AI学习基础结构
条评论AI的学习基础资料相关,方便后续学习查阅。转自刘**整理资料。
注意力机制、模型(Attention Model,Self-Attention)
- 2021年3月,谷歌自锤Attention is all you need:纯注意力并没那么有用,Transformer组件很重要。https://mp.weixin.qq.com/s/otTlKuUq-_HtBpvZaqOwAA
a. 论文地址:https://arxiv.org/pdf/2103.03404v1.pdf
b. 项目地址:https://github.com/twistedcubic/attention-rank-collapse - 2020年8月,Attention is All You Need?LSTM提出者:我看未必。https://mp.weixin.qq.com/s/X9hZgK0Q20J5r2wvW9K9Vg
a. https://www.zdnet.com/article/high-energy-facebooks-ai-guru-lecun-imagines-ais-next-frontier/ - 2020年2月, Attention综述:基础原理、变种和最近研究。https://mp.weixin.qq.com/s/t6IboWbX5ztdscDqUjdxXg
- 2019年12月,包学包会,这些动图和代码让你一次读懂「自注意力」。https://mp.weixin.qq.com/s/Z0–eLLiFwfSuMvnddKGPQ
a. Stacked Capsule Auto-Encoders
b. https://towardsdatascience.com/illustrated-self-attention-2d627e33b20a - 2019年9月,自然语言处理中注意力机制综述。https://mp.weixin.qq.com/s/MXNtFHm6edLvGKQa2iOp8Q
a. https://github.com/yuquanle/Attention-Mechanisms-paper/blob/master/Attention-mechanisms-paper.md - 论文:Google提出的attention模型:Attention Is All You Need.pdf
- 深度学习笔记——Attention Model(注意力模型)学习总结:http://blog.csdn.net/mpk_no1/article/details/72862348
- 关于深度学习中的注意力机制,这篇文章从实例到原理都帮你参透了:http://www.sohu.com/a/202108595_697750
- Attention Is All You Need:http://blog.csdn.net/chazhongxinbitc/article/details/78631849
X-volution (注意力、卷积的统一)
- 2021年6月,谷歌提出「卷积+注意力」新模型,超越ResNet最强变体!https://mp.weixin.qq.com/s/Rfaa-Tqef7qoVa-UBMyuyw
a. 论文地址:https://arxiv.org/abs/2106.04803
b. 谷歌提出了一个叫做CoAtNets的模型,看名字你也发现了,这是一个Convolution + Attention的组合模型。该模型实现了ImageNet数据集86.0%的top-1精度,而在使用JFT数据集的情况下实现了89.77%的精度,性能优于现有的所有卷积网络和Transformer! - 2021年6月,首次统一卷积与自注意力,上海交大、华为海思提出X-volution,发力网络核心基础架构创新。https://mp.weixin.qq.com/s/Q-dBu-jicQEpAxU9Rj_EhA
a. 论文链接:https://arxiv.org/pdf/2106.02253.pdf
b. 针对这些挑战,日前,上海交大 - 华为海思联合团队在 arXiv 上发表了「X-volution: On the Unification of Convolution and Self-attention」,首次在计算模式上统一了这两大基础算子,并在推理阶段归并成一个简单的卷积型算子:X-volution。
残差网络(ResNet)
- MIT:
a. 关于是不是所有的函数都能够用一个足够大的神经网络去逼近?CSAIL的两位研究人员从ResNet结构入手,论证了这个问题。他们发现,在每个隐藏层中只有一个神经元的ResNet,就是一个通用逼近函数,无论整个网络的深度有多少,哪怕趋于无穷大,这一点都成立。
i. https://arxiv.org/pdf/1806.10909.pdf,https://arxiv.org/abs/1709.02540?context=cs
ii. https://mp.weixin.qq.com/s/xTJr-jWMjk73TCZ8gBT4Ww - 清华:
a. 2021年6月,ResNet也能用在3D模型上了,清华「计图」团队新研究已开源。https://mp.weixin.qq.com/s/FHPN81LZrGxGRX_5ni3PfQ
i. 论文地址:https://arxiv.org/abs/2106.02285
ii. 项目地址:https://github.com/lzhengning/SubdivNet - 综合及其他
a. 2020年1月,对ResNet本质的一些思考。https://mp.weixin.qq.com/s/c55Kam2UI-cvvO3_GkDMEw
i. https://zhuanlan.zhihu.com/p/60668529
胶囊网络(Capsules)
- 2021年6月,Hinton的胶囊网络不太行?CVPR Oral论文:不比卷积网络更「强」。https://mp.weixin.qq.com/s/4ilF8PmBxuqj_PiRGpw2VA
a. 在鲁棒性上看,胶囊网络不比卷积网络更强。
b. http://128.84.4.27/pdf/2103.15459 - 2021年2月,Hinton再挖新坑:改进胶囊网络,融合Transformer神经场等研究。https://mp.weixin.qq.com/s/HpSjJXvOKFZfioz7KwpkdQ
a. GLOM综合和这些年AI领域的诸多成果,将Transformer、神经场(neural field)、对比表示学习、蒸馏等技术与胶囊网络
b. https://arxiv.org/abs/2102.12627 - 2020年2月,Hinton团队胶囊网络新进展:两种方法加持,精准检测和防御对抗性攻击。https://mp.weixin.qq.com/s/MGH4qgXQk-YfgWMYM_ktUA
a. https://arxiv.org/abs/2002.07405 - 2020年2月,Hinton AAAI2020 演讲:这次终于把胶囊网络做对了。https://mp.weixin.qq.com/s?__biz=MzA5ODEzMjIyMA==&mid=2247495712&idx=2&sn=b35dbc64928d9f1c89aaf73c1a456894&source=41&key=&ascene=0&uin=&devicetype=iMac+MacBookPro14%2C1+OSX+OSX+10.15.3+build(19D76)&version=12031e12&nettype=WIFI&lang=zh_CN&fontScale=100&winzoom=1.000000
- 2019年7月,胶囊网络升级新版本,推特2000+赞,图灵奖得主Hinton都说好。https://mp.weixin.qq.com/s/BqsFIUrVEVz5kOFh3W93gQ
a. https://arxiv.org/abs/1906.06818
b. http://akosiorek.github.io/ml/2019/06/23/stacked_capsule_autoencoders.html - 论文:
a. Dynamic Routing Between Capsules.pdf
b. Hinton提出泛化更优的「软决策树」:可解释DNN具体决策:Distilling a Neural Network Into a Soft Decision Tree.pdf - 谷歌大脑全军出击!Jeff Dean领衔全面解答AI现状与未来: https://rc.mbd.baidu.com/gzuqj0a
- 终于,Geoffrey Hinton那篇备受关注的Capsule论文公开了: https://rc.mbd.baidu.com/n22jjsh
- Hinton亲自讲解迄今未发表工作:胶囊理论的核心概念到底是什么?:https://m.leiphone.com/news/201708/Ct79WomLE6pNYXTh.html
- 全文精译 | 看Hinton在论文中如何介绍胶囊的革命之处:https://m.sohu.com/a/200882625_651893
- 核心解读Capsule官方代码开源:http://mp.weixin.qq.com/s/TYE8Z9kogXttvWiL81762w,地址:https://github.com/Sarasra/models/tree/master/research/capsules
- 从原理到代码,Hinton的胶囊网络该怎么用?https://mp.weixin.qq.com/s/6rbpRDper9BzWyWJtdhXGA
a. https://github.com/llSourcell/capsule_networks
递归皮质网络(RCN)
- 论文:
a. Vicarious
i. 在 Science的paper:A generative vision model that trains with high data efficiency and breaks text-based CAPTCHAs.pdf - 【Science】超越深度学习300倍, Vicarious发布生成视觉模型,LeCun批“这就是AI炒作的教科书”:https://yq.aliyun.com/articles/229127
图神经网络(GNN)
- 洛桑联邦理工学院:图神经网络火了?谈下它的普适性与局限性。https://mp.weixin.qq.com/s/XtnnsvB9v0jeQVZ6Y1hQtQ
a. 图神经网络(GNN)是一类基于深度学习的图域信息处理方法。由于具有较好的性能和可解释性,GNN 已成为一种广泛应用的图分析方法。然而,再好的方法都存在一定的局限。来自洛桑联邦理工学院的研究者在 arXiv 上发表了一篇论文,指出了图神经网络在消息传递分布式系统中的图灵普适性和局限性。
b. 论文链接:https://arxiv.org/abs/1907.03199 - 德国多特蒙德工业大学:2019年3月,来自德国多特蒙德工业大学的研究者们提出了 PyTorch Geometric,该项目一经上线便在 GitHub 上获得 1500 多个 star,并得到了 Yann LeCun 的点赞。现在,创建新的 GNN 层更加容易了。PyTorch Geometric比DGL快14倍(也有说15倍,估计翻译问题),但DGL2.0也发布了,更有研究人员质疑PyTorch Geometric加了很多自定义的kernel来增加跑分的结果。
a. 图神经网络是最近 AI 领域最热门的方向之一,很多图神经网络框架如 graph_nets 和 DGL 已经上线。但看起来这些工具还有很多可以改进的空间。
b. 项目链接:https://github.com/rusty1s/pytorch_geometric,graph-nets:https://mp.weixin.qq.com/s/9fFjVSiMg-LwddXfNJuKuw,DGL:https://mp.weixin.qq.com/s/rGC8O2Pyq8WL8D8ATMbH0Q - 斯坦福大学:
a. 2020年10月,什么是优秀的图表示?斯坦福提出首个信息论原则——图信息瓶颈。https://mp.weixin.qq.com/s/4-VmdrbvZPoF1CpXaDG4Eg
b. 2019年5月,斯坦福教授ICLR演讲:图网络最新进展GraphRNN和GCPN。https://mp.weixin.qq.com/s/wdDDluSeqUTEgjKHd6rBYg
i. graph_gen-iclr-may19-long.pdf,gin-iclr19.pdf
c. 2019年12月,图神经网络的ImageNet?斯坦福大学等开源百万量级OGB基准测试数据集。https://mp.weixin.qq.com/s/fCoQv6zMQw_8eOwANS16OQ
i. 项目地址:http://ogb.stanford.edu
ii. 图表示学习演讲合集:https://slideslive.com/38921872/graph-representation-learning-3
d. 2019年2月,斯坦福31页PPT讲述图神经网络的强大:https://mp.weixin.qq.com/s/DUv5c6ce-dgLOBAE4ChiQg - Google:
a. 2021年7月,比9种SOTA GNN更强!谷歌大脑提出全新图神经网络GKATs。https://mp.weixin.qq.com/s/fuCtiOjBLGReg-WLs0cMRw
i. https://arxiv.org/pdf/2107.07999.pdf
ii. 谷歌大脑与牛津大学、哥伦比亚大学的研究人员提出了一种全新的GNN:GKATs。不仅解决了计算复杂度问题,还被证明优于9种SOTA GNN。
b. 2019年5月,超越标准 GNN !DeepMind、谷歌提出图匹配网络。https://mp.weixin.qq.com/s/rvcj9-6KlBsVmF_CAsip2A
i. https://arxiv.org/pdf/1904.12787.pdf
ii. 针对图结构对象的检索与匹配这一具有挑战性的问题,做了两个关键的贡献:
1. 首先,作者演示了如何训练图神经网络(GNN)在向量空间中生成图嵌入,从而实现高效的相似性推理。
2. 其次,作者提出了一种新的图匹配网络(Graph Matching Network)模型,给出一对图形作为输入,通过一种新的基于注意力的跨图匹配机制(cross-graph attention-based matching mechanism),对图对进行联合推理,计算出一对图之间的相似度评分。
c. Google:DeepMind联合谷歌大脑、MIT等机构27位作者发表重磅论文,提出“图网络”(Graph network),将端到端学习与归纳推理相结合,有望解决深度学习无法进行关系推理的问题。http://baijiahao.baidu.com/s?id=1603225190297711463&wfr=spider&for=pc
i. https://arxiv.org/pdf/1806.01261.pdf - 东京工业大学:重新思考图卷积网络:GNN只是一种滤波器。
a. https://mp.weixin.qq.com/s/SSDEoN6sxhd_VkA2mMF5cg,论文地址:https://arxiv.org/pdf/1905.09550.pdf
b. 近年来,基于GCN的神经网络在点云分析、弱监督学习等领域得到了广泛的应用。随着输入特征空间的复杂化,我们提议重新审视当前基于GCN的GNNs设计。在计算机视觉中,GCN层并不是卷积层,我们需要把它看作一种去噪机制。因此,简单地叠加GCN层只会给神经网络设计带来过拟合和复杂性。 - 百度:
a. 2021年7月,KDD CUP 2021首届图神经网络大赛放榜,百度飞桨PGL获得2金1银。https://mp.weixin.qq.com/s/b4yj31qMc6filDkg9NoU6A
b. 2021年5月,百度万亿级图检索引擎发布!四大预训练模型开源,还“发糖”15亿元。https://mp.weixin.qq.com/s/9vmSRCYmSJ2sYwWidJSVLw - 阿里:
a. 2020年12月,开源!一文了解阿里一站式图计算平台GraphScope。https://mp.weixin.qq.com/s/JvLQI0asXhjEfUJ4ls6fMg - 清华:
a. 清华大学:2020年12月,清华大学发布首个自动图机器学习工具包AutoGL,开源易用可扩展,支持自定义模型。https://mp.weixin.qq.com/s/Khk7M_lamzbQdYvnuAzSzw
i. AutoGL 网站地址:http://mn.cs.tsinghua.edu.cn/autogl/
ii. 图深度学习模型综述:https://arxiv.org/abs/1812.04202
iii. AutoGL 说明文档:https://autogl.readthedocs.io/en/latest/index.html
iv. AutoGL 代码链接:https://github.com/THUMNLab/AutoGL
b. 2018年12月,清华大学图神经网络综述:模型与应用。http://www.sohu.com/a/284616353_129720
i. https://github.com/thunlp/GNNPapers - 华中科技大学:
a. 2021年8月,中国首次!2021年图计算挑战赛揭榜,华中科技大团队夺冠。https://mp.weixin.qq.com/s/JIDzUFT2iumg6xiUOevW7A
i. 2021年图计算挑战赛GraphChallenge
ii. https://graphchallenge.mit.edu/champions
iii. 项目地址:https://github.com/CGCL-codes/Graphchallenge21 - 中央财经:
a. 2021年1月,GCN研究新进展BASGCN:填补传统CNN和空域GCN理论空白,荣登AI顶刊。https://mp.weixin.qq.com/s/TyLdRDqNUiHxnwf9S5Ynmw
i. 针对图分类的低回溯对齐空域图卷积网络,该算法可将任意大小的图转换为固定大小的低回溯对齐网格结构,并定义了一个与网格结构关联的新空域图卷积操作 - 剑桥大学:
a. 2020年6月,147页详述「结构在神经网络中的复兴」,图注意力网络一作博士论文公开。https://mp.weixin.qq.com/s/evNCdyG6K5wIeHblfnrcpA
i. 论文链接:https://www.repository.cam.ac.uk/handle/1810/292230
ii. 图神经网络最初由 Franco Scarselli 和 Marco Gori 等人提出,在之后的十几年里被不断扩展,先后发展出了图卷积网络(Graph Convolution Networks,GCN)、 图注意力网络(Graph Attention Networks)、图自编码器( Graph Autoencoders)、图生成网络( Graph Generative Networks) 和图时空网络(Graph Spatial-temporal Networks)等多个子领域。 - 纽约大学、纽约大学、AWS:
a. 2018年12月,如何设计「既快又好」的深度神经网络?也许更加动态和稀疏的模型会是答案所在。可见,不论是数据还是模型,「图」应该成为一个核心概念。由纽约大学、纽约大学上海分校、AWS 上海研究院以及 AWS MXNet Science Team 共同开发了 Deep Graph Library(DGL),一款面向图神经网络以及图机器学习的全新框架。
i. 在设计上,DGL 秉承三项原则:(1)DGL 必须和目前的主流的深度学习框架(PyTorch、MXNet、TensorFlow 等)无缝衔接。从而实现从传统的 tensor 运算到图运算的自由转换。(2)DGL 应该提供最少的 API 以降低用户的学习门槛。(3)在保证以上两点的基础之上,DGL 能高效并透明地并行图上的计算,以及能很方便地扩展到巨图上。DGL 现已开源。
ii. 主页地址:http://dgl.ai - 综合及其他:
a. 2021年9月,支持异构图、集成GraphGym,超好用的图神经网络库PyG更新2.0版本。https://mp.weixin.qq.com/s/DFLbmVB2I824jXrSk8VhzQ
i. http://www.pyg.org/
b. 2021年8月,最新《图神经网络》综述论文,35页209篇文献详尽阐述GNN。https://mp.weixin.qq.com/s/W5JGRRS7nIBWsJ5L40iJ3A
i. https://www.zhuanzhi.ai/paper/4014c909fcaa7d7c7c7d292b6a7febbb
c. 2021年6月,319篇文献、41页综述文章讲述图神经网络用于医疗诊断的前世今生与未来。https://mp.weixin.qq.com/s/rn9p1pg92Ldik2ocBv9bLA
i. https://arxiv.org/abs/2105.13137
d. 2021年6月,华人博士发127页万字长文:自然语言处理中图神经网络从入门到精通。https://mp.weixin.qq.com/s/pouqWGvO1CopljlqYBfONA
i. 论文:https://arxiv.org/pdf/2106.06090.pdf
ii. Github:https://github.com/graph4ai/graph4nlp/
e. 2021年3月,70分钟了解图神经网络,图注意力网络一作带来最「自然」的GNN讲解。https://mp.weixin.qq.com/s/DO5i95HsAmfhgoXzjbRIeg
f. 2021年2月,关于“图机器学习算法”你应该知道的4个知识点。https://mp.weixin.qq.com/s/GGqVIxgYwBajuyZPxAUI8g
g. 2021年1月,步入2021,大热的GNN会在哪些应用领域大展拳脚呢?https://mp.weixin.qq.com/s/E5nzgWdiMvixmxlaenyy_Q
i. https://medium.com/criteo-engineering/top-applications-of-graph-neural-networks-2021-c06ec82bfc18
h. 2021年1月,图机器学习有多大神力?一文带你回顾2020,展望2021。https://mp.weixin.qq.com/s/Po-6wKm32Zcc2erauptIag
i. 2021年1月,2021年的第一盆冷水:有人说别太把图神经网络当回事儿。https://mp.weixin.qq.com/s/_QeIUiEkBpJcN56506Zrzw
i. 博客链接:https://www.singlelunch.com/2020/12/28/why-im-lukewarm-on-graph-neural-networks/
ii. https://www.reddit.com/r/MachineLearning/comments/kqazpd/d_why_im_lukewarm_on_graph_neural_networks/
j. 2020年9月,腾讯AI Lab联合清华,港中文长文解析图深度学习的历史、最新进展到应用。https://mp.weixin.qq.com/s/IlgvzuAFaJs2SxU42AFkyQ
k. 2020年5月,神经网络大比拼。https://mp.weixin.qq.com/s/erVvd1DJNQRbr9WTitcn4g
i.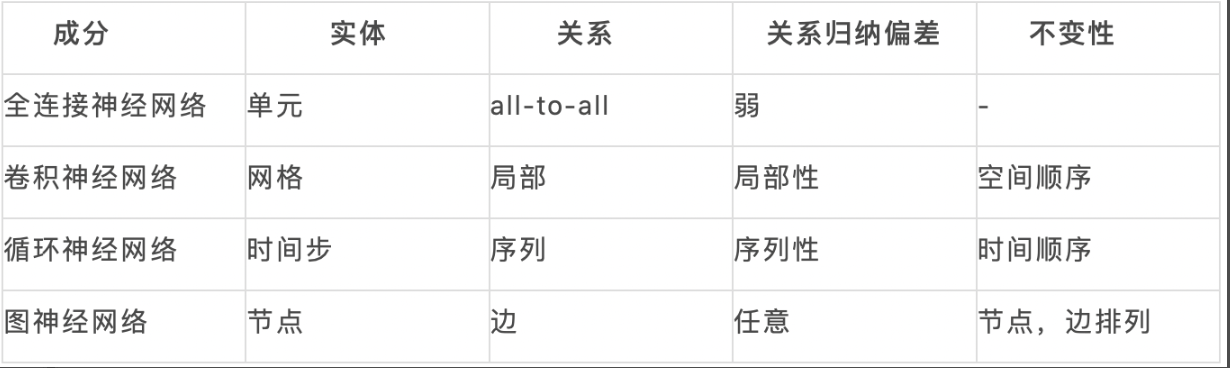
l. 2020年4月,图神经网络的新基准。https://mp.weixin.qq.com/s/v9aOoK2sHP0a9hZP0jWW0Q
i. 论文链接:https://arxiv.org/pdf/2003.00982.pdf
ii. 开源链接:https://github.com/graphdeeplearning/benchmarking-gnns
m. 2020年3月,Bengio参与、LeCun点赞:图神经网络权威基准现已开源。https://mp.weixin.qq.com/s/ldkYTvess0Wte5HzKbMBfQ
i. 在斯坦福图神经网络大牛 Jure 等人发布《Open Graph Benchmark》之后,又一个旨在构建「图神经网络的 ImageNet」的研究出现了。
ii. 论文链接:https://arxiv.org/abs/2003.00982
iii. 项目地址:https://github.com/graphdeeplearning/benchmarking-gnns
n. 2020年2月,2020年,图机器学习将走向何方?https://mp.weixin.qq.com/s/YC2gvjbSBs2qOgix6wVhuQ
i. https://towardsdatascience.com/top-trends-of-graph-machine-learning-in-2020-1194175351a3
o. 2020年2月,火爆的图机器学习,2020年将有哪些研究趋势?https://mp.weixin.qq.com/s?__biz=MzA5ODEzMjIyMA==&mid=2247495721&idx=1&sn=33fd16c66c64cd5bb621f12e256425ac&source=41#wechat_redirect
p. 2020年1月,图神经网络(Graph Neural Networks,GNN)综述。https://mp.weixin.qq.com/s/G5D7COE-3qEnd0qnVPsOWg
i. https://arxiv.org/abs/1901.00596
q. 2019年12月,17篇论文,详解图的机器学习趋势。https://mp.weixin.qq.com/s/1ecou3cqTRGkBDeV9A3AUQ
r. 2019年10月,开源图神经网络框架DGL升级:GCMC训练时间从1天缩到1小时,RGCN实现速度提升291倍。https://mp.weixin.qq.com/s/LevrZzAKxYP1IQ67zbLEmQ
i. DGL异构图教程:https://docs.dgl.ai/tutorials/hetero/1_basics.html
ii. DGL v0.4 更新笔记:https://github.com/dmlc/dgl/releases
iii. DGL-KE代码及使用说明:https://github.com/dmlc/dgl/tree/master/apps/kg
iv. DGL-Chem 模型库:https://docs.dgl.ai/api/python/model_zoo.html#chemistry
s. 2019年1月,图神经网络(GNN)热度持续上升,之前我们曾介绍了清华两篇综述论文(如下1、2)。最近,IEEE Fellow、Senior Member 和 Member Zonghan Wu 等人又贡献了一篇图神经网络综述文章。这篇文章介绍了 GNN 的背景知识、发展历史、分类与框架、应用等,详细介绍了各种模型与方法,包括公式、模型图示、算法等。
i. 其他
1. 清华大学孙茂松组在 arXiv 上发布预印版综述文章 《Graph Neural Networks: A Review of Methods and Applications》,链接:https://arxiv.org/pdf/1812.08434
2. 该领域的参考文章 https://github.com/thunlp/GNNPapers
3. 清华大学朱文武等人综述了应用于图的不同深度学习方法:《Deep Learning on Graphs: A Survey》,链接:https://arxiv.org/abs/1812.04202
ii. 论文:A Comprehensive Survey on Graph Neural Networks,链接:https://arxiv.org/pdf/1901.00596v1.pdf
t. 2018年12月,深度学习在多个领域中实现成功,如声学、图像和自然语言处理。但是,将深度学习应用于普遍存在的图数据仍然存在问题,这是由于图数据的独特特性。近期,该领域出现大量研究,极大地提升了图分析技术。清华大学朱文武等人综述了应用于图的不同深度学习方法。他们将现有方法分为三个大类:半监督方法,包括图神经网络和图卷积网络;无监督方法,包括图自编码器;近期新的研究方法,包括图循环神经网络和图强化学习。然后按照这些方法的发展史对它们进行系统概述。该研究还分析了这些方法的区别,以及如何合成不同的架构。最后,该研究简单列举了这些方法的应用范围,并讨论了潜在方向。
i. 论文:《Deep Learning on Graphs: A Survey》,https://arxiv.org/abs/1812.04202
u. 2018年10月,GNN(图神经网络)代表了一种新兴的计算模型,这自然地产生了对在大型graph上应用神经网络模型的需求。但是,由于GNN固有的复杂性,这些模型超出了现有深度学习框架的设计范围。此外,这些模型不容易在并行硬件(如GPU)上有效地加速。北京大学、微软亚洲研究院的研究人员近日发表论文,提出NGra,NGra是第一个支持GNN的并行处理框架(第一个支持大规模GNN的系统),它使用新的编程抽象,然后将其映射和优化为数据流,进而在GPU上高效执行。论文地址:https://arxiv.org/pdf/1810.08403.pdf,中文参考:https://mp.weixin.qq.com/s/5DmpgPN4t3p3H53Xu7_-3A
多项式回归
- Jeff Dean等论文发现逻辑回归和深度学习一样好。一系列实验结果表明,多项式回归至少不会比神经网络差,有些时候还超过了神经网络。https://mp.weixin.qq.com/s/Mij_hOnPWxx1ij0DcFmuiQ
a. 谷歌深度学习电子病例分析论文:https://www.nature.com/articles/s41746-018-0029-1
b. UC戴维斯+斯坦福:神经网络作为多项式回归的替代方法:https://arxiv.org/pdf/1806.06850v1.pdf
卷积神经网络(CNN)
综述及其他:
a. 2020年5月,178页,四年图神经网络研究精华,图卷积网络作者Thomas Kipf博士论文公布。https://mp.weixin.qq.com/s/h26uPmzQbVQgkwFEmAwgWA
i. 论文链接:https://pure.uva.nl/ws/files/46900201/Thesis.pdf
b. 2019年8月,图解十大 CNN 架构。https://mp.weixin.qq.com/s/_e6H7IDrdbmdmOBjgIHApQ
i. https://towardsdatascience.com/illustrated-10-cnn-architectures-95d78ace614d
c. 2019年6月,CNN网络结构的发展:从LeNet到EfficientNet。https://mp.weixin.qq.com/s/ooK2aAC_TAPFmK9dPLF-Fw
i. https://zhuanlan.zhihu.com/p/68411179
d. 深度卷积神经网络演化历史及结构改进脉络-40页长文全面解读。https://mp.weixin.qq.com/s/28GtBOuAZkHs7JLRVLlSyg
i. https://towardsdatascience.com/a-comprehensive-introduction-to-different-types-of-convolutions-in-deep-learning-669281e58215
e. 一文看懂卷积神经网络:https://mp.weixin.qq.com/s/4t3GrHkbPoi1fLF-J4t_fw,https://towardsdatascience.com/a-deeper-understanding-of-nnets-part-1-cnns-263a6e3ac61
i. 一文带你掌握4种卷积方法。https://mp.weixin.qq.com/s/y2L8C9b2RUssdJfBVJO3mA
f. 万字长文带你看尽深度学习中的各种卷积网络。https://mp.weixin.qq.com/s/IQoh6fO_oWvetnnWAuzSeQ
g. 7大类深度CNN架构创新综述。https://mp.weixin.qq.com/s/Fhge-Idk_adBjUuzaAtzyQPoint-Voxel CNN:http://pvcnn.mit.edu
a. MIT:
i. 2019年12月,内存计算显著降低,平均7倍实测加速,MIT提出高效、硬件友好的三维深度学习方法。https://mp.weixin.qq.com/s/kz5ja8K4rPD_m1GvUznByg
1. 随着三维深度学习越来越成为近期研究的热点,基于栅格化的数据处理方法也越来越受欢迎。但这种处理方法往往受限于高分辨下巨大的内存和计算开销,麻省理工学院 HAN Lab 的研究者提出利用 Point-Voxel CNN 来实现高效的三维深度学习,同时能够避免巨大的数据访问开销并很好地提升了局部性。
2. https://arxiv.org/pdf/1907.03739.pdf2021年6月,清华&旷视让全连接层“内卷”,卷出MLP性能新高度。https://mp.weixin.qq.com/s/xH8rniuWcYE6UFkiicMCcQ
a. 论文地址:https://arxiv.org/abs/2105.01883
b. 代码:https://github.com/DingXiaoH/RepMLP2019年11月,通过非对称卷积块增强CNN的核骨架。https://mp.weixin.qq.com/s/AAlCwaLMg_PEXSEyGgvdVg
a. 由于在给定的应用环境中设计合适的卷积神经网络(CNN)结构需要大量的人工工作或大量的GPU资源消耗,研究界正在寻找网络结构无关的CNN结构,这种结构可以很容易地插入到多个成熟的体系结构中,以提高我们实际应用程序的性能。我们提出了非对称卷积块(ACB)作为CNN的构造块,它使用一维非对称卷积核来增强方形卷积核,我们用ACBs代替标准的方形卷积核来构造一个非堆成卷积网络ACNet,该网络可以训练到更高的精度。训练后,我们等价地将ACNet转换为相同的原始架构,因此将不需要额外的计算。实验证明,ACNet可以CIFAR和ImageNet上显著提高各种经典模型的性能。
b. https://arxiv.org/abs/1908.03930v12018年11月,去年,微软亚洲研究院视觉计算组提出了 “Deformable Convolutional Networks”(可变形卷积网络),首次在卷积神经网络(CNN)中引入了学习空间几何形变的能力,得到可变形卷积网络(Deformable ConvNets),从而更好地解决了具有空间形变的图像识别任务。通俗地说,图像中的物体形状本来就是千奇百怪,方框型的卷积核,即使卷积多次反卷积回去仍然是方框,不能真实表达物体的形状,如果卷积核的形状是可以变化的,这样卷积后反卷积回去就可以形成一个多边形,更贴切的表达物体形状,从而可以更好地进行图像分割和物体检测。研究员们通过大量的实验结果验证了该方法在复杂的计算机视觉任务(如目标检测和语义分割)上的有效性,首次表明在深度卷积神经网络(deep CNN)中学习空间上密集的几何形变是可行的。但这个Deformable ConvNets也有缺陷,例如,激活单元的样本倾向于集中在其所在对象的周围。然而,对象的覆盖是不精确的,显示出超出感兴趣区域的样本的扩散。在使用更具挑战性的COCO数据集进行分析时,研究人员发现这种倾向更加明显。昨天,MSRA视觉组发布可变形卷积网络的升级版本:Deformable ConvNets v2 (DCNv2),论文标题也相当简单粗暴:更加可变形,更好的结果!
a. 论文地址:https://arxiv.org/pdf/1811.11168.pdf
b. 参考链接:https://mp.weixin.qq.com/s/GRyNPezKA1Q0FkPTX65cGg,https://mp.weixin.qq.com/s/yfqBGFPWkg-F_Txd-Cm0Lg
c. 知乎链接:https://www.zhihu.com/question/303900394/answer/540818451,https://www.zhihu.com/question/303900394/answer/540896238
循环神经网络(RNN)
- 全面理解RNN及其不同架构。https://mp.weixin.qq.com/s/MhRrVW44dDX-PpWNqCWCOw
- 2020年1月,斯坦福大学新研究:声波、光波等都是RNN。https://mp.weixin.qq.com/s/_GezPrfjyhfylimrtDouCg
a. 论文地址:https://advances.sciencemag.org/content/5/12/eaay6946
b. GitHub 地址:https://github.com/fancompute/wavetorch
脉冲神经网络(Spiking neural network, SNN)
- 2021年5月,人工神经网络秒变脉冲神经网络,新技术有望开启边缘AI计算新时代。https://mp.weixin.qq.com/s/9cLJphsHYKGt7RvKtqYvsg
a. 论文:https://arxiv.org/abs/2002.00860
b. 代码:https://github.com/christophstoeckl/FS-neurons
c. 能更好模仿生物神经系统运行机制的脉冲神经网络在发展速度和应用范围上都还远远落后于深度学习人工神经网络(ANN),但脉冲神经网络的低功耗特性有望使其在边缘计算领域大放异彩。近日,奥地利的格拉茨技术大学理论计算机科学学院的两位研究者提出了一种可将人工神经网络转换为脉冲神经网络(SNN)的新方法,能够在保证准确度的同时有效地将 ANN 模型转换成 SNN 模型。该技术有望极大扩展人工智能的应用场景。
时间卷积网络(TCN)
- 定义:时间卷积网络(TCN),是用于序列建模任务的卷积神经网络的变体,结合了 RNN 和 CNN 架构。对 TCN 的初步评估表明,简单的卷积结构在多个任务和数据集上的性能优于典型循环网络(如 LSTM),同时表现出更长的有效记忆。
TCN 的特征是:
a. TCN 架构中的卷积是因果卷积,这意味着从将来到过去不存在信息「泄漏」;
b. 该架构可以像 RNN 一样采用任意长度的序列,并将其映射到相同长度的输出序列。通过结合非常深的网络(使用残差层进行增强)和扩张卷积,TCN 具有非常长的有效历史长度(即网络能够看到很久远的过去,并帮助预测)。 - 2020年9月,告别RNN,迎来TCN!股市预测任务是时候拥抱新技术了。https://mp.weixin.qq.com/s/hE0elaJcywb084rmWZzTAw
深度深林(Deep Forest)
- 2021年1月,南大周志华团队开源深度森林软件包DF21:训练效率高、超参数少,普通设备就能跑。https://mp.weixin.qq.com/s/r0HR2WcH6u7D-Hmo8g3P1Q
a. 项目地址:http://www.lamda.nju.edu.cn/deep-forest/
b. Github 地址:https://github.com/LAMDA-NJU/Deep-Forest
c. Gitee 地址:https://gitee.com/lamda-nju/deep-forest - 2019年11月,周志华团队:深度森林挑战多标签学习,9大数据集超越传统方法。https://mp.weixin.qq.com/s/AwvSTF8j0AinS-EgmPFJTA
a. https://github.com/kingfengji/gcForest - multi-Grained Cascade Forest(gcForest):基于决策树森林的方法
a. 2019年8月,周志华:“深”为什么重要,以及还有什么深的网络。https://mp.weixin.qq.com/s/T9MjdT2r9KSXZAxAEcm6mA - 2017年3月,周志华最新论文挑战深度学习 | 深度森林:探索深度神经网络以外的方法。https://mp.weixin.qq.com/s/OhzIgwPXu0Uy-dsgbQN4nw
a. https://arxiv.org/abs/1702.08835 - 2017年9月,【周志华深度森林第二弹】首个基于森林的自编码器,性能优于DNN。https://mp.weixin.qq.com/s/dEmox_pi6KGXwFoevbv14Q
a. https://arxiv.org/pdf/1709.09018.pdf - 2018年6月,【深度森林第三弹】周志华等提出梯度提升决策树再胜DNN。https://mp.weixin.qq.com/s/KlDlXzFd-1YgZxRFpbvCPw
a. https://arxiv.org/pdf/1806.00007.pdf - 多层GBDT森林(mGBDT)
a. 作者冯霁、俞扬和周志华提出了一种新颖的具有显式表示学习能力的多层GBDT森林(mGBDT),它可以与目标传播(target propagation)的变体进行共同训练。由于树集成(tree ensembles)的优异性能,这种方法在很多神经网络不适合的应用领域中具有巨大的潜力。这项工作还表明,一个不可微分的系统,也能够具有可微分系统的关键功能(多层表示学习,并首次证明了可以使用树来获得分层和分布式的表示)。理论证明和实验结果都表明了该方法的有效性。2018年6月,论文Multi-Layered Gradient Boosting Decision Trees.pdf
新型神经元模型 FT(Flexible Transmitter)、 FTNet (Flexible Transmitter Network)
- 2020年4月,神经网络的基础是MP模型?南大周志华组提出新型神经元模型FT。https://mp.weixin.qq.com/s/o0UivCMsYxyKKjPlCABZ4Q
a. https://arxiv.org/pdf/2004.03839v2.pdf
加法网络(AdderNet)
- 2020年1月,只有加法也能做深度学习,北大、华为等提出AdderNet,性能不输传统CNN。https://mp.weixin.qq.com/s/mL7EMzT7c9mTvqyyr3yLPg
a. https://arxiv.org/abs/1511.00363
b. 如何让避免CNN中的乘法呢?研究人员使用L1了距离。L1距离是两点坐标差值的绝对值之和,不涉及乘(下图的蓝色折线)
i.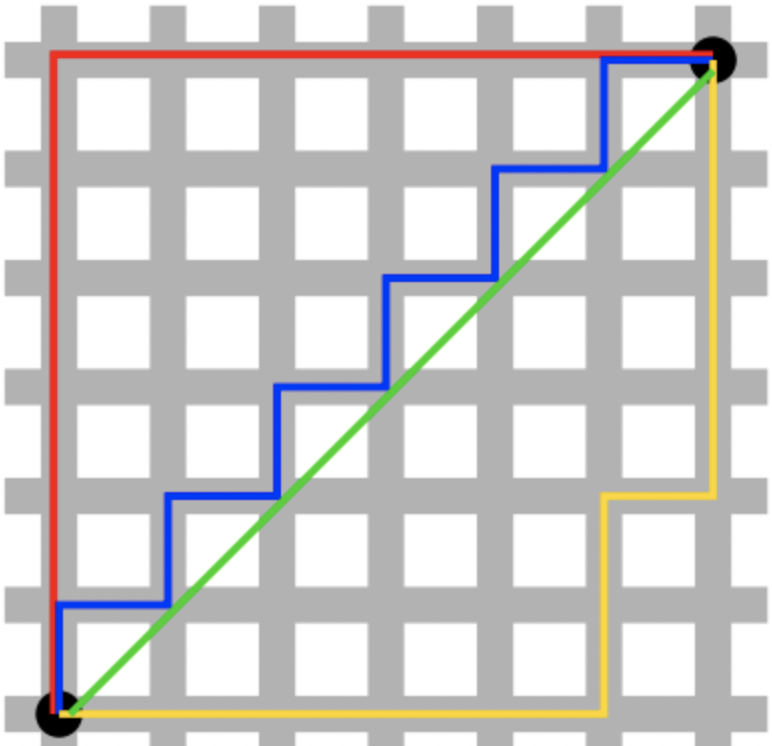
c. 相关思想文章:
i. 2020年1月,华为深度学习新模型DeepShift:移位和求反代替乘法,神经网络成本大降。https://mp.weixin.qq.com/s/K_b4Kl7AG4xecTx8p3YJTg
1. https://arxiv.org/pdf/1905.13298.pdf
向量网络(VectorNet)
- 2020年5月,谷歌中国工程师团队提出颠覆性算法模型,Waymo实测可提高预测精准度,https://mp.weixin.qq.com/s/FKmCALH1eHGy7kW-WH-klg
a. 来自 Waymo 和谷歌的一个中国工程师团队提出了一个全新模型 VectorNet。在该模型中,团队首次提出了一种抽象化认识周围环境信息的做法:用向量(Vector)来简化地表达地图信息和移动物体,这一做法抛开了传统的用图片渲染的方式,达到了降低数据量、计算量的效果。
b. https://blog.waymo.com/2020/05/vectornet.html
变换结构/网络(Transformer)
- 概念:
a. Transformer由论文《Attention is All You Need》提出,Attention is All You Need:https://arxiv.org/abs/1706.03762
i. Transformer 整体结构宏观上看是一个Encoder-Decoder结构,只不过这个结构完全抛弃了常见的RNN、LSTM等结构。
ii. 更多介绍和说明:https://jalammar.github.io/illustrated-transformer/ - 2021年9月,Transformer又出新变体∞-former:无限长期记忆,任意长度上下文。https://mp.weixin.qq.com/s/xlIy5Zsy9UWIO8SqBVT5CA
a. https://arxiv.org/pdf/2109.00301.pdf
b. 来自 DeepMind 等机构的研究者提出了一种名为 ∞-former 的模型,它是一种具备无限长期记忆(LTM)的 Transformer 模型,可以处理任意长度的上下文。 - 2021年8月,一年六篇顶会的清华大神提出Fastformer:史上最快、效果最好的Transformer。https://mp.weixin.qq.com/s/6hqnobLFzJRaSCGhMoZQhg,https://mp.weixin.qq.com/s/0ry_vWjYeLV1S0NqzKtUfw
a. https://arxiv.org/abs/2108.09084
b. 加性注意力机制、训练推理效率优于其他Transformer变体。基于additive attention能够以线性复杂度来建立上下文信息。而不是自注意力(self-attention)机制那样,对于输入长度为N的文本,时间复杂度达到二次O(N^2)。 - 2021年7月,Transformer+CNN=sota!上限和下限都很高,Facebook AI一个门控就搞定,https://mp.weixin.qq.com/s/eEXUbGXlOBWN24O7vZcf3Q
a. Facebook AI Research在法国的分部最近提出了一种新的计算机视觉模型 ConViT,它结合了这两种常用的模型——卷积神经网络(CNNs)和Transformer,以克服它们各自的局限性。
b. https://ai.facebook.com/blog/computer-vision-combining-transformers-and-convolutional-neural-networks
c. https://github.com/facebookresearch/convit - 2021年7月,ACL 2021 | 字节跳动Glancing Transformer:惊鸿一瞥的并行生成模型。https://mp.weixin.qq.com/s/RuKc9gS26-kCUpifQ-xNYg
a. 论文地址:https://arxiv.org/abs/2008.07905
b. 代码地址:https://github.com/FLC777/GLAT - 2021年7月,UC伯克利华人一作:卷积让视觉Transformer性能更强,ImageNet 继续刷点!https://mp.weixin.qq.com/s/qHI-OCOcGAbQvXqihgAK2w
a. Convolutional stem is all you need! Facebook AI和UC伯克利联手,探究视觉Transformer优化不稳定的本质原因,只需把patchify stem替换成convolutional stem,视觉Transformer就会性能更强,训练更稳定!
b. https://arxiv.org/abs/2106.14881 - 2021年7月,革新Transformer!清华大学提出全新Autoformer骨干网络,长时序预测达到SOTA。https://mp.weixin.qq.com/s/1pIbSJPP_ehw-oEQ0DH7Aw
a. https://arxiv.org/abs/2106.13008
b. 清华大学软件学院机器学习实验室另辟蹊径,基于随机过程经典理论,提出全新Autoformer架构,包括深度分解架构及全新自相关机制,长序预测性能平均提升38%。 - 2021年6月,Transformer模型有多少种变体?复旦邱锡鹏教授团队做了全面综述。https://mp.weixin.qq.com/s/-nX_sVeMVnZ0THGa7-jITQ
a. A Survey of Transformers。https://arxiv.org/pdf/2106.04554.pdf - 2021年6月,苹果公司华人研究员抛弃注意力机制,史上最快的Transformer!新模型达成最低时间复杂度。https://mp.weixin.qq.com/s/9fEKdcffZh-jiFX_3Z3gVg
a. 无需注意力机制的Transformer,即Attention Free Transformer (ATF)。https://www.reddit.com/r/MachineLearning/comments/npmq5j/r_an_attention_free_transformer/ - 2021年4月,CNN+Transformer=SOTA!CNN丢掉的全局信息,Transformer来补。https://mp.weixin.qq.com/s/qXjwFCm0N_7yJAU087Xvqg
a. CvT是一种结合了CNN结构和Transformers结构各自优势的全新基础网络,实验结果也验证了CvT在ImageNet以及各种分类任务中的有效性。
b. https://arxiv.org/pdf/2103.15808.pdf - 2021年3月,Transformer变体为何无法应用于多种任务?谷歌:这些架构更改不能有效迁移。https://mp.weixin.qq.com/s/sIJde7sGdypPPPO0V3GYiQ
a. https://arxiv.org/pdf/2102.11972.pdf - 2021年 3月,LSTM之父重提30年前的「快速权重存储系统」:线性Transformer只是它的一种变体。https://mp.weixin.qq.com/s/-exYGDS8MfwM0clzJMia4g
a. 论文链接:https://arxiv.org/abs/2102.11174
b. 代码地址:https://github.com/ischlag/fast-weight-transformers - 2021年2月,Hinton发布44页最新论文「独角戏」GLOM,表达神经网络中部分-整体层次结构。https://mp.weixin.qq.com/s/aWxiugN6XGJxc0kU2jW_7Q
a. Hinton的最新论文中,他提出GLOM,通过提出island的概念来表示解析树的节点,可以显著提升transformer类模型的可解释性
b. https://arxiv.org/abs/2102.12627 - 2021年1月,堪比当年的LSTM,Transformer引燃机器学习圈:它是万能的。https://mp.weixin.qq.com/s/eZkah2-ropH7du9aYHHmwg
- 2020年11月,六项任务、多种数据类型,谷歌、DeepMind提出高效Transformer评估基准。https://mp.weixin.qq.com/s/oqbtFsExIVUe3Y5KU-p7FA
a. 基准项目地址:https://github.com/google-research/long-range-arena
b. 论文地址:https://arxiv.org/pdf/2011.04006.pdf - 2020年9月,高效Transformer层出不穷,谷歌团队综述文章一网打尽。https://mp.weixin.qq.com/s/tO1MTAASm-3oPd4ueQapaw
a. https://arxiv.org/pdf/2009.06732.pdf - 2020年7月,GitHub超3万星:Transformer 3发布,BERT被一分为二。https://mp.weixin.qq.com/s/tO6_I26Xkc_QTZk4ljzUnw
a. https://github.com/huggingface/transformers/releases/tag/v3.0.0 - Transformer-XL( 2.77 亿参数):CMU和谷歌联手放出XL号Transformer!提速1800倍,https://baijiahao.baidu.com/s?id=1622705404063513524&wfr=spider&for=pc
a. 论文地址:https://arxiv.org/abs/1901.02860,项目地址:https://github.com/kimiyoung/transformer-xl - Transfomer介绍及与RNN和CNN等作为特征抽取的对比:自然语言处理三大特征抽取器(CNN/RNN/TF)比较(鼓励全面拥抱transformer)。
a. https://mp.weixin.qq.com/s/WFl-DQkFI5VESjMGvlmjng,https://mp.weixin.qq.com/s/ZAJavUhMNIiWlHeQOKq8TA - Transformer各层网络结构详解!https://mp.weixin.qq.com/s/ZlUWSj_iYNm7qkNF9rm2Xw
a. Transformer模型详解:https://blog.csdn.net/u012526436/article/details/86295971
b. 图解Transformer(完整版):https://blog.csdn.net/longxinchen_ml/article/details/86533005
c. 关于Transformer的若干问题整理记录:https://www.nowcoder.com/discuss/258321 - 2019年10月,Transformers 研究指南。https://mp.weixin.qq.com/s/oOyh3JdvyrnT-ZTWMthq5Q
- 解密:OpenAI和DeepMind都用的Transformer是如何工作的。https://mp.weixin.qq.com/s/t4QPdzIRpkq-Pgz5RJCliA
a. Transformer 是为解决序列转换或神经机器翻译问题而设计的架构,该任务将一个输入序列转化为一个输出序列。 语音识别、文本转语音等问题都属于这类任务。
b. https://towardsdatascience.com/transformers-141e32e69591 - 2019年2月,全面拥抱transformer。自然语言处理三大特征抽取器(CNN/RNN/TF)比较的两篇优质介绍和分析文章
a. https://mp.weixin.qq.com/s/WFl-DQkFI5VESjMGvlmjng,https://mp.weixin.qq.com/s/ZAJavUhMNIiWlHeQOKq8TA
内卷(Involution)
- 2021年3月,超越卷积、自注意力机制:强大的神经网络新算子involution。https://mp.weixin.qq.com/s/UmumqhZW7Aqk6s8X1Aj7aA
a. 提出了一种新的神经网络算子(operator或op)称为involution,它比convolution更轻量更高效,形式上比self-attention更加简洁,可以用在各种视觉任务的模型上取得精度和效率的双重提升。
b. 通过involution的结构设计,我们能够以统一的视角来理解经典的卷积操作和近来流行的自注意力操作。
c. 论文链接:https://arxiv.org/abs/2103.06255
d. 代码和模型链接:https://github.com/d-li14/involution
先天结构(Preexisting structures,Neuroscience)
- 2021年10月,美国「脑计划」新里程碑!Nature 连发16篇论文,绘制最全脑细胞地图。https://mp.weixin.qq.com/s/KUrRZ0wqD_tc6AyU-mX3ng
a. https://alleninstitute.org/what-we-do/brain-science/news-press/press-releases/ultra-detailed-map-brain-region-controls-movement-mice-monkeys-humans
b. https://www.nature.com/articles/d41586-021-02493-8
c. Nature 论文合辑:https://www.nature.com/collections/cicghheddj - 2021年9月,骆利群院士最新Science综述:神经环路架构,激发新的AI。https://mp.weixin.qq.com/s/e07ALtZnASWDkhV1w5gzsw
a. https://www.science.org/doi/10.1126/science.abg7285
b. 回顾了在不同大脑区域和动物物种中使用的常见环路模体(circuit motifs)和环路架构计划。作者认为,了解突触连接的特定模式如何实现特定的神经计算,有助于弥合单个神经元生物学与整个大脑功能之间的巨大差距,使我们能够更好地理解行为的神经基础,并可能激发人工智能的新进展。
c. 常见的环路模体有四种:前馈激活(Feedforward excitation)、前馈抑制和反馈抑制(Feedforward and feedback inhibition)、横向抑制(Lateral inhibition)、相互抑制(Mutual inhibition)。 - 2021年9月,一个神经元顶5到8层神经网络,深度学习的计算复杂度被生物碾压了。https://mp.weixin.qq.com/s/Dvk5IQiD4H5u_KHrRnR82g
a. 论文地址:https://www.sciencedirect.com/science/article/abs/pii/S0896627321005018 - 2021年7月,南京大学缪峰团队提出迄今最高并行度神经形态类脑计算方案,或颠覆冯诺依曼架构计算范式。https://mp.weixin.qq.com/s/dmlEiFO5He2Ks_JutwsbiA
- 2021年6月,Google Research研讨议题:哥德尔奖、高德纳奖得主解析「大脑中的文字表征」。https://mp.weixin.qq.com/s/jCkeS7rdH4zoF2kAr3JVXw
- 2020年10月,人脑与卷积神经网络的诡异对应,识别三维图形反应模式非常相似。https://mp.weixin.qq.com/s/0-ek5Tagp-0adMPi8fcRxA
- 2020年10月,清华首次提出「类脑计算完备性」及计算系统层次结构,登上Nature。https://mp.weixin.qq.com/s/desOYisVuPdl4xgxy6v-5Q
a. 「类脑计算完备性」(neuromorphic completenes)
b.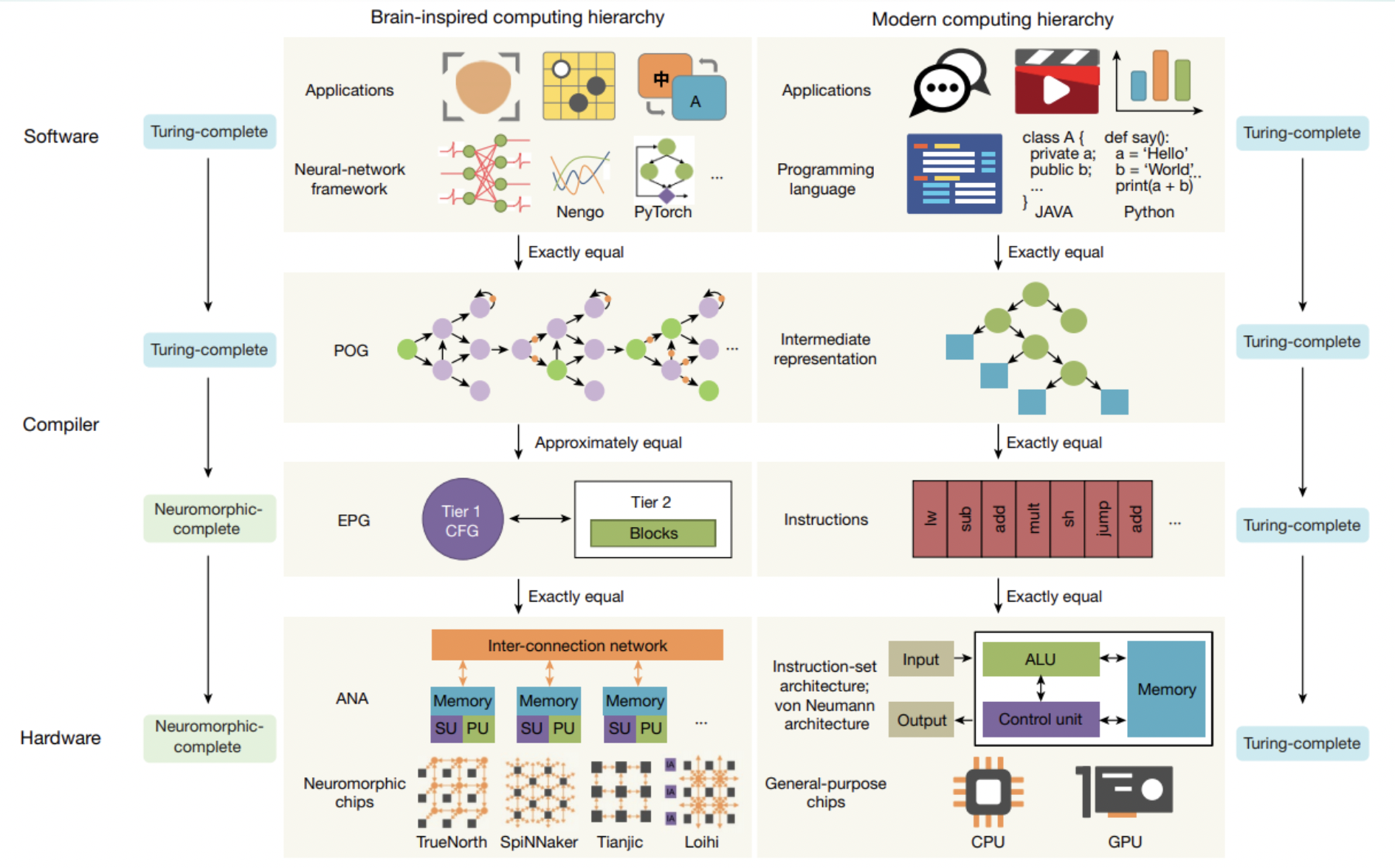
- 2020年9月,浙大重磅发布亿级神经元类脑计算机:基于 792 颗自研「达尔文 2 代」芯片,可“意念”打字。https://mp.weixin.qq.com/s/FRGrt9qKm5e4iuzwTjTieQ
a. https://mp.weixin.qq.com/s/LQa3j33iT76YCFuYGhZSAA
b. http://ac.zju.edu.cn/2019/0827/c16466a1582995/page.htm - 2020年7月,英特尔开放其最大规模的神经拟态计算系统,神经容量相当于小型哺乳动物的大脑。https://mp.weixin.qq.com/s/k22sogjxDu3dLi2YgvRZBw
- 2020年7月,一个匪夷所思的真相:人类大脑或是高度并行的计算系统,与人工神经网络无本质差别。https://mp.weixin.qq.com/s/GvMz6WtyJ__QQoLR2tqsbw
- 2020年7月,性能大提升!新型 ANN 登上《自然》子刊:清华团队领衔打造基于忆阻器的人工树突。https://mp.weixin.qq.com/s/yGy9hLbnvPFgDMYipH6VRA
a. https://www.nature.com/articles/s41565-020-0722-5
b. https://news.tsinghua.edu.cn/info/1416/80291.htm - 2020年6月,一个匪夷所思的真相:人类大脑或是高度并行的计算系统,与人工神经网络无本质差别。https://mp.weixin.qq.com/s/GvMz6WtyJ__QQoLR2tqsbw
- 2020年6月,指尖的超算:MIT脑启发芯片登上Nature子刊。https://mp.weixin.qq.com/s/Pt76UhGZALY38p4XQHHZ7w
a. http://news.mit.edu/2020/thousands-artificial-brain-synapses-single-chip-0608
b. https://www.nature.com/articles/s41565-020-0694-5 - 2020年5月,让芯片像“人”一样思考!IBM创新芯片架构,提升分类网络准确率至93.75%。https://mp.weixin.qq.com/s/g_MfrKhgn8oJrJJvr39qoA
a. https://www.nature.com/articles/s41467-020-16108-9 - 2020年4月,深扒全球仿生芯片计划!15+公司已入局,人造大脑通往未来计算之门。https://mp.weixin.qq.com/s/VW21Q7IZOiSX9lCmw2jEFA
a.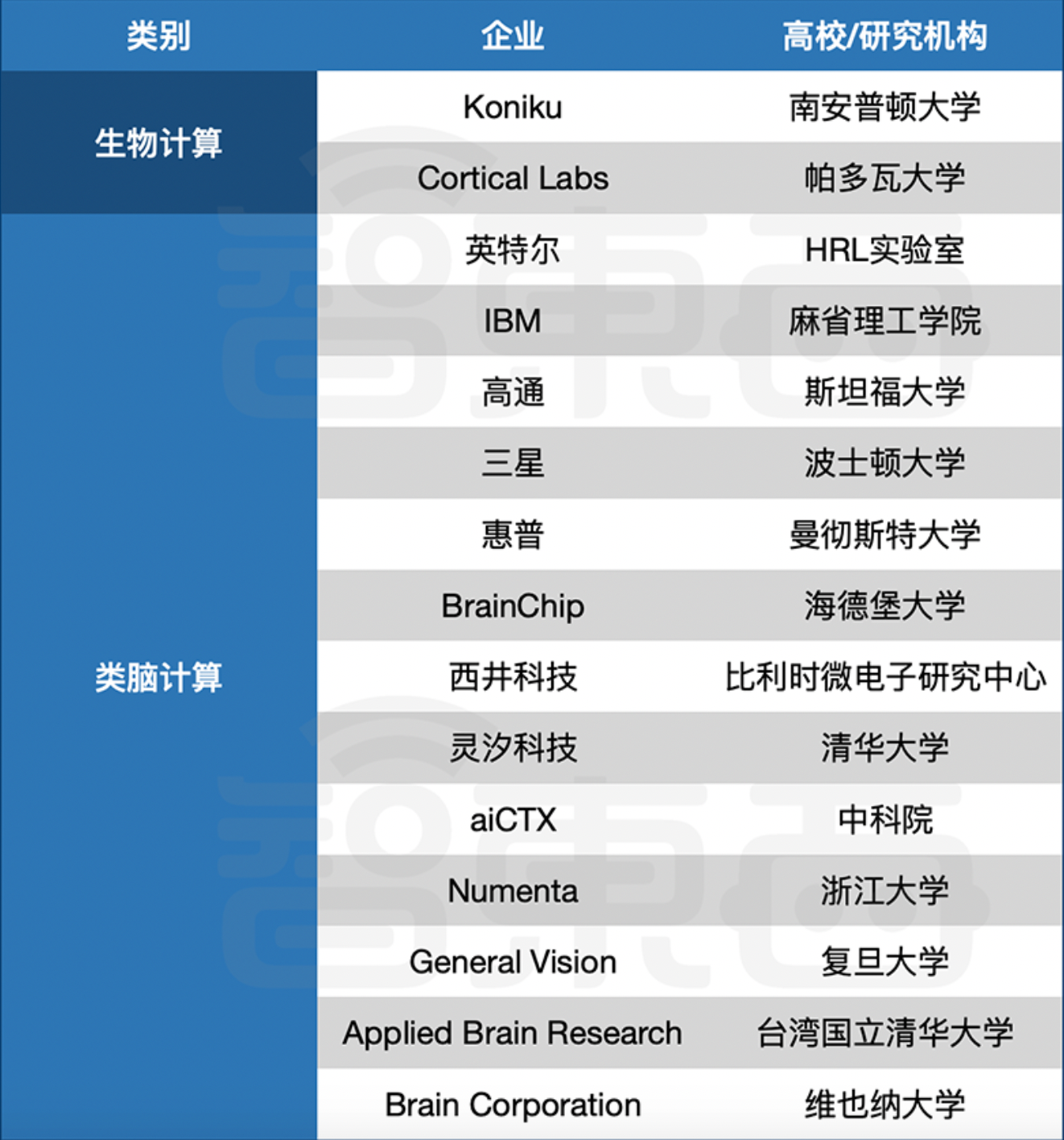
- 2020年4月,芯片造脑:华人博士一作Nature两连发,神经拟态计算竟像人脑一样「低能耗」。https://mp.weixin.qq.com/s/fEPDn_51YL2i41VJTbYZjg
a. https://www.nature.com/articles/s41467-020-15759-y - 2020年3月,1亿神经元,秒杀深度学习千倍!英特尔发布最强神经拟态计算系统。https://mp.weixin.qq.com/s/7ezMngxhdEMSm6Us15cEvw
- 2020年3月,登上Nature子刊封面:英特尔神经芯片实现在线学习。https://mp.weixin.qq.com/s/sN12X8fOg15yTlPA5iufdw
a. 来自英特尔和康奈尔大学的研究者宣布,团队已经在神经形态芯片 Loihi 上成功设计了基于大脑嗅觉电路的算法,实现了在线学习和强记忆力能力。这项研究发表在最新一期自然杂志子刊上《Nature Machine Intelligence》上,并成为封面文章。 - 2020年1月,谷歌发布史上最高分辨率大脑连接图,可覆盖果蝇大脑的三分之一。https://mp.weixin.qq.com/s/TT6VYeuNR6CD4RxEZc4t2w
- 2020年1月,模仿大脑的架构取代传统计算。https://mp.weixin.qq.com/s/gT2m-gVY_LlOCzTt1se_lA
a. https://aip.scitation.org/doi/10.1063/1.5129306 - 2020年1月,大脑只需单个神经元就可进行XOR异或运算,Science新研究揭开冰山一角。https://mp.weixin.qq.com/s/mSeO7jOJ0jr1BBXqmyVG5Q
a. 在机器学习中,异或(XOR)这样的非线性问题一直需要多层神经网络来解决。科学家一直以为,即使在人类大脑中,XOR运算也需要多层神经元网络才能计算。但是大脑远比人类想象得“高能”。最新研究发现:人类大脑只需要单个神经元就可以进行XOR运算 - 人工智能的发展离不开神经科学,先天结构或是下一个方向:https://mp.weixin.qq.com/s/cZNtUwpXQudFaM3dN1UOaw,http://science.sciencemag.org/content/363/6428/692
a. 理解和模仿相关的大脑机制,或开发从头开始的计算学习方法来发现支持智能体、人类或人工智能的结构。
b. Using neuroscience to develop artificial intelligence,http://120.52.51.17/science.sciencemag.org/content/363/6428/692.full.pdf - 2018年7月7日据《每日邮报》报道,科学家已经在实验室开发出完全由DNA组成、模拟大脑工作方式的人工神经网络。通过正确地识别手写体数字,这一试管人工智能系统能解决典型的机器学习问题。科学家称,在展示通过人造有机电路实现人工智能方面,这一研究是重要的一步。
综合及其他
- 2021年8月,Facebook、MIT等联合发表451页手稿:用「第一性原理」解释DNN。https://mp.weixin.qq.com/s/yqFamYazB50FjYPq8WWWLw
a. The Principles of Deep Learning Theory: An Effective Theory Approach to Understanding Neural Networks
b. https://arxiv.org/pdf/2106.10165.pdf - 2021年7月,谁是「反向传播之父」?Hinton曾亲口否认,真正的提出者或许是这个刚获 IEEE 认证的大佬。https://mp.weixin.qq.com/s/bUC8K88H7MWPQXTSxCiH4w
- 2021年2月,深度学习领域最常用的10个激活函数,一文详解数学原理及优缺点。https://mp.weixin.qq.com/s/bleTRzA_1X3umR5UXSpuHg
a. https://sukanyabag.medium.com/activation-functions-all-you-need-to-know-355a850d025e - 谷歌:
a. 2021年5月,更宽还是更深?Google AI:广度网络和深度网络能学到同样的东西吗?https://mp.weixin.qq.com/s/XO49wBa1_kZuhP3VLaf08Q
i. https://ai.googleblog.com/2021/05/do-wide-and-deep-networks-learn-same.html
b. 2020年8月,谷歌用算力爆了一篇论文,解答有关无限宽度网络的一切。https://mp.weixin.qq.com/s/OA-HGJLj90qIBcUvEWZbPw
i. 论文链接:https://arxiv.org/pdf/2007.15801v1.pdf
c. 2020年7月,73岁Hinton老爷子构思下一代神经网络:属于无监督对比学习。https://mp.weixin.qq.com/s/FU_UMnt_69rjK-AUgoh6Hg
d. 2019年3月,谷歌、DeepMind和OpenAI都在用的Transformer是如何工作的?https://mp.weixin.qq.com/s/yjPQyTevsHRlQudTbrk8Ig - 2018年9月,深度学习模型哪个最像人脑?由MIT、NYU、斯坦福等众多著名大学研究人员组成的团队,便提出了brain-score系统,对当今主流的人工神经网络(ANN)进行评分排名。https://mp.weixin.qq.com/s/cBJ_5Ctvn17og6MWN2T4lg
a.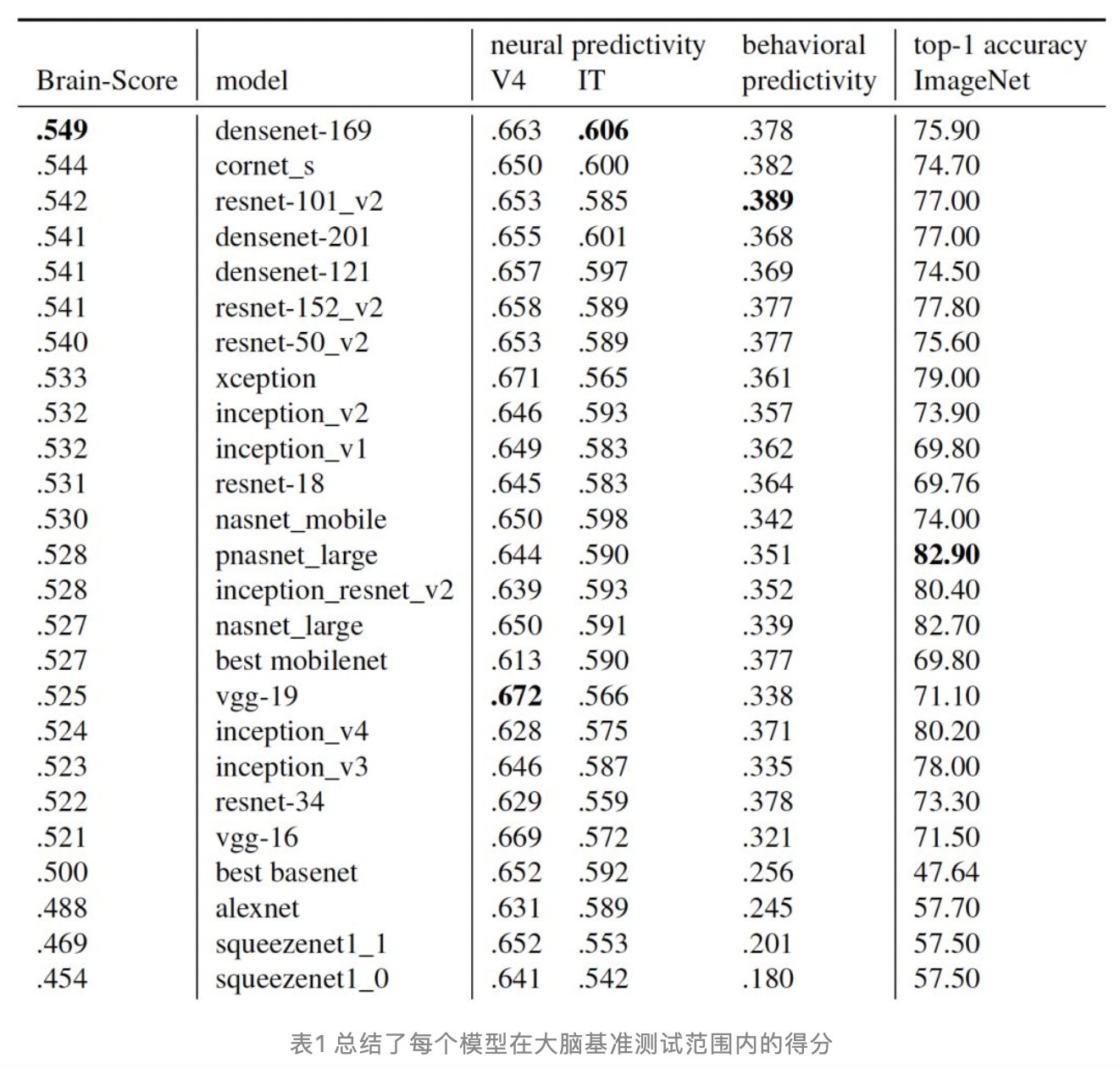
b. https://www.biorxiv.org/content/early/2018/09/05/407007