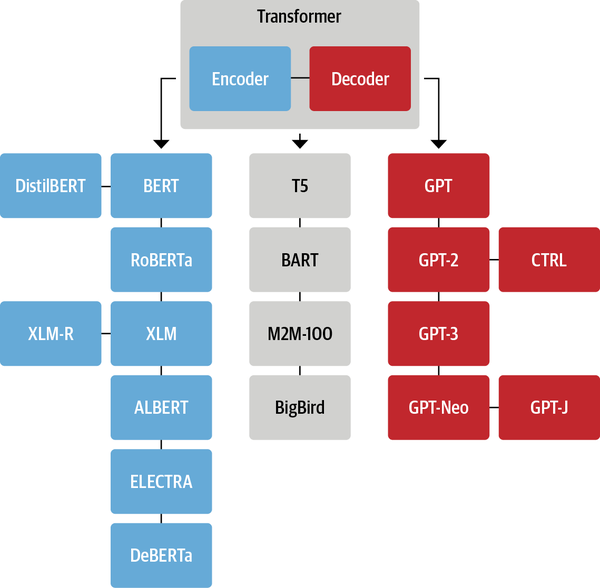
Transformer是2017年Google论文《Attention is All You Need》提出的一种模型结构,颠覆了通过RNN进行序列建模的思路,已被广泛应用于NLP各个领域,如出色的Bert、GPT都是基于Transformer模型。
论文:Attention Is All Your Need
Attention & Multi-Head Attention Arch
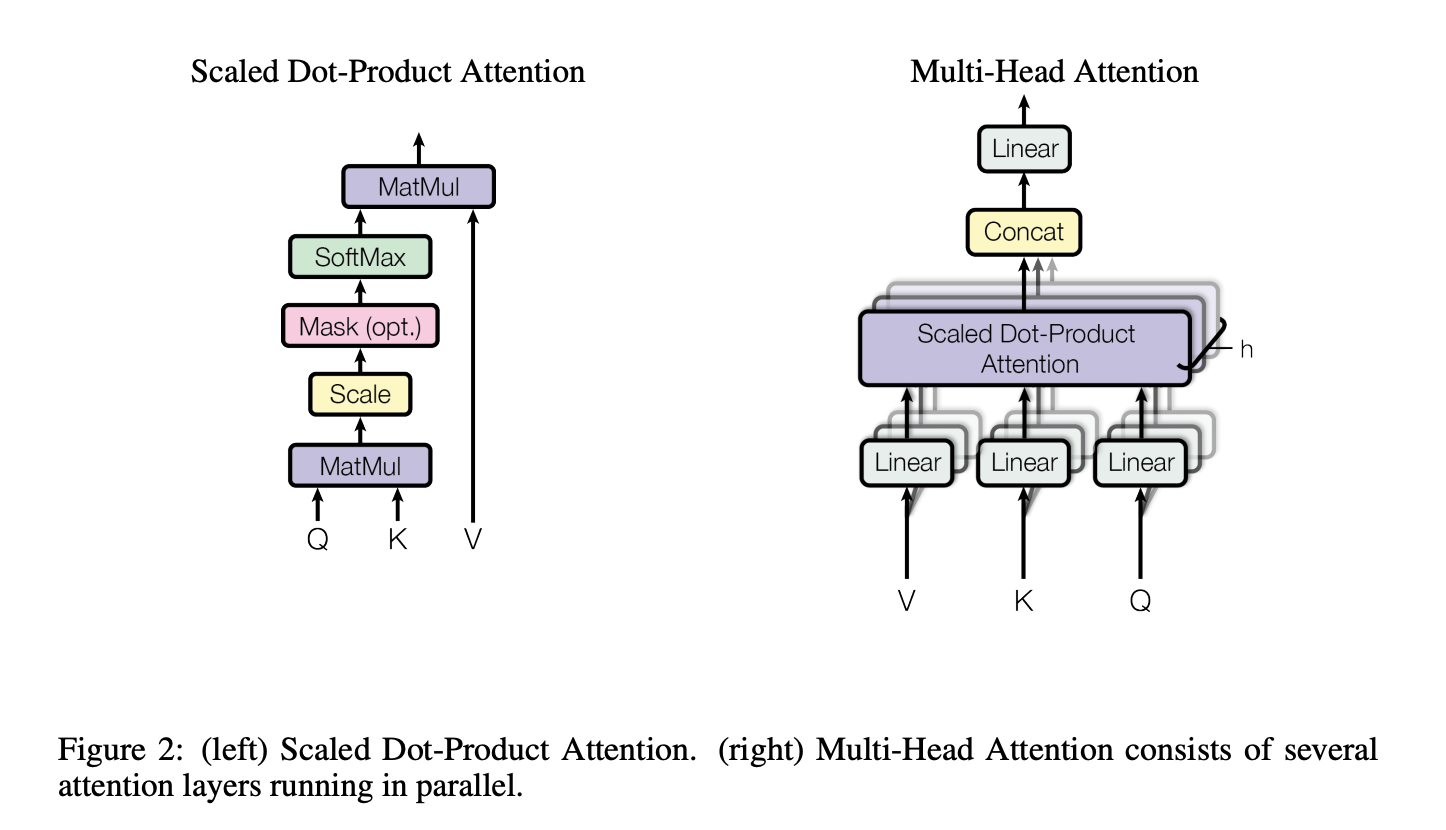
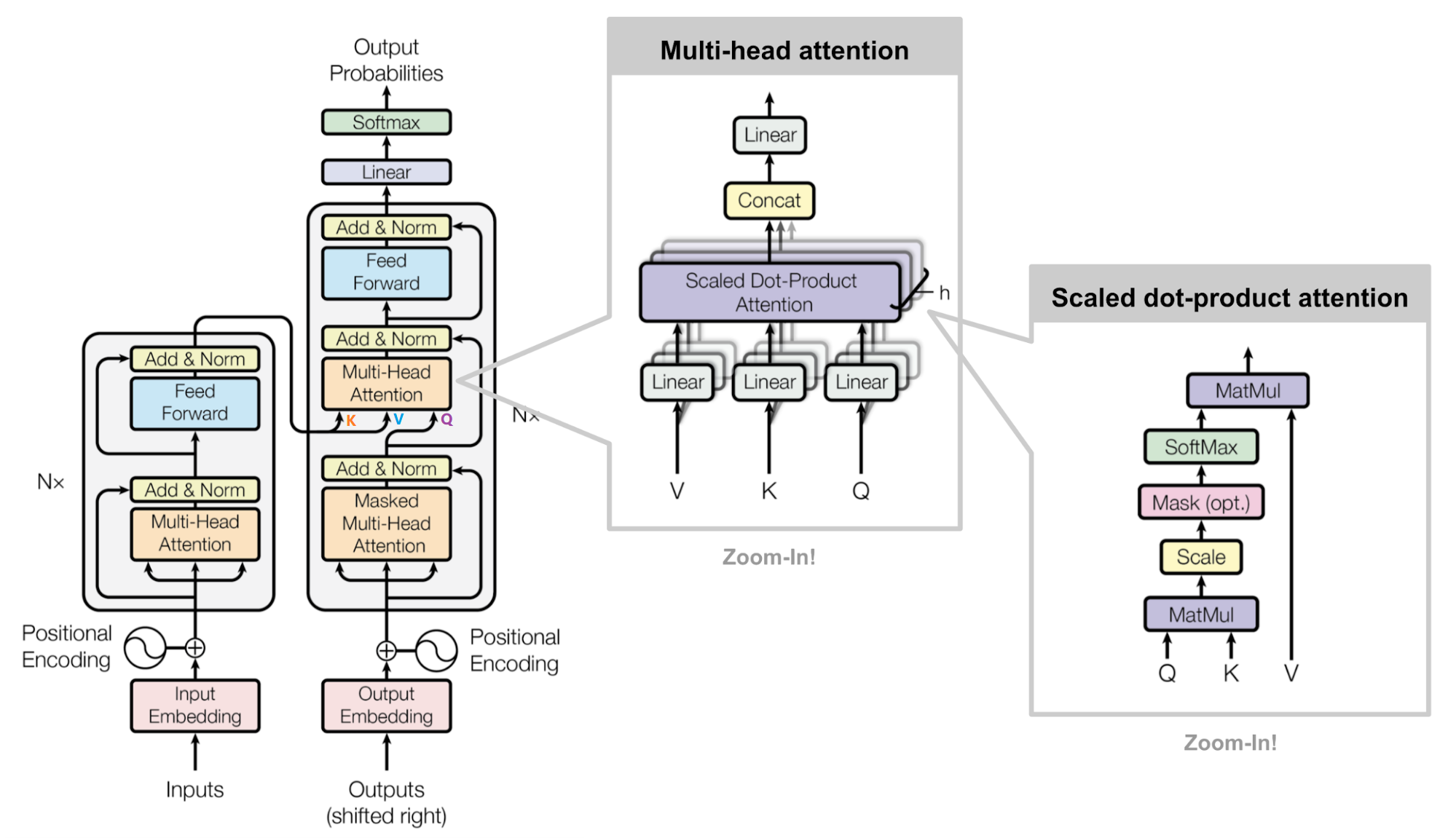
Attention & Multi-Head Attention Functions
$$ Attention(Q, K, V) = softmax \left( \frac{Q K^T}{\sqrt{d_k}} \right)V $$
$$
\begin{matrix}
MultiHead(Q, K, V) = Concat(head_1, …, head_h)W^O \\
\text{ where }head_i = Attention(QW_{i}^{Q}, KW_{i}^{K}, VW_{i}^{V})
\end{matrix}
$$
Encoder Block Arch Calc Process

1. 字向量与位置编码
$$ X = Embedding-Lookup(X) + Positional-Encoding $$
2. 自注意力机制
$$
\begin{matrix}
Q = Linear_q(X) = XW_Q \\
K = Linear_k(X) = XW_K \\
V = Linear_v(X) = XW_V \\
X_{attention} = \text{Self-Attention}(Q, K, V)
\end{matrix}
$$
3. Self-Attention残差连接与Layer Normalization
$$
\begin{matrix}
X_{attention} = X + X_{attention} \\
X_{attention} = LayerNorm(X_{attention})
\end{matrix}
$$
4. FeedForward
结构中的第4部分,两层线性变换并用激活函数ReLU。
$$ X_{hidden} = Linear(ReLU(Linear(X_{attention}))) $$
5. FeedForward残差连接与Layer Normalization
$$
\begin{matrix}
X_{hidden} = X_{attention} + X_{hidden} \\
X_{hidden} = LayerNorm(X_{hidden})
\end{matrix}
$$
其中,$$ X_{hidden}\in \mathbb{R}^{batch\_size \ * \ seq\_len \ * \ embd\_dim} $$
Decoder Block Arch Calc Process

1. 字向量与位置编码
$$ X = Embedding-Lookup(X) + Positional-Encoding $$
2. 带Masked的自注意力机制
$$ Self-Attention(Q, K, V) = softmax \left( \frac{Q K^T}{\sqrt{d_k}} + Mask \right)V $$
Mask setting to $ - \propto $ all values.
$$
\begin{matrix}
Q = Linear_q(X) = XW_Q \\
K = Linear_k(X) = XW_K \\
V = Linear_v(X) = XW_V \\
X_{attention} = \text{Self-Attention}(Q, K, V)
\end{matrix}
$$
3. Self-Attention残差连接与Layer Normalization
$$
\begin{matrix}
X_{attention} = X + X_{attention} \\
X_{attention} = LayerNorm(X_{attention})
\end{matrix}
$$
4. Multi-Head Encoder-Decoder Attention与FeedForward
与Encoder的Multi-Head Attention计算一样,只不过K,V为Encoder的输出。Q为Masked Self-Attention的输出。
$$ Attention(Q, K, V) = softmax \left( \frac{Q K^T}{\sqrt{d_k}} \right)V $$
$$
\begin{matrix}
Q = X_{attention} \\
K = X_{k-hidden} \\
V = V_{k-hidden} \\
X_{second-attention} = \text{Attention}(Q, K, V) \\
X_{second-attention} = X_{second-attention} + X_{attention} \\
X_{second-attention} = LayerNorm(X_{second-attention})
\end{matrix}
$$
5. FeedForward残差连接与Layer Normalization
$$
\begin{matrix}
X_{second-hidden} = X_{second-attention} + X_{attention} \\
X_{second-hidden} = LayerNorm(X_{second-hidden})
\end{matrix}
$$
其中,$$ X_{second-hidden}\in \mathbb{R}^{batch\_size \ * \ seq\_len \ * \ embd\_dim} $$
代码实现
Multi-Head Attention
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
| class MultiHeadAttention(nn.Module):
def __init__(self, emb_size, q_k_size, v_size, head):
super().__init__()
self.emb_size = emb_size
self.q_k_size = q_k_size
self.v_size = v_size
self.head = head
self.w_q = nn.Linear(emb_size, head * q_k_size)
self.w_k = nn.Linear(emb_size, head * q_k_size)
self.w_v = nn.Linear(emb_size, head * v_size)
def forward(self, x_q, x_k_v, attn_mask):
"""
forward
:param x_q: (batch_size, seq_len, emb_size)
:param x_k_v:
:param attn_mask:
:return:
"""
q = self.w_q(x_q)
k = self.w_k(x_k_v)
q = q.view(q.size()[0], q.size()[1], self.head, self.q_k_size).transpose(1, 2)
k = k.view(k.size()[0], k.size()[1], self.head, self.q_k_size).transpose(1, 2).transpose(2, 3)
attn = torch.matmul(q, k) / math.sqrt(self.q_k_size)
attn_mask = attn_mask.unsqueeze(1).expand(-1, self.head, -1, -1)
attn_mask = attn_mask.to(torch.bool)
print("attn_mask1:", attn_mask)
attn = attn.masked_fill(attn_mask, -1e9)
print("attn:", attn)
attn = torch.softmax(attn, dim=-1)
v = self.w_v(x_k_v)
v = v.view(v.size()[0], v.size()[1], self.head, self.v_size).transpose(1, 2)
z = torch.matmul(attn, v)
z = z.transpose(1, 2)
return z.reshape(z.size()[0], z.size()[1], -1)
|
Encoder
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
| class EncoderBlock(nn.Module):
def __init__(self, emb_size, q_k_size, v_size, f_size, head):
super().__init__()
self.multihead_attn = MultiHeadAttention(emb_size, q_k_size, v_size, head)
self.z_linear = nn.Linear(head * v_size, emb_size)
self.addnorm1 = nn.LayerNorm(emb_size)
self.feedforward = nn.Sequential(nn.Linear(emb_size, f_size), nn.ReLU(), nn.Linear(f_size, emb_size))
self.addnorm2 = nn.LayerNorm(emb_size)
def forward(self, x, attn_mask):
"""
forward
:param x: (batch_size, seq_len, emb_size)
:param attn_mask:
:return:
"""
z = self.multihead_attn(x, x, attn_mask)
z = self.z_linear(z)
output1 = self.addnorm1(z + x)
z = self.feedforward(output1)
return self.addnorm2(z + output1)
class Encoder(nn.Module):
def __init__(self, vocab_size, emb_size, q_k_size, v_size, f_size, head, nblocks, dropout=0.1, seq_max_len=5000):
super().__init__()
self.emb = EmbeddingWithPosition(vocab_size, emb_size, dropout, seq_max_len)
self.encoder_blocks = nn.ModuleList()
for _ in range(nblocks):
self.encoder_blocks.append(EncoderBlock(emb_size, q_k_size, v_size, f_size, head))
def forward(self, x):
pad_mask = (x == PAD_IDX).unsqueeze(1)
pad_mask = pad_mask.expand(x.size()[0], x.size()[1], x.size()[1])
pad_mask = pad_mask.to(DEVICE)
x = self.emb(x)
for block in self.encoder_blocks:
x = block(x, pad_mask)
return x
|
Decoder
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
| class DecoderBlock(nn.Module):
def __init__(self, emb_size, q_k_size, v_size, f_size, head):
super().__init__()
self.first_multihead_attn = MultiHeadAttention(emb_size, q_k_size, v_size, head)
self.z_linear1 = nn.Linear(head * v_size, emb_size)
self.addnorm1 = nn.LayerNorm(emb_size)
self.second_multihead_attn = MultiHeadAttention(emb_size, q_k_size, v_size, head)
self.z_linear2 = nn.Linear(head * v_size, emb_size)
self.addnorm2 = nn.LayerNorm(emb_size)
self.feedforward = nn.Sequential(nn.Linear(emb_size, f_size), nn.ReLU(), nn.Linear(f_size, emb_size))
self.addnorm3 = nn.LayerNorm(emb_size)
def forward(self, x, encoder_z, first_attn_mask, second_attn_mask):
z = self.first_multihead_attn(x, x, first_attn_mask)
z = self.z_linear1(z)
output1 = self.addnorm1(z + x)
z = self.second_multihead_attn(output1, encoder_z, second_attn_mask)
z = self.z_linear2(z)
output2 = self.addnorm2(z + output1)
z = self.feedforward(output2)
return self.addnorm3(z + output2)
class Decoder(nn.Module):
def __init__(self, vocab_size, emb_size, q_k_size, v_size, f_size, head, nblocks, dropout=0.1, seq_mex_len=5000):
super().__init__()
self.emb = EmbeddingWithPosition(vocab_size, emb_size, dropout, seq_mex_len)
self.decoder_blocks = nn.ModuleList()
for _ in range(nblocks):
self.decoder_blocks.append(DecoderBlock(emb_size, q_k_size, v_size, f_size, head))
self.linear = nn.Linear(emb_size, vocab_size)
def forward(self, x, encoder_z, encoder_x):
"""
forward
:param x: (batch_size, seq_len)
:param encoder_z:
:param encoder_x:
:return:
"""
first_attn_mask = (x == PAD_IDX).unsqueeze(1).expand(x.size()[0], x.size()[1], x.size()[1]).to(DEVICE)
first_attn_mask = first_attn_mask | torch.triu(torch.ones(x.size()[1], x.size()[1]), diagonal=1).bool().unsqueeze(0).expand(x.size()[0], -1, -1).to(DEVICE)
second_attn_mask = (encoder_x == PAD_IDX).unsqueeze(1).expand(encoder_x.size()[0], x.size()[1], encoder_x.size()[1]).to(DEVICE)
x = self.emb(x)
for block in self.decoder_blocks:
x = block(x, encoder_z, first_attn_mask, second_attn_mask)
return self.linear(x)
|