp.weixin.qq.com/s/0kGJfKARKs2TuIQ4YJYbUAhttps://mp.weixin.qq.com/s/TWRPiBq5VwMoPKUn3Bh2Uw
i. https://arxiv.org/pdf/1912.04977.pdf
12 弱监督学习、自监督学习、无监督学习
12.1 弱监督学习
从聊胜于无到可堪大用,半监督学习革命悄悄来临。https://mp.weixin.qq.com/s/qmlSO5Q2r0lnNDXnkF4buQ
a.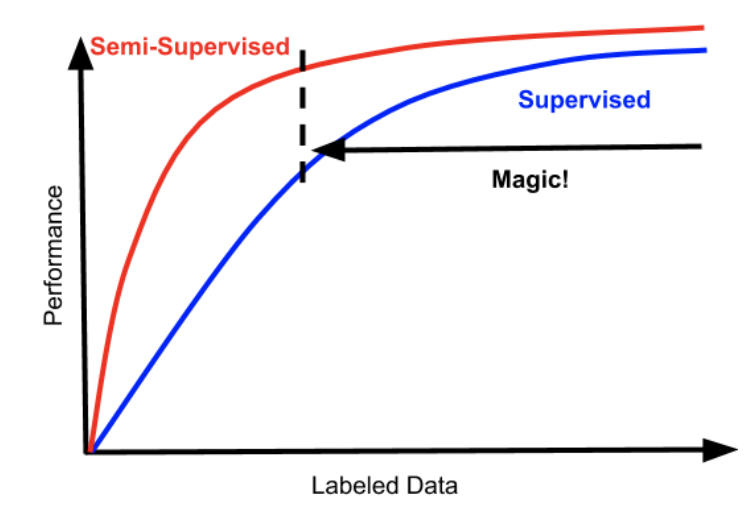
b. A Holistic Approach to Semi-Supervised Learning:https://arxiv.org/abs/1905.02249
c. Unsupervised Data Augmentation:https://arxiv.org/abs/1904.12848关于弱监督学习,这可能是目前最详尽的一篇科普文:https://mp.weixin.qq.com/s/7KM2mzQW0Jj6rftBjqAimA,http://ai.stanford.edu/blog/weak-supervision/
a. 弱监督通常分为三种类型:
i. 不完全监督:指的是训练数据只有部分是带有标签的,同时大量数据是没有被标注过的。这是最常见的由于标注成本过高而导致无法获得完全的强监督信号的情况
1. 在诸多针对不完全监督环境开发的机器学习范式中三种最流行的学习范式:
a. 主动学习(active learning):假设未标注数据的真值标签可以向人类专家查询,让专家为估计模型最有价值的数据点打上标签
b. 半监督学习(semi-supervised learning):与主动学习不同,半监督学习是一种在没有人类专家参与的情况下对未标注数据加以分析、利用的学习范式
c. 迁移学习(transfer learning):迁移学习是近年来被广泛研究,风头正劲的学习范式,其内在思想是借鉴人类「举一反三」的能力,提高对数据的利用率。
ii. 不确切监督:即训练样本只有粗粒度的标签。例如,针对一幅图片,只拥有对整张图片的类别标注,而对于图片中的各个实体(instance)则没有标注的监督信息。
iii. 不准确监督:即给定的标签并不总是真值。出现这种情况的原因有很多,例如:标注人员自身水平有限、标注过程粗心、标注难度较大。南京大学
a. 2018年1月,A brief introduction to weakly supervised learning.pdf,《国家科学评论(National Science Review)》2018 年 1 月份发布的「机器学习」专题期刊
i. 主要关注三种弱监督类型:
1. 不完全监督:只有一部分训练数据具备标签;
2. 不确切监督:训练数据只具备粗粒度标签;
3. 不准确监督:给出的标签并不总是真值。谷歌:
a. 2021年10月,谷歌发布最新看图说话模型,可实现零样本学习,多类型任务也能直接上手。https://mp.weixin.qq.com/s/uOcmUQH1jXzNJdz023x96A
i. 谷歌新推出了弱监督看图说话模型SimVLM,能够轻松实现零样本学习(zero-shot)任务迁移。
ii. https://arxiv.org/abs/2108.10904
iii. https://ai.googleblog.com/2021/10/simvlm-simple-visual-language-model-pre.html
iv. http://www.cs.cmu.edu/~ziruiw/Facebook:
a. 2019年10月,10亿照片训练,Facebook半弱监督训练方法刷新ResNet-50 ImageNet基准测试。https://mp.weixin.qq.com/s/t1Js479ZRDAw1XzPdx_nQA
i. https://ai.facebook.com/blog/billion-scale-semi-supervised-learning
ii. https://github.com/facebookresearch/semi-supervised-ImageNet1K-models小样本学习(Few-shot learning)
a. 2021年1月,归纳+记忆:让机器像人一样从小样本中学习。https://mp.weixin.qq.com/s/jN3i_X0S2FEiUoB8fhQiqg
b. 2020年9月,清华张长水等人30页少样本学习综述论文,涵盖400+参考文献。https://mp.weixin.qq.com/s/iYqAVsjG9gM_7itdDcl3og
c. 2020年5月,什么是小样本学习?这篇综述文章用166篇参考文献告诉你答案。https://mp.weixin.qq.com/s/jzo8kyh0qBCObvFQhiZePg
i. 论文地址:https://arxiv.org/pdf/1904.05046.pdf
ii. GitHub 地址:https://github.com/tata1661/FewShotPapers
d. 2019年7月,从 CVPR 2019 一览小样本学习研究进展。https://mp.weixin.qq.com/s/zvXxta3tmlI6RULA4A8YaA
i. https://towardsdatascience.com/few-shot-learning-in-cvpr19-6c6892fc8c5
e. 阿里
i. 2019年4月,小样本学习(Few-shot Learning)综述。https://mp.weixin.qq.com/s/sp03pzg-Ead-sxm4sWyaXg2020年5月,腾讯优图:带噪学习和协作学习,不完美场景下的神经网络优化策略。https://mp.weixin.qq.com/s/7E6x58JSmXQsD70kE_bDrg
12.2 自监督学习
2021年9月,数据挖掘领域大师俞士纶团队新作:最新图自监督学习综述。https://mp.weixin.qq.com/s/iFNVDDNfVUCVx9cENfFGuA
a. https://arxiv.org/pdf/2103.00111.pdf
b. 从研究背景、学习框架、方法分类、研究资源、实际应用、未来的研究方向的方面,为图自监督学习领域描绘出一幅宏伟而全面的蓝图。2021年7月,Swin Transformer为主干,清华等提出MoBY自监督学习方法,代码已开源。https://mp.weixin.qq.com/s/h2Q6-_4byVNmWgnF_eIdmg
a. 论文地址:https://arxiv.org/pdf/2105.04553.pdf
b. GitHub 地址:https://github.com/SwinTransformer/Transformer-SSL2021年3月,CVPR2021「自监督学习」领域重磅新作,只用负样本也能学?https://mp.weixin.qq.com/s/bWDD7IUBWbLGu7OL0uc5FQ
a. 在自监督学习领域,基于contrastive learning(对比学习)的思路已经在下游分类检测和任务中取得了明显的优势。其中如何充分利用负样本提高学习效率和学习效果一直是一个值得探索的方向,本文「第一次」提出了用对抗的思路end-to-end来直接学习负样本,在ImageNet和下游任务均达到SOTA.
b. 论文链接:https://arxiv.org/abs/2011.08435
c. 论文代码已开源:https://github.com/maple-research-lab/AdCo2021年3月,10亿参数,10亿张图!Facebook新AI模型SEER实现自监督学习,LeCun大赞最有前途。https://mp.weixin.qq.com/s/e6qJ00S-gNKG1SVgkN5LVg
2020年12月,研究了个寂寞?Reddit热议:AI教父Yann LeCun提出的『能量模型』到底是个啥?https://mp.weixin.qq.com/s/eBUXdmhiqSKBKuovaD-GkA
a. http://helper.ipam.ucla.edu/publications/mlpws4/mlpws4_15927.pdf
b. https://www.youtube.com/watch?v=A7AnCvYDQrU&feature=youtu.be&t=21692020年9月,自监督、半监督和有监督全涵盖,四篇论文遍历【对比学习】(Contrastive Learning)的研究进展。https://mp.weixin.qq.com/s/Hf0tVUoyH-Lb5DPVmIo5nA
2020年5月,深度学习两巨头LeCun、Bengio预言:自我监督学习是让AI接近人类智能的关键。https://mp.weixin.qq.com/s/KyGul99_lz6JNbNP89CX-g
a. https://venturebeat.com/2020/05/02/yann-lecun-and-yoshua-bengio-self-supervised-learning-is-the-key-to-human-level-intelligence/2019年11月,人工智能的下半场,一定少不了自监督学习。https://mp.weixin.qq.com/s/uCo_wGw-XYr6fxmT9VDqdA
a. 自监督学习使我们能够无需额外成本就可以利用根据数据得出各种标签,这个动机非常直接。生成一个带有「干净」(无噪声)的标签的数据集的成本是很高的,但无标签的数据却无时无刻不在产生。为了利用大量的无标签数据,一种解决方法是合理设置学习目标,以便从数据本身中得到监督信号。
b. 一般来说,所有的生成式模型都可以被看做是自监督的,但是它们的目标各不相同。2019年11月,OpenAI科学家一文详解自监督学习。https://mp.weixin.qq.com/s/wtHrHFoT2E_HLHukPdJUig
a. https://lilianweng.github.io/lil-log/2019/11/10/self-supervised-learning.html
12.3 无监督学习
综合及其他
a. 2019年4月,无监督学习:大数据带我们洞察现在,但小数据将带我们抵达未。https://mp.weixin.qq.com/s/N0Pv5FvprMuNvzqjQWxguwFacebook:
a. 2019年11月,何恺明一作,刷新7项检测分割任务,无监督预训练完胜有监督。https://mp.weixin.qq.com/s/-cXOUw9zJteVUkbpRMIWtQ
i. https://arxiv.org/pdf/1911.05722.pdf
ii. Facebook AI 研究团队的何恺明等人提出了一种名为动量对比(MoCo)的无监督训练方法。在 7 个与检测和分割相关的下游任务中,MoCo 可以超越在 ImageNet 上的监督学习结果,在某些情况下其表现甚至大大超越后者。Google:
a. 2020年7月,73岁Hinton老爷子构思下一代神经网络:属于无监督对比学习。https://mp.weixin.qq.com/s/FU_UMnt_69rjK-AUgoh6Hg
b. 2020年2月,Hinton组力作:ImageNet无监督学习最佳性能一次提升7%,媲美监督学习。https://mp.weixin.qq.com/s/Is1PsQx8Rhq7biyFCAUYjA
i. https://arxiv.org/pdf/2002.05709.pdf延世大学:
a. 2020年6月,真·无监督!延世大学提出图像到图像无监督模型,实验结果超SOTA。https://mp.weixin.qq.com/s/HxZiRAGc-zGccP6sG-8_Aw
12.4 综合及其他
- 2021年9月,对比学习(Contrastive Learning):研究进展精要。https://mp.weixin.qq.com/s/S5Hf5paZvIK7Nmrw5MU53w,https://zhuanlan.zhihu.com/p/367290573
a. 对比学习(Contrastive Learning)最近一年比较火,各路大神比如Hinton、Yann LeCun、Kaiming He及一流研究机构比如Facebook、Google、DeepMind,都投入其中并快速提出各种改进模型:Moco系列、SimCLR系列、BYOL、SwAV…..,各种方法相互借鉴,又各有创新,俨然一场机器学习领域的军备竞赛。
b. 对比学习属于无监督或者自监督学习,但是目前多个模型的效果已超过了有监督模型,这样的结果很令人振奋。
13 领域泛化(Domain Generalization,DG)
- 综述:
a. 微软:
i. 2021年4月,系统调研160篇文献,领域泛化首篇综述问世,已被IJCAI 2021接收。https://mp.weixin.qq.com/s/SQia69suLcYTEOztaLC-Ng
1. 文章链接:https://arxiv.org/abs/2103.03097
2. 领域泛化 (Domain Generalization, DG) 是近几年非常热门的一个研究方向。它研究的问题是从若干个具有不同数据分布的数据集(领域)中学习一个泛化能力强的模型,以便在未知 (Unseen) 的测试集上取得较好的效果。
3. 领域泛化问题与领域自适应 (Domain Adaptation,DA) 最大的不同:DA 在训练中,源域和目标域数据均能访问(无监督 DA 中则只有无标记的目标域数据);而在 DG 问题中,我们只能访问若干个用于训练的源域数据,测试数据是不能访问的。毫无疑问,DG 是比 DA 更具有挑战性和实用性的场景:毕竟我们都喜欢「一次训练、到处应用」的足够泛化的机器学习模型。
14 其他各类学习
14.1 几何学习(Geometric Deep Learning,GDL)
- 概念:随着深度学习技术的发展,人们已经不满足于将深度学习应用于传统的图像、声音、文本等数据上,而是对更一般的几何对象如网络、空间点云、曲面等应用深度学习算法,这一领域被称为几何深度学习(Geometric deep learning)。https://mp.weixin.qq.com/s/erVvd1DJNQRbr9WTitcn4g
- 2020年5月,顶会宠儿:几何深度学习是个啥?读完这篇,小白也可以了解GDL!https://mp.weixin.qq.com/s/erVvd1DJNQRbr9WTitcn4g
i. https://blog.paperspace.com/introduction-to-geometric-deep-learning/ - 2016年,Bronstein《Geometric deep learning: going beyond Euclidean data》,https://arxiv.org/pdf/1611.08097.pdf
- 图神经网络:5 图神经网络(GNN)
- 2021年5月,《几何深度学习》新书发布,帝国理工/DeepMind等图ML大牛共同撰写,160页pdf阐述几何DL基础原理和统一框架。https://mp.weixin.qq.com/s/pgGS7PelRCjNpuZ7QcIqGg
14.2 自信学习(Confident Learning,CL)
- 2019年11月,MIT和谷歌的研究人员便提出了一种广义的自信学习(Confident Learning,CL)方法,可以直接估计给定标签和未知标签之间的联合分布。https://mp.weixin.qq.com/s/byzL0Te5-QQLR7bxJpoZrw
i. 项目地址:https://github.com/cgnorthcutt/cleanlab/
ii. Reddit讨论:https://www.reddit.com/r/MachineLearning/comments/drhtkl/r_announcing_confident_learning_finding_and/
iii. 自信学习博客:https://l7.curtisnorthcutt.com/confident-learning
14.3 主动学习(Active Learning)
- 2019年3月,主动学习有哪些进展?答案在这三篇论文里。https://mp.weixin.qq.com/s/qTZzQZEqHIJt_LAhYMd5lw
a. 主动学习定义:
i. 在应用场景下,依赖大规模训练集才能使用的方法或模型都不再适用。为了减少对已标注数据的依赖,研究人员提出了主动学习(Active Learning)方法。主动学习通过某种策略找到未进行类别标注的样本数据中最有价值的数据,交由专家进行人工标注后,将标注数据及其类别标签纳入到训练集中迭代优化分类模型,改进模型的处理效果。
根据最有价值样本数据的获取方式区分,当前主动学习方法主要包括基于池的查询获取方法(query-acquiring/pool-based)和查询合成方法(query-synthesizing)两种。近年来提出的主动学习主要都是查询获取方法,即通过设计查询策略(抽样规则)来选择最具有价值信息的样本数据。与查询获取方法「选择(select)」样本的处理方式不同,查询合成方法「生成(generate)」样本。查询合成方法利用生成模型,例如生成式对抗网络(GAN, Generative Adversarial Networks)等,直接生成样本数据用于模型训练。
b. Learning loss for active learning(CVPR 2019,oral):https://arxiv.org/abs/1905.03677?context=cs.CV
c. Variational Adversarial Active Learning (ICCV 2019,oral):https://arxiv.org/pdf/1904.00370
d. Bayesian Generative Active Deep Learning (ICML 2019):https://arxiv.org/pdf/1904.11643.pdf
14.4 集成学习(模型集成方法等)
- 常用的模型集成方法介绍(自助法、自助聚合(bagging)、随机森林、提升法(boosting)、堆叠法(stacking)以及许多其它的基础集成学习模型)。https://mp.weixin.qq.com/s/nwd4zXy6hTjt6Hx9e7QMFg
a. 集成学习是一种机器学习范式。在集成学习中,我们会训练多个模型(通常称为「弱学习器」)解决相同的问题,并将它们结合起来以获得更好的结果。最重要的假设是:当弱模型被正确组合时,我们可以得到更精确和/或更鲁棒的模型。
14.5 多标签学习(Multi-label Learning)
- 武汉大学:
a. 2020年12月,多标签学习的新趋势(2020 Survey)。https://mp.weixin.qq.com/s/-LGRDQmYWNbluY-Iyw832Q
i. https://arxiv.org/abs/2011.11197
14.6 实时机器学习(Real-ime Machine Learning)
- 2021年1月,在线推理和在线学习,从两大层级看实时机器学习的应用现状。https://mp.weixin.qq.com/s/IykWaFi3U8EA_XGquGyRPw
a. 层级 1:机器学习系统能实时给出预测结果(在线预测)
b. 层级 2:机器学习系统能实时整合新数据并更新模型(在线学习)
14.7 深度长尾学习
- 2021年11月,正视长尾挑战!颜水成、冯佳时团队发布首篇《深度长尾学习》综述。https://mp.weixin.qq.com/s/NctAam0NgXUsC3AumLDnrQ
a. 长尾学习是推动神经网络模型落地的重要范式,旨在从大量遵循长尾类别分布的图像中训练出性能良好的深度神经网络模型。近年来,学者们对该问题开展了大量研究,并取得了可喜进展。鉴于该领域的飞速发展,在这篇综述中,来自新加坡国立大学和 SEA AI Lab 的颜水成、冯佳时团队对深度长尾学习的最新进展进行了系统性的梳理和分类讨论,并设计了一个新的评价指标对现存方法进行实验分析,同时也对未来的重要研究方向进行了展望。
b. https://arxiv.org/pdf/2110.04596.pdf
c. https://github.com/Vanint/Awesome-LongTailed-Learning
15 知识图谱(KG)、知识表达学习(Knowledge Representation Learning,KPL)
百度:
a. 2020年12月,百度&德勤:百度知识中台白皮书.pdf
b. http://kg.baidu.com/阿里:
a. 2020年3月,阿里巴巴首次揭秘电商知识图谱AliCoCo!淘宝搜索原来这样玩!https://mp.weixin.qq.com/s/GnEGHMoGJEBVBhhHljqAzA微软:
a. 2019年11月,微软核心业务即将上线Project Cortex:AI知识图谱大幅提升企业效率。https://mp.weixin.qq.com/s/tbX0GHgpf76TV_sIeFx_cw清华:
a. 2019年3月,史上最大的实体关系抽取数据集!清华大学自然语言处理团队发布 FewRel。https://mp.weixin.qq.com/s/0qnprBkJAX6BqQPmfxrYYg
i. FewRel 网站地址:https://thunlp.github.io/fewrel.html
ii. 论文地址:http://aclweb.org/anthology/D18-1514
b. AMiner:2019年1月AI之只是图谱报告,https://mp.weixin.qq.com/s/8I5IBKWYbQC6QtnkK3FUvA,人工智能之知识图谱.pdfOwnThink
a. 2010年10月,史上最大规模:这有一份1.4亿的中文开源知识图谱。https://mp.weixin.qq.com/s/5zCBQW-_me7ZvFEGi5aIMw
i. Github 地址:https://github.com/ownthink/KnowledgeGraphData
ii. ownthink 网站地址:https://www.ownthink.com/腾讯:
a. 2020年10月,全民窥豹背后的腾讯云小微知识图谱。https://mp.weixin.qq.com/s/42m1Bo6H6SY-ZIgF58DQUA
b. 2020年6月,万字详解:腾讯如何自研大规模知识图谱 Topbase。https://mp.weixin.qq.com/s/Qp6w7uFcgqKXzM7dWhYwFg
c. 2019年11月,十亿节点大规模图计算降至「分钟」级,腾讯开源图计算框架柏拉图。https://mp.weixin.qq.com/s/Uf8l2yn5iCFCUFWVvIvAOw
i. Plato 可满足十亿级节点的超大规模图计算需求,将算法计算时间从「天」级缩短到「分钟」级,性能全面领先于其它主流分布式图计算框架,并且打破了原本动辄需要数百台服务器的资源瓶颈。
ii. https://github.com/tencent/plato
iii. 图计算的「图」并不是指普通的图像和照片,而是用于表示对象之间关联关系的一种抽象数据结构。图计算可以将不同来源、不同类型的数据融合到同一个图里进行分析,得到原本独立分析难以发现的结果,因此成为社交网络、推荐系统、网络安全、文本检索和生物医疗等领域至关重要的数据分析和挖掘工具。CMU、谷歌:
a. 2020年5月,知识图谱新研究:DrKIT——虚拟知识库上的可微推断,比基于BERT的方法快10倍。https://mp.weixin.qq.com/s/2b-5D0SI-wr6rSAh_cKjSQ
i. 将语料库作为虚拟知识库(Virtual Knowledge Base,KB)来回答复杂多跳问题的方法,其可以遍历文本数据,并遵循语料库中各个实体的关系路径,并基于评分的方法,实现了整个系统端到端的训练。实验结果证明此模型可以快速地实现更好的性能。竹间科技:
a. 2021年7月,聚焦认知智能及知识图谱,竹间智能打造一体化Gemini知识工程平台,为企业提供一站式AI解决方案。https://mp.weixin.qq.com/s/ZO9IZbKIxBftpeEX6tFi9g
b. 2021年7月,“图灵测试不重要”,一个违背机器人界祖宗的决定。https://mp.weixin.qq.com/s/uaRYGiAbQ8ofDNh2-LnxNQ
i. “知识图谱技术可以让AI更加高效。在机器学习和深度学习方面减少很多不必要的数据标注以及训练,让深度学习模型具备可解释性,也可以辅助多任务的机器学习,从而提升整体效率。”2020年7月,图灵奖得主论体系结构创新,自动构建知识图谱,打造新一代Kaldi。https://mp.weixin.qq.com/s/uWi_ierKeTX02R43HFruww
综合及其他
a. 2021年1月,2020年中国面向人工智能“新基建”的知识图谱行业研究报告。https://mp.weixin.qq.com/s/XfI1tOxkD7h2cyBQfLoWzg
b. 2020年11月,艾瑞咨询:2020年面向人工智能新基建的知识图谱行业白皮书.pdf
c. 2020年7月,从ACL 2020看知识图谱研究进展。https://mp.weixin.qq.com/s/blR8Op0tmMmvUU2retslHg
d. 2020年5月,2020年中国知识图谱行业分析报告。https://mp.weixin.qq.com/s/BagQWeydMamQrp3MnFc_ew
i. https://mp.weixin.qq.com/s/S6BDfUtFBFJvcchdTByxHQ
e. 2020年3月,史上最全《知识图谱》2020综述论文,18位作者, 130页pdf。https://mp.weixin.qq.com/s/s3xvafYV25kxjdSrLd3JCA
i. https://arxiv.org/abs/2003.02320
f. 2020年3月,知识图谱前沿跟进,看这篇就够了,Philip S. Yu 团队发布权威综述,六大开放问题函待解决!https://mp.weixin.qq.com/s/L6fMcRa1_me2DKr2KADAjA
g. 2019年12月,为什么要将「知识图谱」追溯到1956年?https://mp.weixin.qq.com/s/_QLQkRpJXdngVTHsKU3eQw
h. 2019年12月,基于知识图谱+自然语言理解技术的 magi.com上线。https://mp.weixin.qq.com/s/xM97tpu9_KxlaknbAUZH2w
i. 2019年11月,知识图谱从哪里来:实体关系抽取的现状与未来。https://mp.weixin.qq.com/s/--Y-au6bwmmwUfOnkdO5-A
i. https://zhuanlan.zhihu.com/p/91762831
j. 知识图谱嵌入(KGE):方法和应用的综述。https://mp.weixin.qq.com/s/0Q28AEv9-Q0YtXORpHOfNA
i. 论文链接:https://ieeexplore.ieee.org/document/8047276,http://www.cnki.com.cn/Article/CJFDTotal-JFYZ201602003.htm
k. 构建知识图谱的成本:
i. 德国 Mannheim 大学的研究者最近仔细估算了各种知识图谱每创建一条记录所需要的成本,他们表示手动创建一个三元组(triple)的成本大约在 2 到 6 美元左右,总成本在数百万到数十亿美元之间,而自动创建知识图谱的成本要降低 15 到 250 倍(即一个三元组 1 美分到 15 美分)。论文地址:http://ceur-ws.org/Vol-2180/ISWC_2018_Outrageous_Ideas_paper_10.pdf
l. 关于图算法 & 图分析的基础知识概览。https://mp.weixin.qq.com/s/MeG3nLT0D8Q4DWBAIrc0Xw
i. https://learning.oreilly.com/library/view/graph-algorithms-/9781492060116/
m. 知识表达学习(Knowledge Representation Learning,KRL)
i. 知识表示学习领域代表论文全盘点:http://mp.weixin.qq.com/s/Fxz8ni4WyeGPGav5SB-b9w
1. A Review of Relational Machine Learning for Knowledge Graphs.pdf,知识表示学习研究进展.pdf,Graph Embedding Techniques, Applications, and Performance A Survey.pdf,Representation Learning on Graphs Methods and Applications.pdf,A Comprehensive Survey of Graph Embedding Problems, Techniques and Applications.pdf
16 认知可续、认知神经科学(Cognitive)
16.1 认知神经科学
2020年7月,认知神经的AI之光,将在北京闪耀。https://mp.weixin.qq.com/s/CYNWl7Wr5MzqbO_mw6CEPg
2020年4月,清华唐杰教授深度报告:人工智能的下个十年!https://mp.weixin.qq.com/s/HyM5veDf0RH8xM1Qpt9Uvw
a. 唐老师从人工智能发展的历史开始,深入分析人工智能近十年的发展,阐述了人工智能在感知方面取得的重要成果,尤其提到算法是这个感知时代最重要、最具代表性的内容,重点讲解了 BERT、ALBERT、MoCo2 等取得快速进展的算法。最后说到下一波人工智能浪潮的兴起,就是实现具有推理、可解释性、认知的人工智能。
b.
c.
2020年1月,AI的下一个战场:认知智能的突围。https://mp.weixin.qq.com/s/D6hl_U8xuKQkMj5vdLQwSQ
a.
b. 对人工智能发展的三个阶段进行剖析:1.计算智能;2.感知智能;3.认知智能。显然,2019年是在第二阶段渡过的,在2019年,我们进一步研究语音识别,计算机人脸的识别,以及想方设法让计算机加强语言文字处理能力。但是,对于第三阶段,让人工智能真正的进行理解,进行思考,进行推理还尚未触及到门槛。长文解读人工智能、机器学习和认知计算:http://36kr.com/p/5078536.html,https://www.ibm.com/developerworks/library/cc-beginner-guide-machine-learning-ai-cognitive/index.html
16.2 因果关系、推理
2021年7月,领先神经网络,超越人类:朱松纯团队提出首个基于符号推理的几何数学题求解器。https://mp.weixin.qq.com/s/ZFpVpi7BsJME6uXi_2IcrQ
a. 几十年来,如何让人工智能算法具备复杂的数学推理能力,像人类一样求解各种数学题,一直是科学家们追求的目标。.UCLA 联合浙江大学和中山大学的研究者提出了首个基于符号推理的几何数学题求解器 Inter-GPS
b. 论文链接:https://arxiv.org/pdf/2105.04165.pdf
c. 代码链接:https://github.com/lupantech/InterGPS
d. 项目主页:https://lupantech.github.io/inter-gps2021年5月,Judea Pearl提出的「因果阶梯」到底是什么?哥大、斯坦福研究者60页文章详解该问题。https://mp.weixin.qq.com/s/xs8A7r614uCa1G4kqqEAuQ
a. https://causalai.net/r60.pdf2020年6月,贝叶斯网络之父Judea Pearl:新因果科学与数据科学、人工智能的思考。https://mp.weixin.qq.com/s/18rGi2X-w7abji7XMm2wpw
2019年12月,贝叶斯网络之父Judea Pearl力荐、LeCun点赞,这篇长论文全面解读机器学习中的因果关系。https://mp.weixin.qq.com/s/E04x_tqWPaQ4CSWfGVbnTw
2019年1月,因果推理一直被视为深度学习中缺失的部分,除了「执果索因」的贝叶斯定理,我们很少有方法能对因果关系进行建模。现在有一本开源的书籍,作者对因果推理做了一个连续且系统的介绍。除此之外,这本书用大量的案例与比喻帮助我们理解因果推理的概念与建模方法,且章节由简到难非常适合自学。书籍开源地址:https://www.hsph.harvard.edu/miguel-hernan/causal-inference-book/
2018年,图灵奖得主、贝叶斯网络之父Judea Pearl在arXiv上传了他的最新论文,论述当前机器学习理论局限,并给出来自因果推理的7大启发。Theoretical Impediments to Machine Learning With Seven Sparks from the Causal Revolution.pdf
南京大学
a. “溯因学习”(abductive learning)
i. 2018年,周志华教授等人在最新的一篇论文中提出了“溯因学习”(abductive learning)的概念,将神经网络的感知能力和符号AI的推理能力结合在一起,能够同时处理亚符号数据(如原始像素)和符号知识。Tunneling Neural Perception and Logic Reasoning through Abductive Learning.pdf谷歌:
a. 2020年3月,DeepMind新模型MEMO引入Transformer,模仿人脑推理表现抢眼!https://mp.weixin.qq.com/s/nNqEhuTFFdkDzV6VPqOX_g
i. MEMO能够解决bAbI数据集的20个任务,具备了目前最先进的性能,而这种灵活加权是通过将记忆中单个事实的独立存储与强大的注意机制相结合来实现的。微软:
a. 2020年6月,ACL 2020丨多轮对话推理数据集MuTual发布,聊天机器人常识推理能力大挑战。https://mp.weixin.qq.com/s/W8Hzi6bvD2RlKCuUWuZ8gw
i. 论文地址:http://arxiv.org/abs/2004.04494
ii. Learderboard地址:https://nealcly.github.io/MuTual-leaderboard
iii. GitHub地址:https://github.com/Nealcly/MuTual
b. 2019年9月,机器推理系列文章概览:七大NLP任务最新方法与进展。https://mp.weixin.qq.com/s/1rhspn8NtpPNsAG0qlzXDA
i. 机器推理(Machine Reasoning),是指基于已有知识对未见问题进行理解和推断,并得出问题对应答案的过程。根据该定义,机器推理涉及4个主要问题:
(1)如何对输入进行理解和表示?
(2)如何定义知识?
(3)如何抽取和表示与输入相关的知识?
(4)基于对输入及其相关知识的理解,如何推断出输入对应的输出?
(5)
17 经典机器学习
2021年1月,贝叶斯统计与建模的综述:https://mp.weixin.qq.com/s/-TiySBy14c7TLvSL3ZxFvw
a. 典型的贝叶斯工作流程包括三个主要步骤:通过先验分布捕捉统计模型中给定参数的可用知识,这通常是在数据收集之前确定的;利用观测数据中可用参数的信息确定似然函数;利用贝叶斯定理结合先验分布和似然函数,得到后验分布。
b. 论文链接:https://arxiv.org/pdf/1909.12313.pdf
c. 原文链接:https://www.nature.com/articles/s43586-020-00001-2周志华:Boosting学习理论的探索 —— 一个跨越30年的故事。https://mp.weixin.qq.com/s/7Ah4w9Qte44MhoE66rFm9w
一张地图带你玩转机器学习。https://mp.weixin.qq.com/s/okl2LiNLRLtp6AKH9cUnmQ
a.
2020年9月,当支持向量机遇上神经网络:这项研究揭示了SVM、GAN、Wasserstein距离之间的关系。https://mp.weixin.qq.com/s/QW3az1gjQ7IjhGtxByDs6Q
2018年4月,全方位对比深度学习和经典机器学习。https://mp.weixin.qq.com/s/eS7GV5mz6BVPUXd7WTbWwA
a. 原文链接:https://towardsdatascience.com/deep-learning-vs-classical-machine-learning-9a42c6d48aa
18 量子机器学习、量子AI
综合及其他:
a. 2021年3月,量子机器学习 :IT 领域的下一件大事。https://mp.weixin.qq.com/s/Z8zCGxJbwbMCIjErAKsexQ谷歌:
a. 2021年10月,谷歌量子AI:应对最棘手的全球挑战,需要新的计算方式。https://mp.weixin.qq.com/s/7_SQniOCEvL-plcupo6FMg
b. 2020年3月,谷歌重磅发布TensorFlow Quantum:首个用于训练量子ML模型的框架。https://mp.weixin.qq.com/s/CT5wi_sUFXTYR_kgSGgIaw
c. 论文地址:https://arxiv.org/abs/2003.02989清华:
a. 2018年12月,清华大学量子信息中心段路明教授和其博士研究生郜勋、张正宇发现具有指数加速的量子机器学习算法,展示了量子计算机在人工智能研究领域中的巨大潜力,该成果的研究论文 A quantum machine learning algorithm based on generative models 近日发表于科学子刊 Science Advances(《科学 • 进展》)上。
i. 论文链接:http://advances.sciencemag.org/content/4/12/eaat9004,清华大学交叉信息研究院官网,地址:http://iiis.tsinghua.edu.cn/show-7352-1.html百度
a. 量子机器学习:https://github.com/PaddlePaddle/Quantum
19 综述及其他
Google:
a. 2021年10月,一个算法统治一切!DeepMind提出神经算法推理,深度学习和传统算法融合再现奇迹?https://mp.weixin.qq.com/s/slutOnBTdr0RQwwEN6S7hA
i. 一个算法统治一切!DeepMind提出神经算法推理(NAR),用深度学习模型模仿任何经典算法,同时实现传统算法的泛化性和神经网络的最优解的完美结合。
ii. https://venturebeat.com/2021/10/12/deepmind-is-developing-one-algorithm-to-rule-them-all/
iii. https://venturebeat.com/2021/09/10/deepmind-aims-to-marry-deep-learning-and-classic-algorithms/
iv. https://arxiv.org/abs/2108.11482
b. 2021年2月,反向传播和生物学没关系?NO!大牛告诉你:在反向传播基础上找到生物学解释。https://mp.weixin.qq.com/s/_mzsSmEZlQDEe_3y7rVTsw
i. https://www.quantamagazine.org/artificial-neural-nets-finally-yield-clues-to-how-brains-learn-20210218/
c. 2021年1月,新方向!DeepMind提出人工生命框架,促进智能生物体的出现。https://mp.weixin.qq.com/s/orLTqIW16l9F8QiJaFsqnA
i. 论文地址:https://arxiv.org/pdf/2101.07627.pdf
d. 神经网络与高斯过程结合
i. DeepMind:神经网络目前是最强大的函数近似器,而高斯过程是另一种非常强大的近似方法。DeepMind 刚刚提出了两篇结合高斯过程与神经网络的研究,这种模型能获得神经网络训练上的高效性,与高斯过程在推断时的灵活性。DeepMind 分别称这两种模型为神经过程与条件神经过程,它们通过神经网络学习逼近随机过程,并能处理监督学习问题。Neural Processes:https://arxiv.org/abs/1807.01622,Conditional Neural Processes:https://arxiv.org/abs/1807.01613
e. 可微分逻辑编程(结合深度学习与符号程序优点)
i. 2018年,DeepMind 在 JAIR 上发表论文《Learning Explanatory Rules from Noisy Data》,提出可微分逻辑编程,结合深度学习与符号程序优点,表明将直观感知思维和概念可解释性推理思维整合到单个系统中是可能的。Learning Explanatory Rules from Noisy Data.pdf
f. 心智理论的神经网络ToMnet
i. 2018年提出“机器心智理论”(Machine Theory of Mind),启发自心理学中的“心智理论”,研究者构建了一个心智理论的神经网络ToMnet,并通过一系列实验证明它具有心智能力
ii. 试图构建一个学习对其他智能体进行建模的系统,构建心智理论神经网络让机器互相理解:https://mp.weixin.qq.com/s/BDwgPgw0ULuHoKdae2g7FAMIT、IBM:
a. 2020年12月,让神经网络给符号AI“打工”,MIT和IBM联合解决深度学习痛点,未来将用于自动驾驶。https://mp.weixin.qq.com/s/Z4sJns-JeH6jRxJpWt5xJg
i. https://knowablemagazine.org/article/technology/2020/what-is-neurosymbolic-ai
ii. https://arxiv.org/abs/1910.01442MIT、Facebook:
a. 2021年6月,Facebook、MIT 等发表 449 页论文:解释深度学习实际工作原理的理论。https://mp.weixin.qq.com/s/dXk2jEdEFX36SWpronRhEw,https://mp.weixin.qq.com/s/dXk2jEdEFX36SWpronRhEw
i. 来自Facebook公司、普林斯顿大学和麻省理工学院的AI研究人员近日联合发表了一份新的手稿,他们声称该手稿提供了一个理论框架,首次描述了深度神经网络的实际工作原理。
ii. https://ai.facebook.com/blog/advancing-ai-theory-with-a-first-principles-understanding-of-deep-neural-networks
iii. The Principles of Deep Learning Theory.pdf利物浦、牛津:
a. 2021年8月,不能兼顾速度与精度,利物浦大学、牛津大学揭示梯度下降复杂度理论,获STOC 2021最佳论文。https://mp.weixin.qq.com/s/trdFbynh1fPjqMdDFgHlSA
i. https://arxiv.org/pdf/2011.01929.pdf2021年9月,深度学习也有武林大会!八大科技巨头:我的「流派」才能实现AGI。https://mp.weixin.qq.com/s/uwE3PbYfg0zFO23Tr8152Q
a.
2021年7月,50年最重要,8大统计学发展!哥大教授论文列举推动AI革命的统计学思想。https://mp.weixin.qq.com/s/EY5eUIrXmi18D1bDis6W9A
a. https://www.tandfonline.com/doi/full/10.1080/01621459.2021.1938081,作者将这些统计学思想归类为8大类别:
i. 反事实因果推断(counterfactual causal inference)
ii. 自举法和基于模拟的推断(bootstrapping and simulation-based inference)
iii. 超参数化模型和正则化(overparameterized models and regularization)
iv. 贝叶斯多级模型(Bayesian multilevel models)
v. 通用计算算法(generic computation algorithms)
vi. 自适应决策分析(adaptive decision analysis)
vii. 鲁棒性推断(robust inference)
viii. 探索性数据分析(exploratory data analysis)2021年1月,因果推理、正则化上榜:权威专家盘点过去50年最重要的统计学思想。https://mp.weixin.qq.com/s/L8v_2a214P9HTby5GGPkCw
a. https://arxiv.org/pdf/2012.00174.pdf2021年1月,AI 发展方向大争论:混合AI ?强化学习 ?将实际知识和常识整合到AI中 ?https://mp.weixin.qq.com/s/GoBQZOOngxaX3yQ1y84pZg
2019年12月,GELU超越ReLU却鲜为人知,3年后被挖掘:BERT、GPT-2等都在用的激活函数。https://mp.weixin.qq.com/s/LEPalstOc15CX6fuqMRJ8Q
a. https://arxiv.org/pdf/1606.08415.pdfNon-IID数据:若DL没了独立同分布假设,样本不独立的机器学习方法综述。https://mp.weixin.qq.com/s/BCQYdpgZdzdNLXZadptP1w
a. http://people.ee.duke.edu/~lcarin/IJCAI07-121.pdf机器学习中的模型评价、模型选择与算法选择:Model Evaluation, Model Selection, and Algorithm Selection in Machine Learning.pdf
深度学习遇上稀缺数据就无计可施?这里有几个好办法!https://mp.weixin.qq.com/s/__HI1SHErKf675kHGJ4V6Q
a. https://towardsdatascience.com/how-to-use-deep-learning-even-with-small-data-e7f34b673987自 2012 年多伦多大学 Alex Krizhevsky 等人提出 AlexNet 以来,「深度学习」作为一种机器学习的强大方法逐渐引发了今天的 AI 热潮。随着这种技术被应用到各种不同领域,人们已经开发出了大量新模型与架构,以至于我们无法理清网络类型之间的关系。近日,来自 University of Dayton 的研究者们对深度学习近年来的发展历程进行了全面的梳理与总结,并指出了目前人们面临的主要技术挑战。The History Began from AlexNet_A Comprehensive Survey on Deep Learning Approaches.pdf
a. 内容包括:DNN、CNN、训练模型的先进技术、 RNN、AE 和 RBM、GAN、强化学习、迁移学习、深度学习的高效应用方法和硬件、深度学习框架和标准开发工具包(SDK)、不同应用领域的基准测试结果。