AIGC-大模型微调-PEFT技术简介
条评论最近,基于LLama2对垂类领域的数据集做了LoRA微调,在微调过程中,系统学习了下微调方案,并对Fine Tuning方案做了对比总结。
因大模型预训练成本高昂,需要庞大的计算资源和大量的数据资源,一般个人和小企业难以承受(百度、头条花了上百亿购买显卡)。为解决这一问题,谷歌率先提出Parameter-Efficient Fine-Tuning (PEFT)技术,旨在通过最小化微调参数的数量和计算复杂度,来提高预训练模型在新任务上的性能,从而缓解大型预训练模型的训练成本。这样一来,即使计算资源受限,也可以利用预训练模型的知识来迅速适应新任务,实现高效的迁移学习。 因此PEFT技术在提升大模型效果的同时,缩短模型训练时间和成本。
关于微调
- 数据量少, 但数据相似度非常高;在这种情况下, 只修改最后几层或最终的softmax图层的输出类别。
- 数据量少, 数据相似度低;冻结预训练模型的初始层(比如k层), 并再次训练剩余的(n-k)层。由于新数据集的相似度较低, 因此根据新数据集对较高层进行重新训练具有重要意义。
- 数据量大, 数据相似度低;大的数据集对神经网络训练将会很有效。但由于数据与用于训练我们的预训练模型的数据相比有很大不同,使用预训练模型进行的预测不会有效。因此, 最好根据数据从头开始训练神经网络(Training from scatch)
- 数据量大, 数据相似度高;这是理想情况,在这种情况下, 预训练模型应该是最有效的。使用模型的最好方法是保留模型的体系结构和模型的初始权重。然后, 可以使用在预先训练的模型中的权重来重新训练该模型。
PEFT方法
Adapter Tuning
谷歌的研究人员首次在论文《Parameter-Efficient Transfer Learning for NLP》提出针对BERT的PEFT微调方式,拉开了PEFT研究的序幕。他们指出,在面对特定的下游任务时,如果进行Full-fintuning(即预训练模型中的所有参数都进行微调),太过低效;而如果采用固定预训练模型的某些层,只微调接近下游任务的那几层参数,又难以达到较好的效果。
于是他们设计了如下图所示的Adapter结构,将其嵌入Transformer的结构里面,在训练时,固定住原来预训练模型的参数不变,只对新增的Adapter结构进行微调。同时为了保证训练的高效性(也就是尽可能少的引入更多参数),他们将Adapter设计为这样的结构:首先是一个down-project层将高维度特征映射到低维特征,然后过一个非线形层之后,再用一个up-project结构将低维特征映射回原来的高维特征;同时也设计了skip-connection结构,确保了在最差的情况下能够退化为identity。

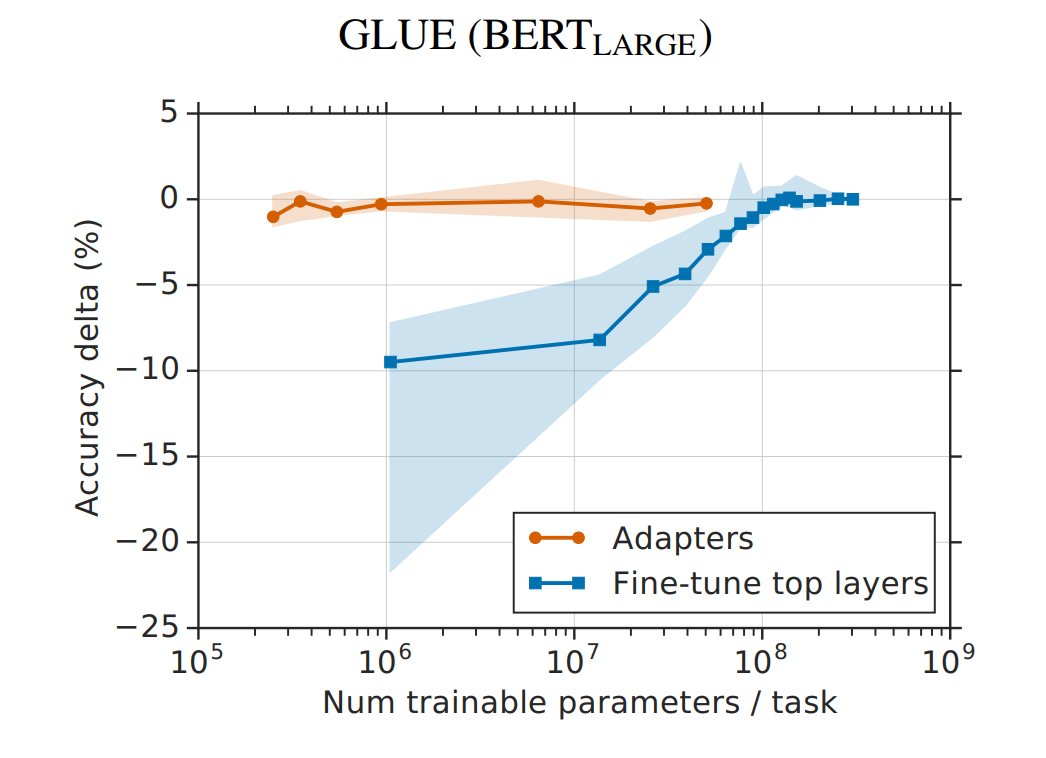
从实验结果来看,该方法能够在只额外对增加的3.6%参数规模(相比原来预训练模型的参数量)的情况下取得和Full-finetuning接近的效果(GLUE指标在0.4%以内)。
Prefix Tuning
论文&Code
- Prefix-Tuning: Optimizing Continuous Prompts for Generation
- https://github.com/XiangLi1999/PrefixTuning
1 | peft_config = PrefixTuningConfig(task_type="SEQ_CLS", num_virtual_tokens=20) |
介绍
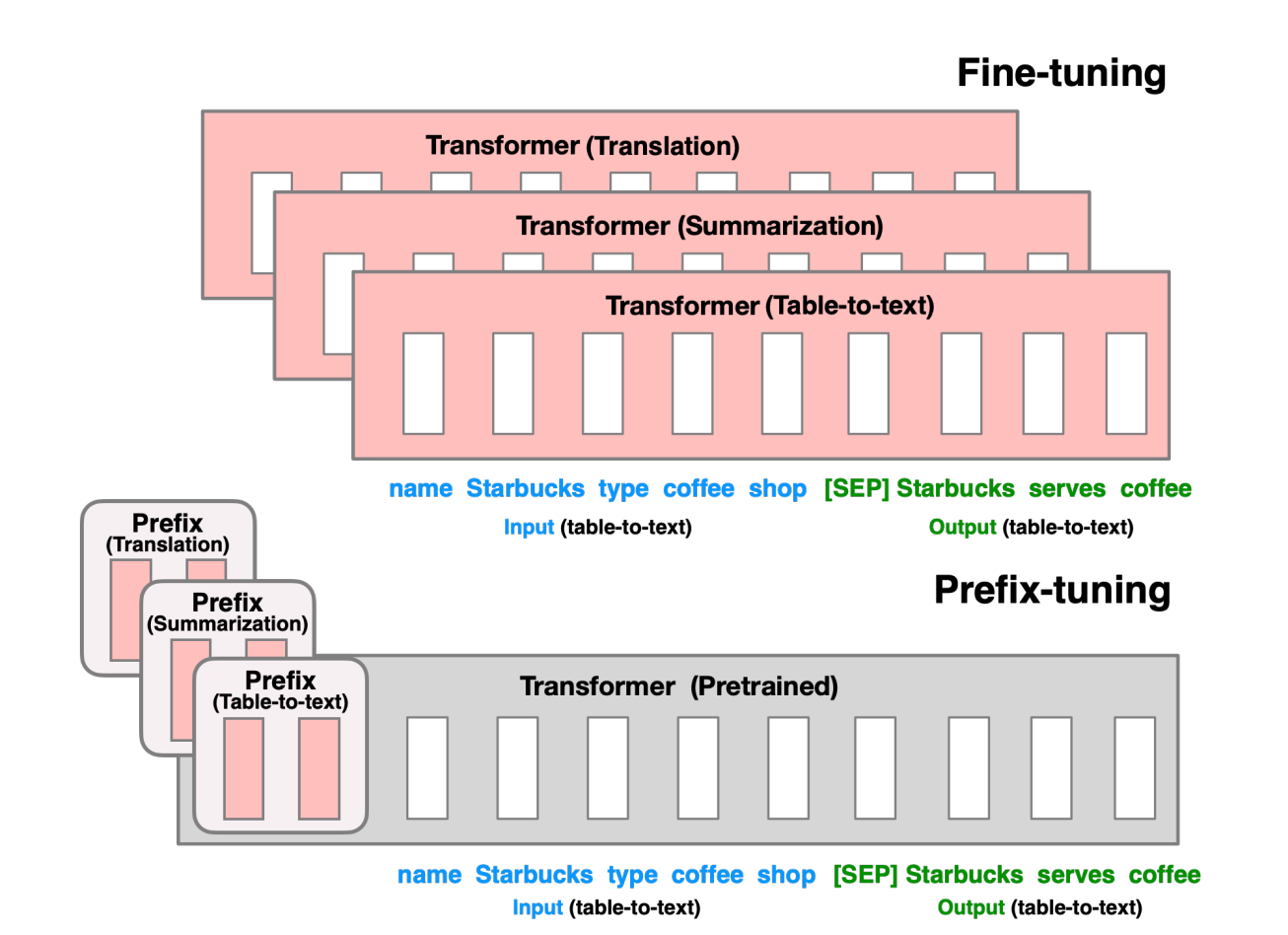
Prefix Tuning方法由斯坦福的研究人员提出,与Full-finetuning更新所有参数的方式不同,该方法是在输入token之前构造一段任务相关的virtual tokens作为Prefix,然后训练的时候只更新Prefix部分的参数,而Transformer中的其他部分参数固定。该方法其实和构造Prompt类似,只是Prompt是人为构造的“显式”的提示,并且无法更新参数,而Prefix则是可以学习的“隐式”的提示。
同时,为了防止直接更新Prefix的参数导致训练不稳定的情况,他们在Prefix层前面加了MLP结构(相当于将Prefix分解为更小维度的Input与MLP的组合后输出的结果),训练完成后,只保留Prefix的参数。
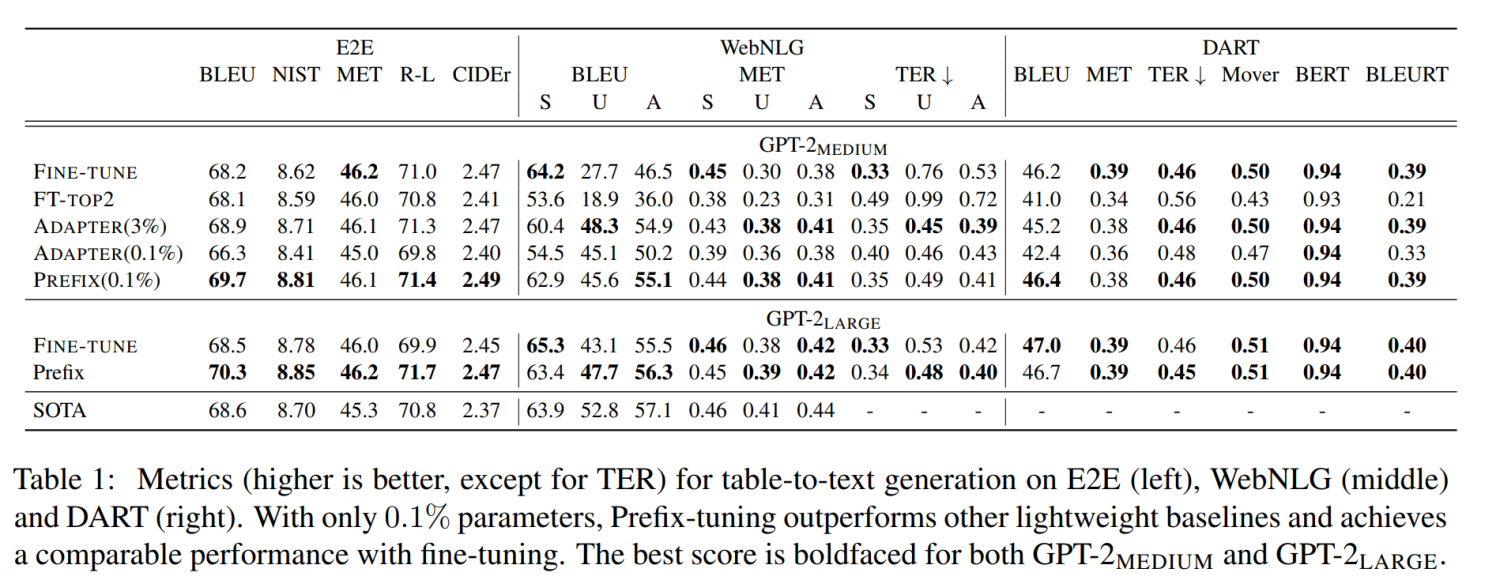
实验结果也说明了Prefix Tuning的方式可以取得不错的效果。
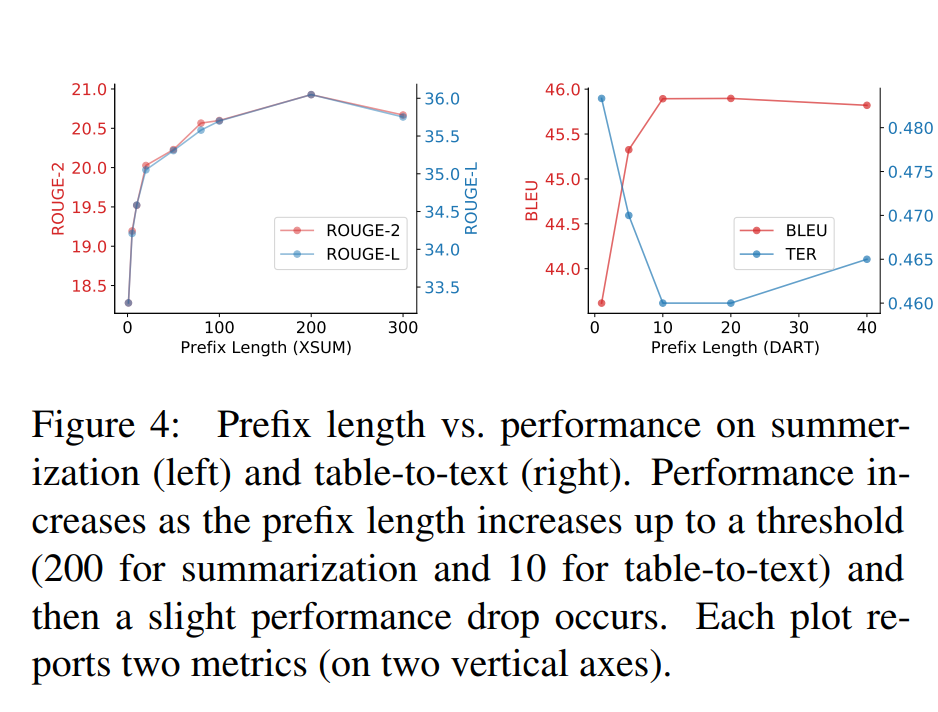
除此之外,作者还做了一系列的消融实验说明该方法的有效性:
- Prefix长度的影响 — 不同的任务所需要的Prefix的长度有差异;Figure4
- Full vs Embedding-only — 作者对比了Embedding-only(只有最上层输入处的Embedding作为参数更新,后续的参数固定)和Full(每一层的Prefix相关的参数都训练)的方式的效果;
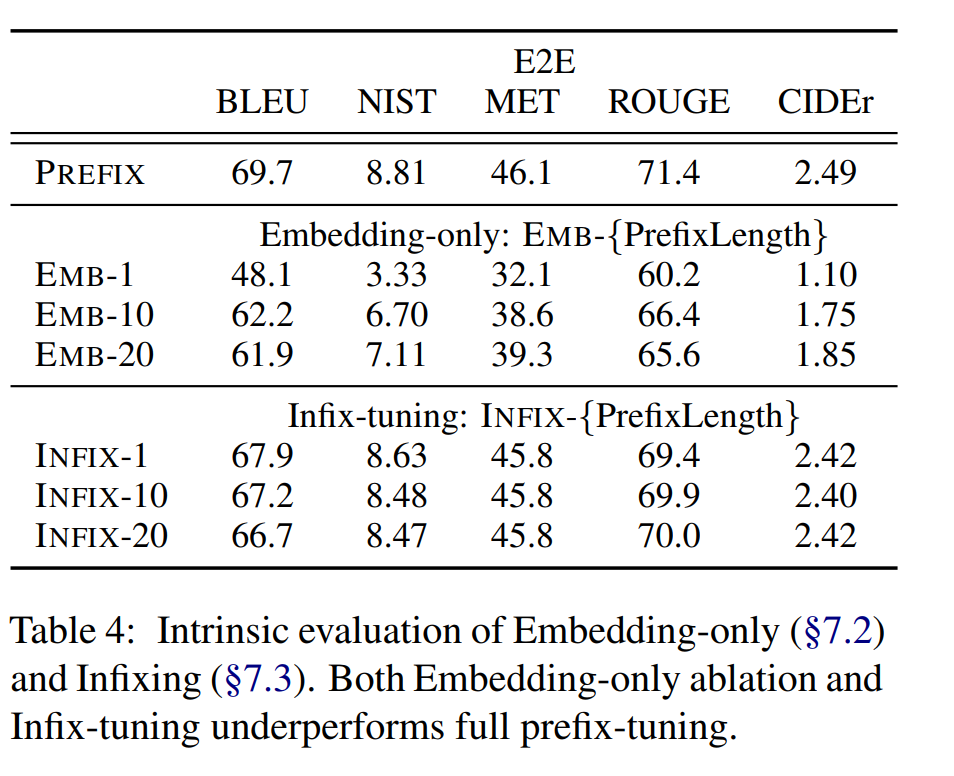
- Prefixing vs Infixing — 对比了[PREFIX; x; y] 方式与[x; INFIX; y] 方式的差异,还是Prefix方式最好;Table4
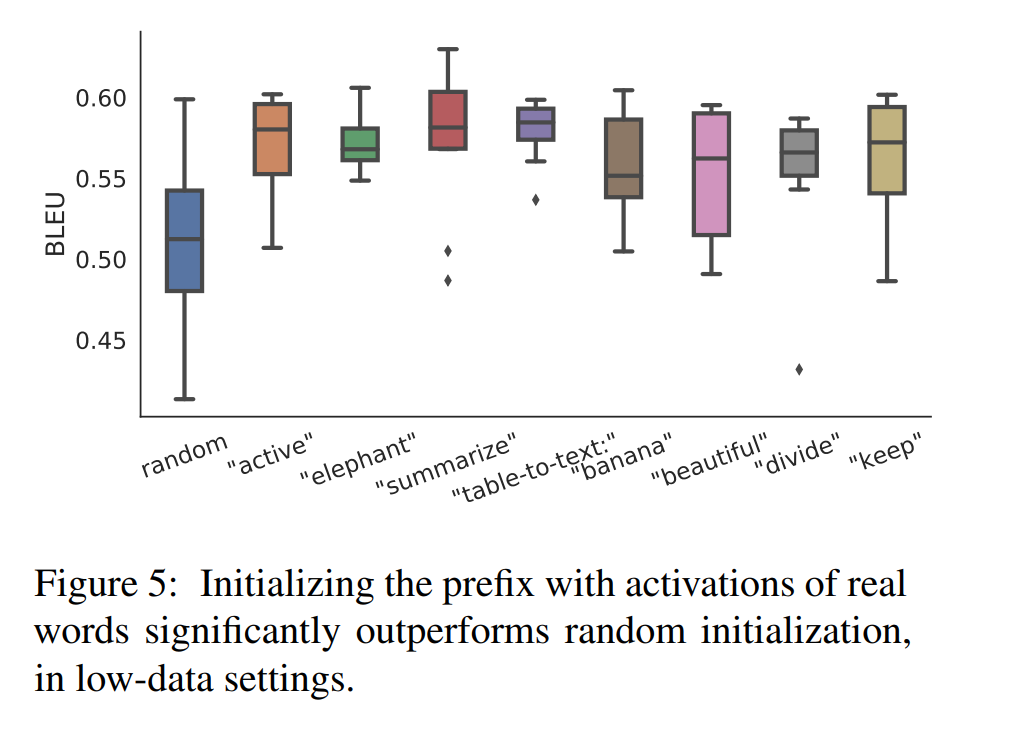
- Initialization — 用任务相关的Prompt去初始化Prefix能取得更好的效果;Figure5
 |
 |
 |
Prompt Tuning
论文&Code
- The Power of Scale for Parameter-Efficient Prompt Tuning
- https://github.com/google-research/prompt-tuning
1 | peft_config = PromptTuningConfig(task_type="SEQ_CLS", num_virtual_tokens=10) |
介绍
该方法可以看作是Prefix Tuning的简化版本,只在输入层加入Prompt tokens进行微调,并不需要加入MLP进行调整来解决难训练的问题,主要在T5预训练模型上做实验。似乎只要预训练模型足够强大,其他的一切都不是问题。
离散的Prompt Tuning(Prompt Design)基本不能达到fine-tuning的效果; Soft Prompt Tuning在模型增大时可以达到接近fine-tuning的效果, 并且有进一步超越fine-tuning的趋势。
另外, Prompt Tuning往往比模型调优提供更强的零样本性能, 尤其是在像 TextbookQA 这样具有大域变化的数据集上。主要在T5预训练模型上做实验。似乎只要预训练模型足够强大, 其他的一切都不是问题。
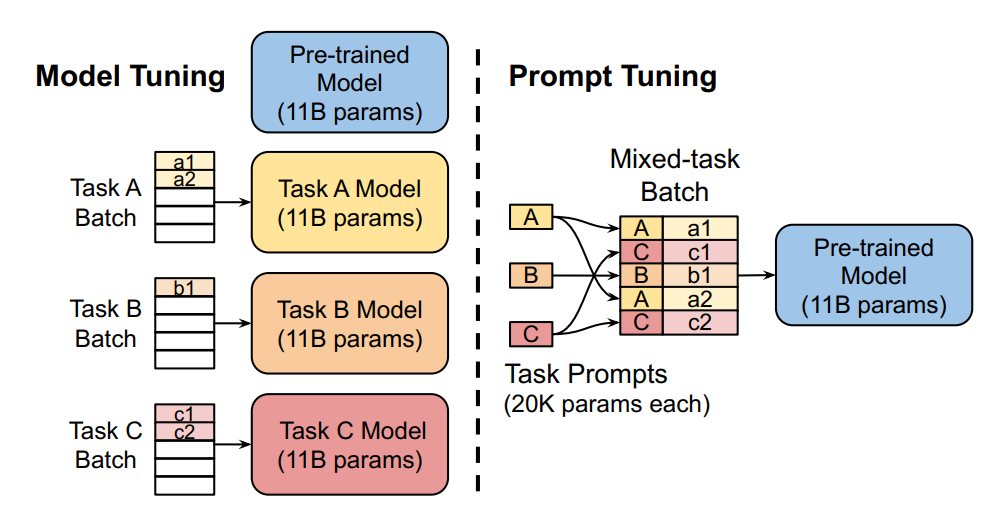
固定预训练参数, 为每一个任务额外添加一个或多个embedding, 之后拼接query正常输入LLM, 并只训练这些embedding。左图为单任务全参数微调, 右图为prompt tuning。
作者也做实验说明随着预训练模型参数量的增加,Prompt Tuning的方法会逼近Fine-tune的结果。
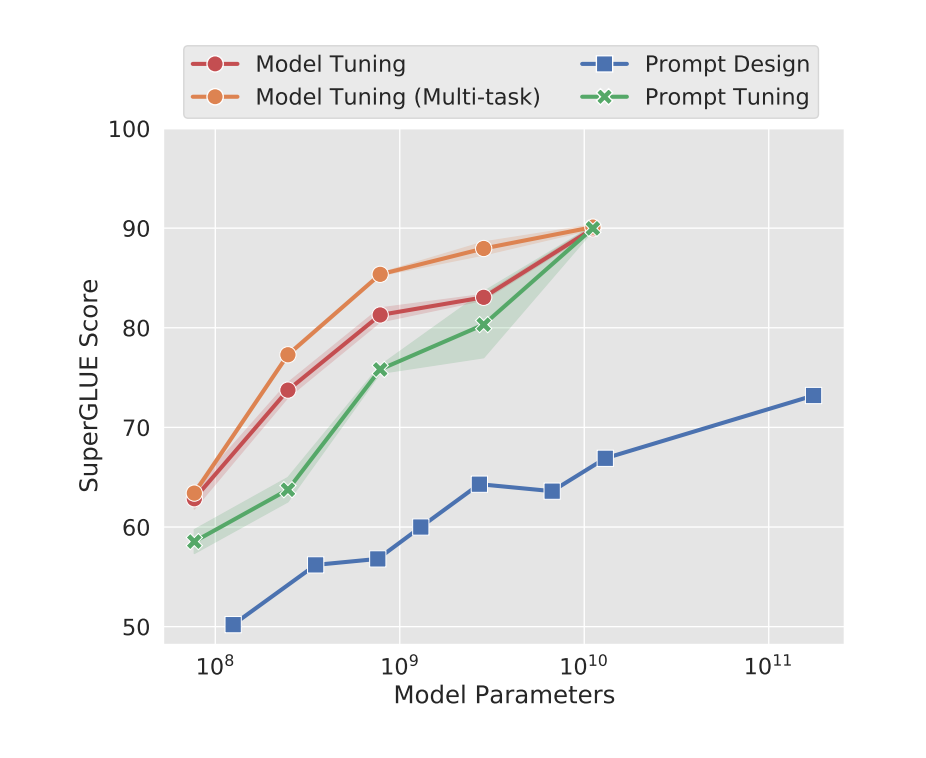
- 标准的T5模型(橙色线)多任务微调实现了强大的性能, 但需要为每个任务存储单独的模型副本。
- prompt tuning也会随着参数量增大而效果变好, 同时使得单个冻结模型可重复使用于所有任务。
- 显著优于使用GPT-3进行fewshot prompt设计。
- 当参数达到100亿规模与全参数微调方式效果无异。
Prompt length、Prompt initialization、Pre-training method、LM adaptation steps参数实验变化: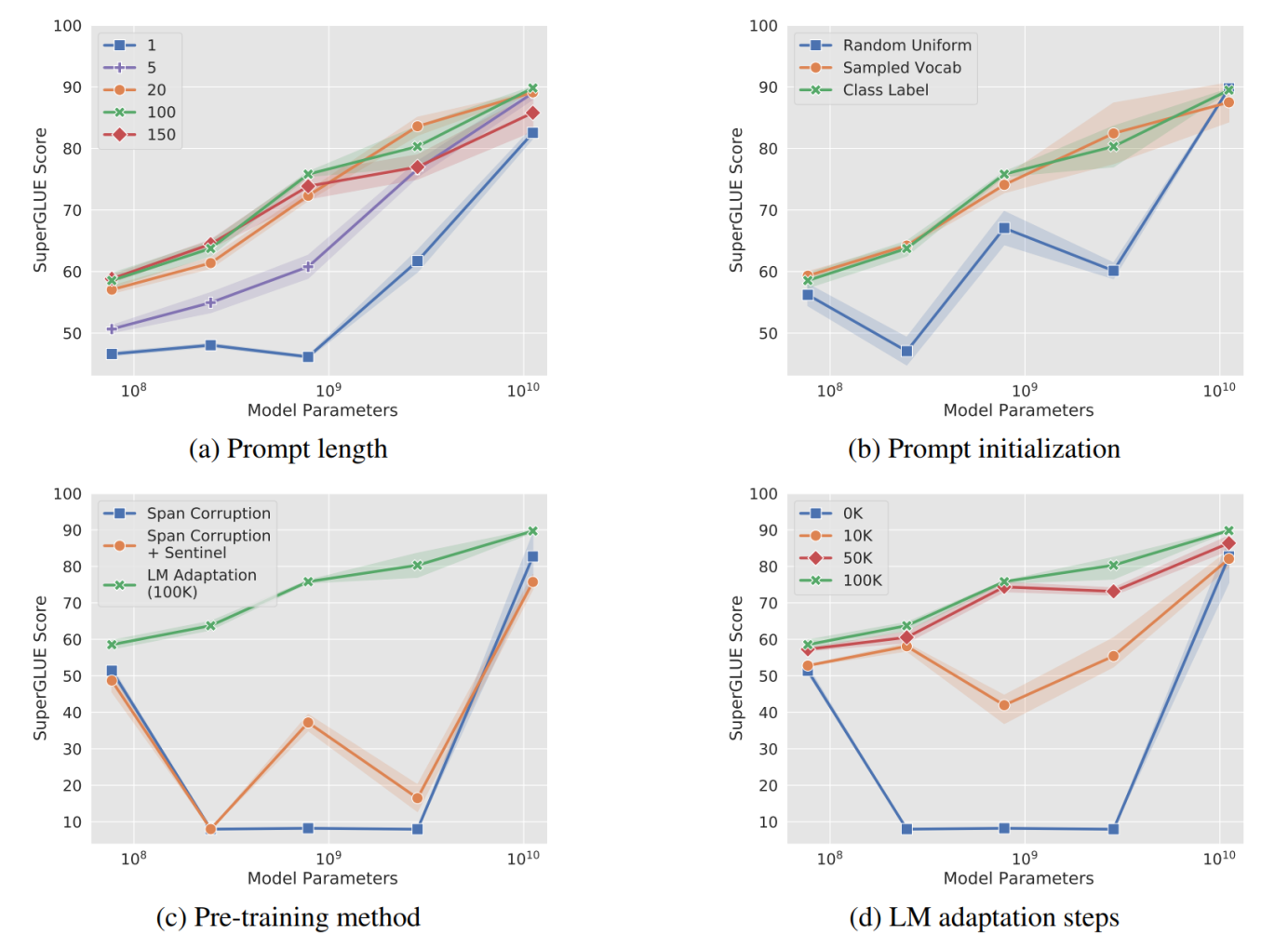
作者做了一系列对比实验,都在说明:随着预训练模型参数的增加,一切的问题都不是问题,最简单的设置也能达到极好的效果。
- Prompt长度影响:模型参数达到一定量级时,Prompt长度为1也能达到不错的效果,Prompt长度为20就能达到极好效果。
- Prompt初始化方式影响:Random Uniform方式明显弱于其他两种,但是当模型参数达到一定量级,这种差异也不复存在。
- 预训练的方式:LM Adaptation的方式效果好,但是当模型达到一定规模,差异又几乎没有了。
- 微调步数影响:模型参数较小时,步数越多,效果越好。同样随着模型参数达到一定规模,zero shot也能取得不错效果。
P-Tuning
V1
论文
介绍
P-Tuning方法的提出主要是为了解决这样一个问题:大模型的Prompt构造方式严重影响下游任务的效果。
P-Tuning提出将Prompt转换为可以学习的Embedding层,只是考虑到直接对Embedding参数进行优化会存在这样两个挑战:
- Discretenes:对输入正常语料的Embedding层已经经过预训练,而如果直接对输入的prompt embedding进行随机初始化训练,容易陷入局部最优。
- Association:没法捕捉到prompt embedding之间的相关关系。
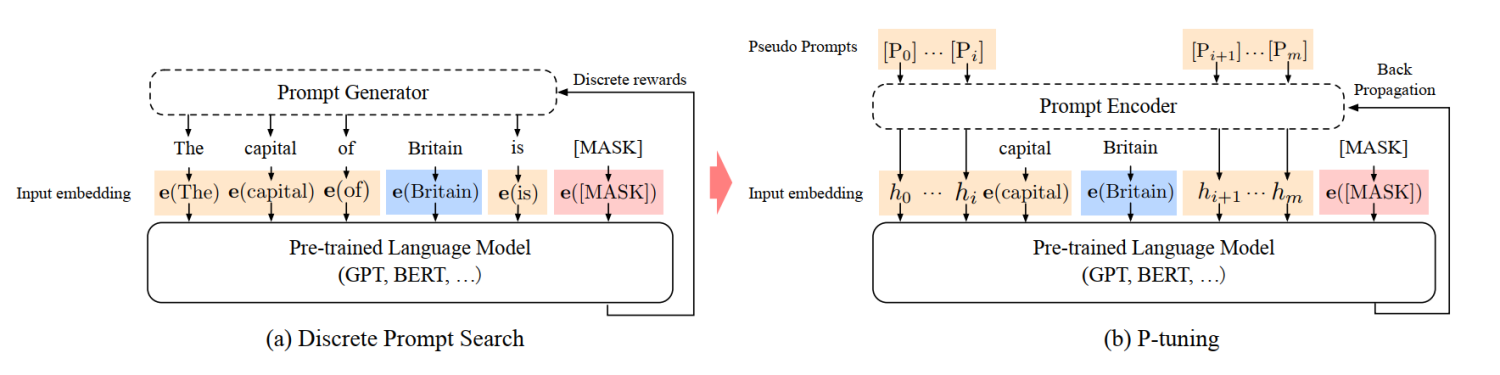
这篇文章(2021-03)和Prefix-Tuning(2021-01)差不多同时提出,做法其实也有一些相似之处,主要区别在于:
- Prefix Tuning是将额外的embedding加在开头,看起来更像是模仿Instruction指令;而P-Tuning的位置则不固定。
- Prefix Tuning通过在每个Attention层都加入Prefix Embedding来增加额外的参数,通过MLP来初始化;而P-Tuning只是在输入的时候加入Embedding,并通过LSTM+MLP来初始化。
V2
论文&Code
- P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks
- https://github.com/THUDM/P-tuning-v2
1 | peft_config = PromptEncoderConfig(task_type="SEQ_CLS", num_virtual_tokens=20, encoder_hidden_size=128) |
介绍
P-Tuning v2的目标就是要让Prompt Tuning能够在不同参数规模的预训练模型、针对不同下游任务的结果上都达到匹敌Fine-tuning的结果。
当前Prompt Tuning方法未能在这两个方面都存在局限性。
- 不同模型规模:Prompt Tuning和P-tuning这两种方法都是在预训练模型参数规模够足够大时,才能达到和Fine-tuning类似的效果,而参数规模较小时效果则很差。
- 不同任务类型:Prompt Tuning和P-tuning这两种方法在sequence tagging任务上表现都很差。
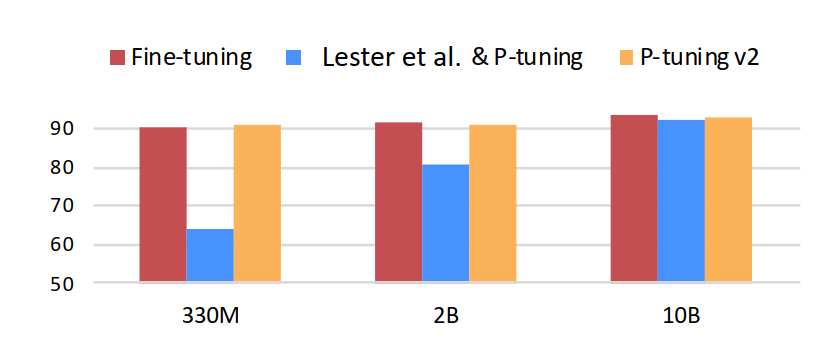
相比Prompt Tuning和P-tuning的方法, P-tuning v2方法在多层加入了Prompts tokens作为输入,带来两个方面的好处:
- 带来更多可学习的参数(从P-tuning和Prompt Tuning的0.1%增加到0.1%-3%),同时也足够parameter-efficient。
- 加入到更深层结构中的Prompt能给模型预测带来更直接的影响。
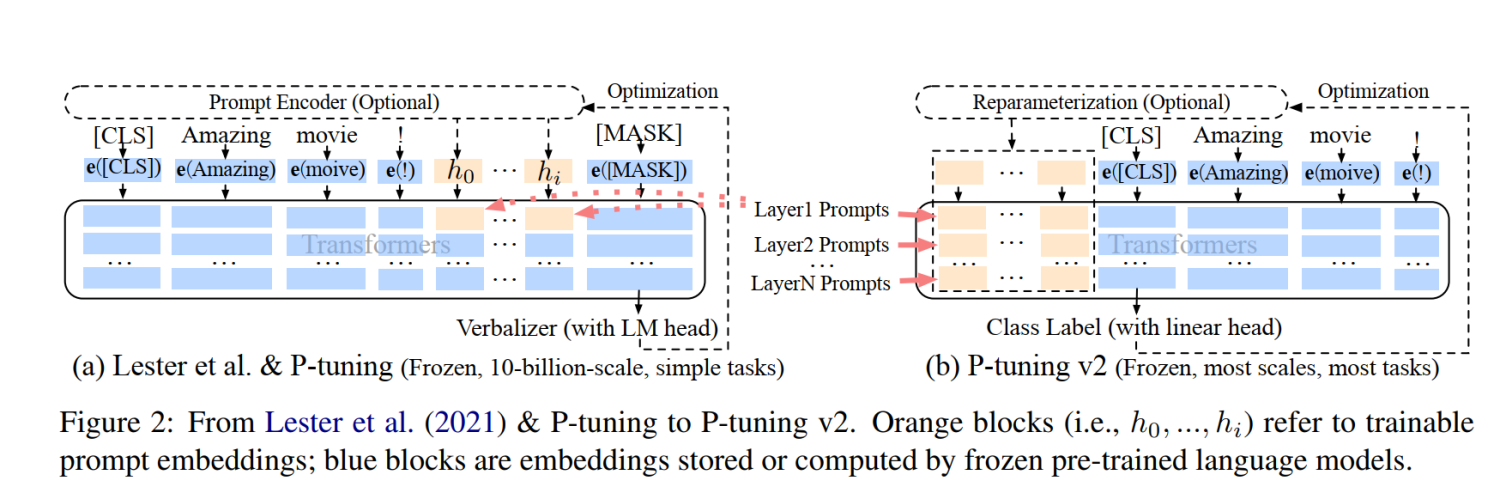
几个关键因素: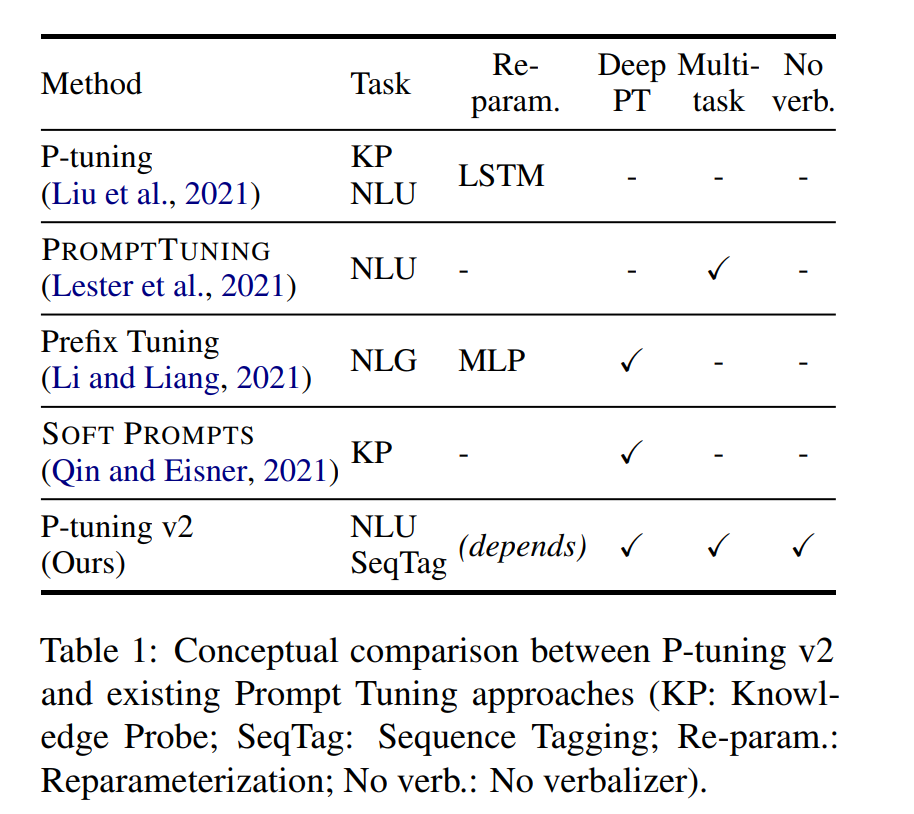
- Reparameterization:Prefix Tuning和P-tuning中都有MLP来构造可训练的embedding。本文发现在自然语言理解领域,面对不同的任务以及不同的数据集,这种方法可能带来完全相反的结论。
- Prompt Length: 不同的任务对应的最合适的Prompt Length不一样,比如简单分类任务下length=20最好,而复杂的任务需要更长的Prompt Length。
- Multi-task Learning 多任务对于P-Tuning v2是可选的,但可以利用它提供更好的初始化来进一步提高性能。
- Classification Head 使用LM head来预测动词是Prompt Tuning的核心,但我们发现在完整的数据设置中没有必要这样做,并且这样做与序列标记不兼容。P-tuning v2采用和BERT一样的方式,在第一个token处应用随机初始化的分类头。
实验结果:
不同预训练模型大小下的表现,在小模型下取得与Full-finetuning相近的结果,并远远优于P-Tuning。
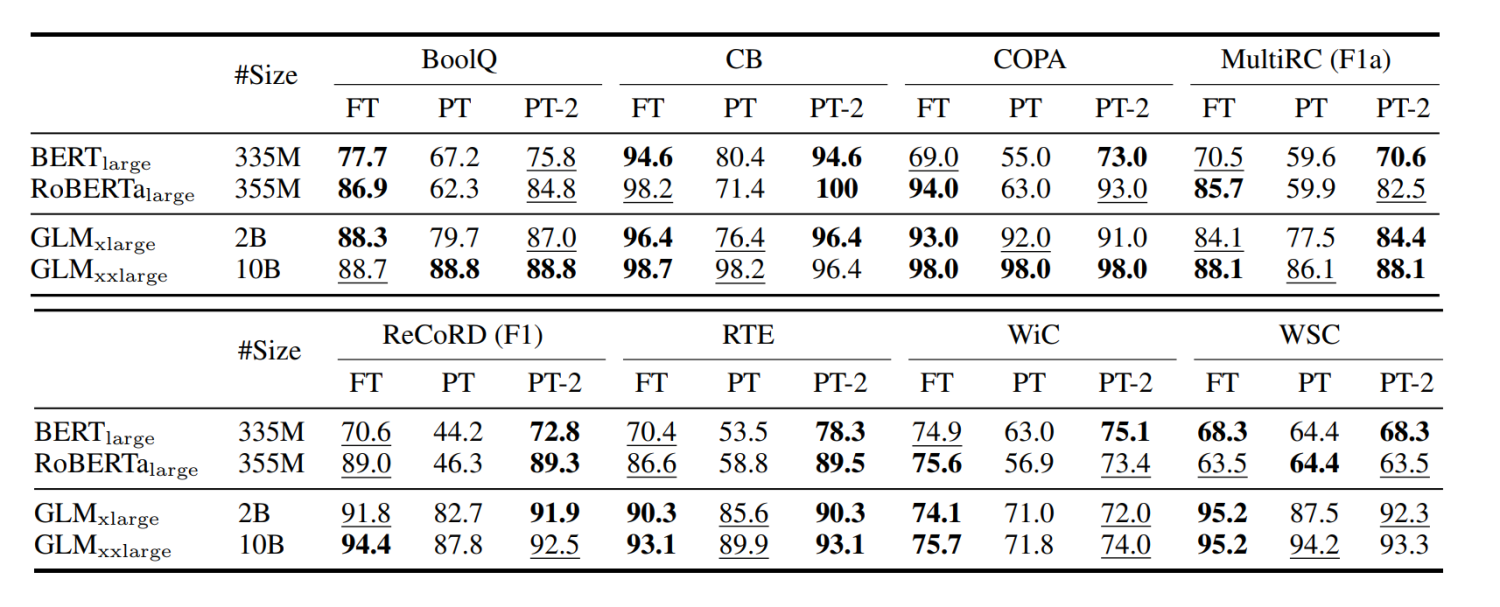
不同任务下的P-Tuning v2效果都很好,而P-Tuning和Prompt Learning效果不好;同时,采用多任务学习的方式能在多数任务上取得最好的结果。
LoRA
论文&Code
PEFT对LoRA的实现
1 | import torch |
介绍
微软和CMU的研究者指出,现有的一些PEFT的方法还存在这样一些问题:
- 由于增加了模型的深度从而额外增加了模型推理的延时,如Adapter方法
- Prompt较难训练,同时减少了模型的可用序列长度,如Prompt Tuning、Prefix Tuning、P-Tuning方法
- 往往效率和质量不可兼得,效果差于full-finetuning。
有研究者对语言模型的参数进行研究发现:语言模型虽然参数众多,但是起到关键作用的还是其中低秩的本质维度(low instrisic dimension)。本文受到该观点的启发,提出了Low-Rank Adaption(LoRA),设计了如下所示的结构,在涉及到矩阵相乘的模块,引入A、B这样两个低秩矩阵模块去模拟Full-finetune的过程,相当于只对语言模型中起关键作用的低秩本质维度进行更新。
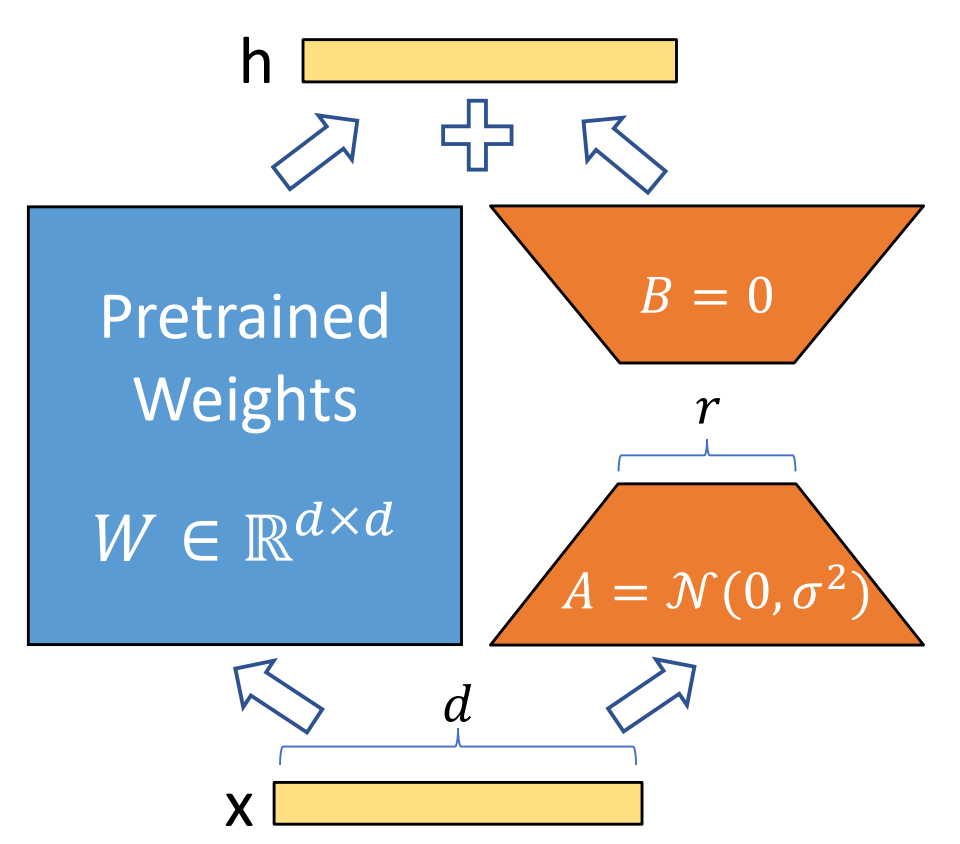
这么做就能完美解决以上存在的3个问题:
- 相比于原始的Adapter方法”额外”增加网络深度,必然会带来推理过程额外的延迟,该方法可以在推理阶段直接用训练好的A、B矩阵参数与原预训练模型的参数相加去替换原有预训练模型的参数,这样的话推理过程就相当于和Full-finetune一样,没有额外的计算量,从而不会带来性能的损失。
- 由于没有使用Prompt方式,自然不会存在Prompt方法带来的一系列问题。
- 该方法由于实际上相当于是用LoRA去模拟Full-finetune的过程,几乎不会带来任何训练效果的损失,后续的实验结果也证明了这一点。
在实验中,研究人员将这一LoRA模块与Transformer的attention模块相结合,在RoBERTa 、DeBERTa、GPT-2和GPT-3 175B这几个大模型上都做了实验,实验结果也充分证明了该方法的有效性。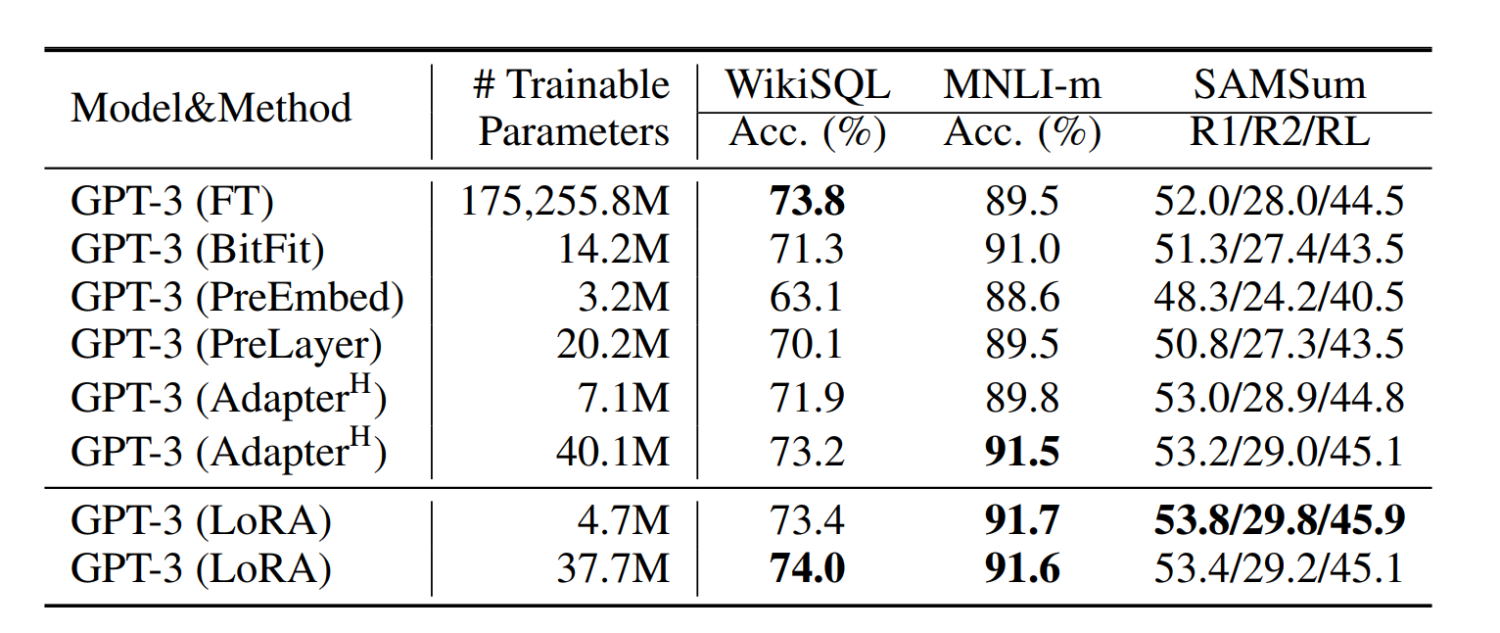
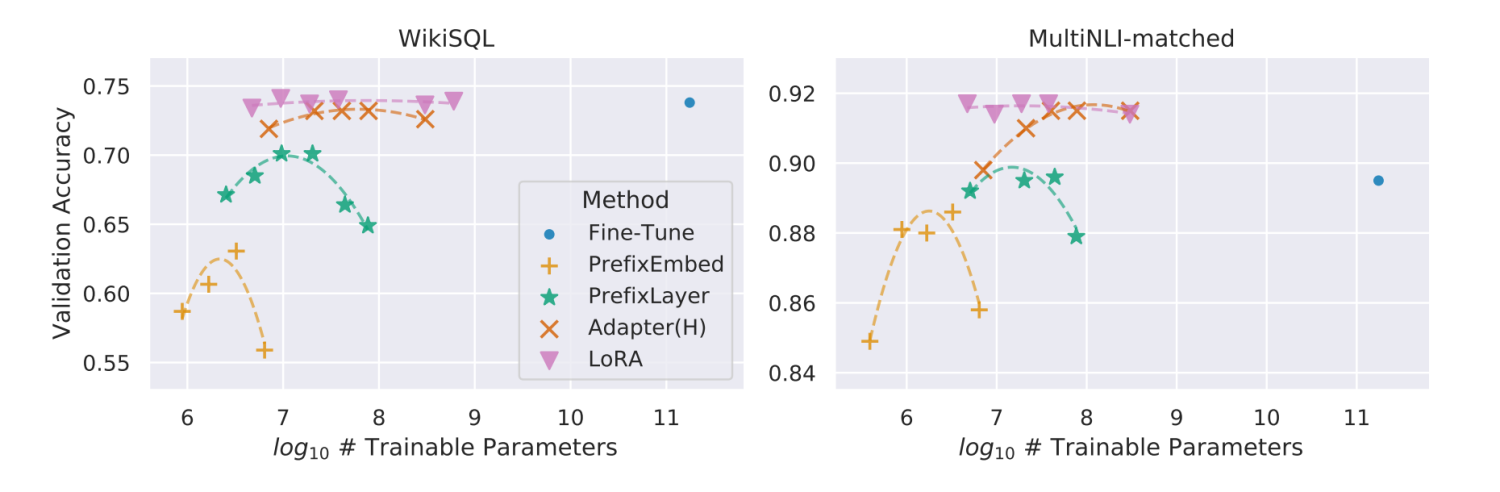
LoRA拥有几个关键优势:
- 一个预训练好的模型可以被共享, 用来为不同的任务建立许多小的LoRA模块。我们可以冻结共享模型, 并通过替换图1中的矩阵A和B来有效地切换任务, 从而大大减少存储需求和任务切换的开销。
- LoRA使训练更加有效, 在使用自适应优化器时, 硬件门槛降低了3倍, 因为我们不需要计算梯度或维护大多数参数的优化器状态。相反, 我们只优化注入的、小得多的低秩矩阵。
- 我们简单的线性设计允许我们在部署时将可训练矩阵与冻结权重合并, 与完全微调的模型相比, 在结构上没有引入推理延迟。
- LoRA与许多先前的方法是不相关的, 并且可以与许多方法相结合, 例如前缀微调。
AdaLoRA
论文&Code
- ADAPTIVE BUDGET ALLOCATION FOR PARAMETEREFFICIENT FINE-TUNING
- https://github.com/QingruZhang/AdaLoRA
1 | # AdaLoraConfig需要使用peft的main分支----v3版本 |
介绍
对LoRA的一种改进,它根据重要性评分动态分配参数预算给权重矩阵,将关键的增量矩阵分配高秩以捕捉更精细和任务特定的信息,而将较不重要的矩阵的秩降低,以防止过拟合并节省计算预算。具体做法如下:
- 调整增量矩分配。AdaLoRA将关键的增量矩阵分配高秩以捕捉更精细和任务特定的信息,而将较不重要的矩阵的秩降低,以防止过拟合并节省计算预算。
- 以奇异值分解的形式对增量更新进行参数化,并根据重要性指标裁剪掉不重要的奇异值,同时保留奇异向量。由于对一个大矩阵进行精确SVD分解的计算消耗非常大,这种方法通过减少它们的参数预算来加速计算,同时,保留未来恢复的可能性并稳定训练。
- 在训练损失中添加了额外的惩罚项,以规范奇异矩阵P和Q的正交性,从而避免SVD的大量计算并稳定训练。
通过实验证明,AdaLoRA 实现了在所有预算、所有数据集上与现有方法相比,性能更好或相当的水平。 例如,当参数预算为 0.3M 时,AdaLoRA 在RTE数据集上,比表现最佳的基线(Baseline)高 1.8%。
QLoRA
论文&Code
介绍
QLoRA, 它是一种”高效的微调方法”, 以LLama 65B参数模型为例,常规16 bit微调需要超过780GB的GPU内存,而QLoRA可以在保持完整的16 bit微调任务性能的情况下, 将内存使用降低到48GB,即可完成微调。
QLoRA使用一种新颖的高精度技术将预训练模型量化为4 bit,然后添加一小组可学习的低秩适配器权重,这些权重通过量化权重的反向传播梯度进行微调。QLoRA有一种低精度存储数据类型(4 bit),还有一种计算数据类型(BFloat16)。实际上,这意味着无论何时使用QLoRA权重张量,我们都会将张量反量化为BFloat16,然后执行16位矩阵乘法。QLoRA提出了两种技术实现高保真4 bit微调——4 bit NormalFloat(NF4)量化和双量化。此外,还引入了分页优化器,以防止梯度检查点期间的内存峰值,从而导致内存不足的错误,这些错误在过去使得大型模型难以在单台机器上进行微调。具体说明如下:
- 4bit NormalFloat(NF4):对于正态分布权重而言,一种信息理论上最优的新数据类型,该数据类型对正态分布数据产生比4 bit整数和4 bit浮点数更好的实证结果。
- 双量化:对第一次量化后的那些常量再进行一次量化,减少存储空间。
- 分页优化器:使用Nvidia统一内存特性,该特性可以在在GPU偶尔OOM的情况下,进行CPU和GPU之间自动分页到分页的传输,以实现无错误的GPU处理。该功能的工作方式类似于CPU内存和磁盘之间的常规内存分页。使用此功能为优化器状态(Optimizer)分配分页内存,然后在GPU内存不足时将其自动卸载到CPU内存,并在优化器更新步骤需要时将其加载回GPU内存。
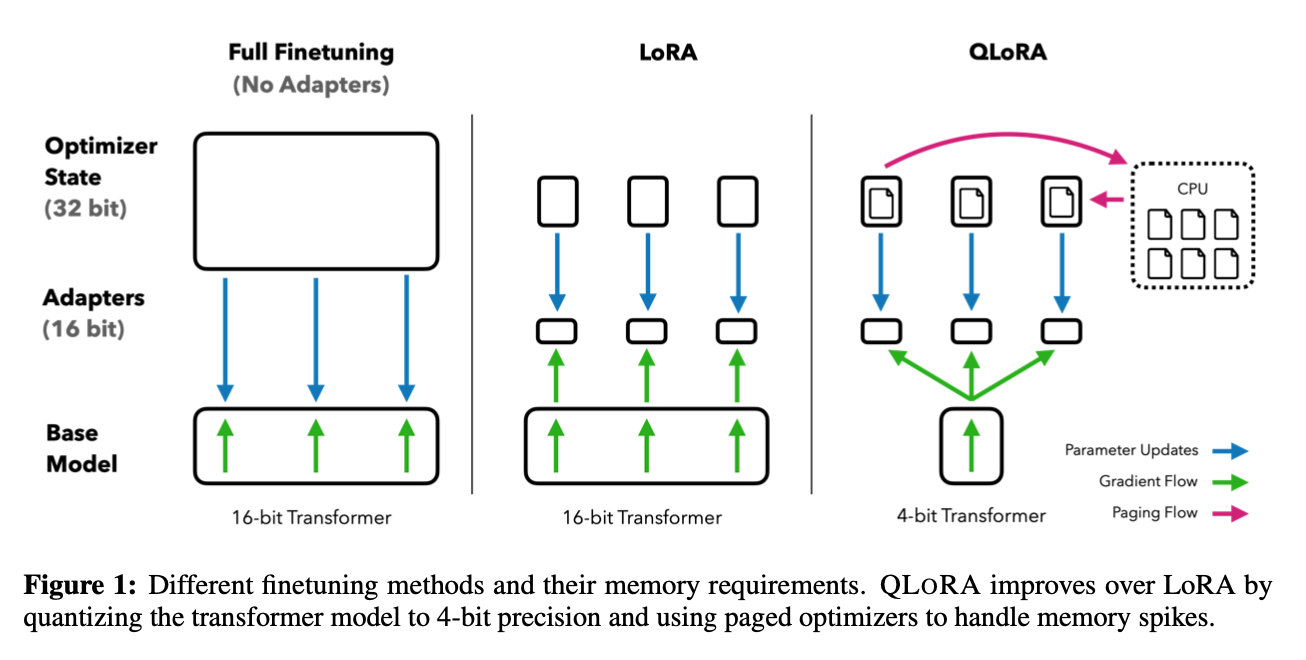
实验证明,无论是使用16bit、8bit还是4bit的适配器方法,都能够复制16bit全参数微调的基准性能。这说明,尽管量化过程中会存在性能损失,但通过适配器微调,完全可以恢复这些性能。
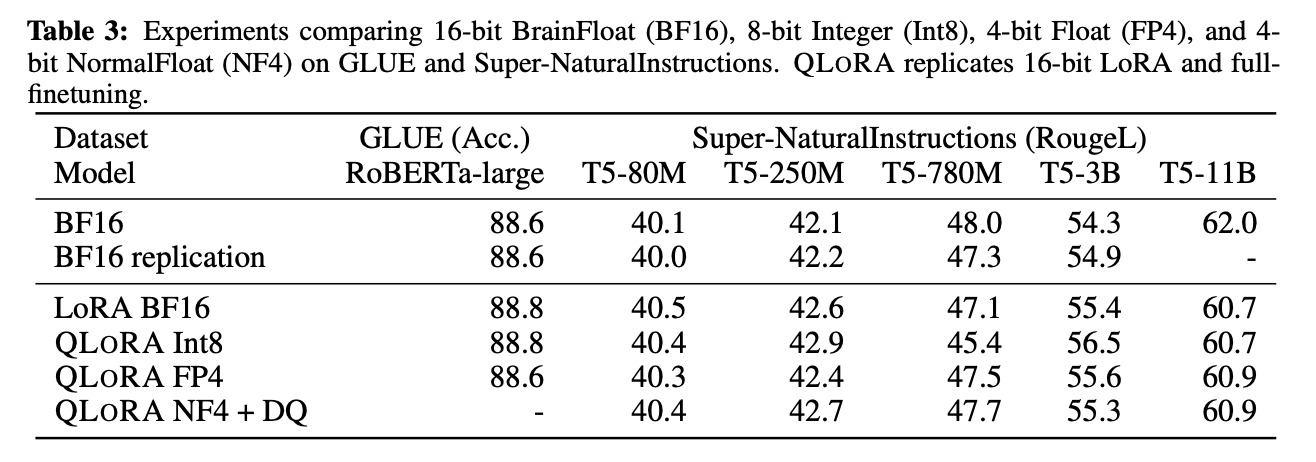
实验还比较了不同的4bit数据类型对效果(zero-shot均值)的影响,其中,NFloat 显著优于Float,而NFloat + DQ略微优于NFloat,虽然DQ对精度提升不大,但是对于内存控制效果更好。
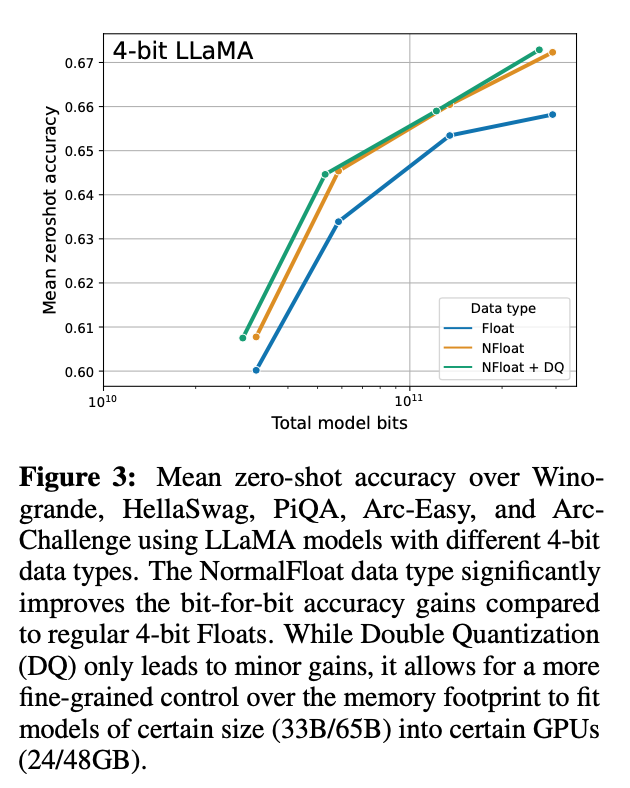
除此之外,论文中还对不同大小模型、不同数据类型、在 MMLU数据集上的微调效果进行了对比。使用QLoRA(NFloat4 + DQ)可以和Lora(BFloat16)持平,同时, 使用QLORA( FP4)的模型效果落后于前两者一个百分点。
作者在实验中也发现了一些有趣的点,比如:指令调优虽然效果比较好,但只适用于指令相关的任务,在聊天机器人上效果并不佳,而聊天机器人更适合用Open Assistant数据集去进行微调。通过指令类数据集的调优更像是提升大模型的推理能力,并不是为聊天而生的。
总之,QLoRA的出现给大家带来一些新的思考,不管是微调还是部署大模型,之后都会变得更加容易。每个人都可以快速利用自己的私有数据进行微调;同时,又能轻松的部署大模型进行推理。
相关数值理解
查看参数
1 | # 可训练 |
理解loss和val_loss
loss: 训练集的损失值; val_loss: 测试集的损失值。
一般训练规律:
- loss下降, val_loss下降: 训练网络正常, 最理想情况情况。
- loss下降, val_loss稳定: 网络过拟合。解决办法: ①数据集没问题: 可以向网络“中间深度”的位置添加Dropout层; 或者逐渐减少网络的深度(靠经验删除一部分模块)。②数据集有问题: 可将所有数据集混洗重新分配, 通常开源数据集不容易出现这种情况。
- loss稳定, val_loss下降: 数据集有严重问题, 建议重新选择。一般不会出现这种情况。
- loss稳定, val_loss稳定: 学习过程遇到瓶颈, 需要减小学习率(自适应动量优化器小范围修改的效果不明显)或batch数量。
- loss上升, val_loss上升: 可能是网络结构设计问题、训练超参数设置不当、数据集需要清洗等问题。属于训练过程中最差情况。
调大batch_size对网络训练的影响
- 优点:
- 内存的利用率提高了, 大矩阵乘法的并行化效率提高
- 跑完一次epoch(全数据集)所需迭代次数减少, 对于相同的数据量的处理速度进一步加快
- 一定范围内, batchsize越大, 其确定的下降方向就越准, 引起训练震荡越小
- batchsize增大, 处理相同的数据量的速度越快
- 缺点
- 内存消耗严重, 面临显卡内存不足问题
- 训练速度慢, loss不容易收敛
- batch_size过大导致网络收敛到局部最优点, loss下降不再明显
- batchsize增大, 达到相同精度所需要的epoch数量越来越多
loss不收敛
此处包含两种情况,一种是loss一直在震荡,一种是loss下降一点后不再下降到理想水平,而验证集上的表现保持不变.
- 保持需要的batchsize不变;
- 查看是否有梯度回传
- 查看数据是否有问题,如标签错乱等现象;
- 调节学习率,从大向小调,建议每次除以5;我的项目即是因为学习率过大过小都不收敛引起的;
- 如果学习率调好后,需要调节batchsize大小,如batchsize调大2倍,则将学习率对应调大(项目测试调大2~3倍OK),反之,学习率对应调小