MachineLearning-9.(分类)朴素贝叶斯分类
条评论朴素贝叶斯法是基于贝叶斯定理与特征条件独立假设的分类方法。“朴素”的含义为:假设问题的特征变量都是相互独立地作用于决策变量的,即问题的特征之间都是互不相关的。其为多用途分类器,广泛应用于垃圾邮件过滤、自然语言处理等.
朴素贝叶斯优点:逻辑性简单,易训练;算法较为稳定,当数据呈现不同特点时,其分类性能不会有太大差异;样本特征之间的关系相对比较独立时,朴素贝叶斯分类算法会有较好的效果。
朴素贝叶斯缺点:特征独立性很难满足,样本特征之间往往存在互相关联,会导致分类效果降低。
朴素贝叶斯使用场景:根据先验概率计算后验概率的情况,且样本特征之间独立性较强。
概率基础知识
概率定义
概率反映随机事件出现的可能性大小。随机事件是指在相同条件下,可能出现也可能不出现的事件。将随机事件记为A或B,P(A),P(B)表示事件A或B的概率。
联合概率与条件概率
联合概率
指包含多个条件且所有条件同时成立的概率,记作$P ( A , B )$ ,或$P(AB)$,或$P(A \bigcap B)$
条件概率
已知事件B发生的条件下,另一个事件A发生的概率称为条件概率,记为:$P(A|B)$
事件的独立性
事件A不影响事件B的发生,称这两个事件独立,记为:
$$
P(AB)=P(A)P(B)
$$
因为A和B不相互影响,则有:
$$
P(A|B) = P(A)
$$
可以理解为,给定或不给定B的条件下,A的概率都一样大。
先验概率与后验概率
先验概率
先验概率也是根据以往经验和分析得到的概率,例如:在没有任何信息前提的情况下,猜测对面来的陌生人姓氏,姓李的概率最大(因为全国李姓为占比最高的姓氏),这便是先验概率.
后验概率
后验概率是指在接收了一定条件或信息的情况下的修正概率,例如:在知道对面的人来自“牛家村”的情况下,猜测他姓牛的概率最大,但不排除姓杨、李等等,这便是后验概率.
两者的关系
事情还没有发生,求这件事情发生的可能性的大小,是先验概率(可以理解为由因求果). 事情已经发生,求这件事情发生的原因是由某个因素引起的可能性的大小,是后验概率(由果求因). 先验概率与后验概率有不可分割的联系,后验概率的计算要以先验概率为基础.
贝叶斯定理
贝叶斯定理定义
贝叶斯定理由英国数学家托马斯.贝叶斯 ( Thomas Bayes)提出,用来描述两个条件概率之间的关系,定理描述为:
$$
P(A|B) = \frac{P(A)P(B|A)}{P(B)}
$$
其中,$P(A)$和$P(B)$是A事件和B事件发生的概率. $P(A|B)$称为条件概率,表示B事件发生条件下,A事件发生的概率. 推导过程:
$$
P(A,B) =P(B)P(A|B)\
P(B,A) =P(A)P(B|A)
$$
其中$P(A,B)$称为联合概率,指事件B发生的概率,乘以事件A在事件B发生的条件下发生的概率. 因为$P(A,B)=P(B,A)$, 所以有:
$$
P(B)P(A|B)=P(A)P(B|A)
$$
两边同时除以P(B),则得到贝叶斯定理的表达式. 其中,$P(A)$是先验概率,$P(A|B)$是已知B发生后A的条件概率,也被称作后验概率.
朴素贝叶斯分类器
朴素贝叶斯分类器原理
朴素贝叶斯分类器就是根据贝叶斯公式计算结果进行分类的模型,“朴素”指事件之间相互独立无影响. 例如:有如下数据集:
| Text | Category |
|---|---|
| A great game(一个伟大的比赛) | Sports(体育运动) |
| The election was over(选举结束) | Not sports(不是体育运动) |
| Very clean match(没内幕的比赛) | Sports(体育运动) |
| A clean but forgettable game(一场难以忘记的比赛) | Sports(体育运动) |
| It was a close election(这是一场势均力敌的选举) | Not sports(不是体育运动) |
求:”A very close game“ 是体育运动的概率?数学上表示为 P(Sports | a very close game). 根据贝叶斯定理,是运动的概率可以表示为:
$$
P(Sports | a \ very \ close \ game) = \frac{P(a \ very \ close \ game | sports) * P(sports)}{P(a \ very \ close \ game)}
$$
不是运动概率可以表示为:
$$
P(Not \ Sports | a \ very \ close \ game) = \frac{P(a \ very \ close \ game | Not \ sports) * P(Not \ sports)}{P(a \ very \ close \ game)}
$$
概率更大者即为分类结果. 由于分母相同,即比较分子谁更大即可. 我们只需统计”A very close game“ 多少次出现在Sports类别中,就可以计算出上述两个概率. 但是”A very close game“ 并没有出现在数据集中,所以这个概率为0,要解决这个问题,就假设每个句子的单词出现都与其它单词无关(事件独立即朴素的含义),所以,P(a very close game)可以写成:
$$
P(a \ very \ close \ game) = P(a) * P(very) * P(close) * P(game)
$$
$$
P(a \ very \ close \ game|Sports)= \ P(a|Sports)*P(very|Sports)*P(close|Sports)*P(game|Sports)
$$
统计出“a”, “very”, “close”, “game”出现在”Sports”类别中的概率,就能算出其所属的类别. 具体计算过程如下:
第一步:计算总词频:Sports类别词语总数14,Not Sports类别词语总数9
第二步:计算每个类别的先验概率
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15# Sports和Not Sports概率
P(Sports) = 3 / 5 = 0.6
P(Not Sports) = 2 / 5 = 0.4
# Sports条件下各个词语概率
P(a | Sports) = (2 + 1) / (11 + 14) = 0.12
P(very | Sports) = (1 + 1) / (11 + 14) = 0.08
P(close | Sports) = (0 + 1) / (11 + 14) = 0.04
P(game | Sports) = (2 + 1) / (11 + 14) = 0.12
# Not Sports条件下各个词语概率
P(a | Not Sports) = (1 + 1) / (9 + 14) = 0.087
P(very | Not Sports) = (0 + 1) / (9 + 14) = 0.043
P(close | Not Sports) = (1 + 1) / (9 + 14) = = 0.087
P(game | Not Sports) = (0 + 1) / (9 + 14) = 0.043其中,分子部分加1,是为了避免分子为0的情况;分母部分都加了词语总数14,是为了避免分子增大的情况下计算结果超过1的可能.
第三步:将先验概率带入贝叶斯定理,计算概率:
是体育运动的概率:
$$
P(a \ very \ close \ game|Sports)= \ P(a|Sports)*P(very|Sports)*P(close|Sports)*P(game|Sports)= \
0.12 * 0.08 * 0.04 * 0.12 = 0.00004608
$$
不是体育运动的概率:
$$
P(a \ very \ close \ game|Not \ Sports)= \
P(a|Not \ Sports)*P(very|Not \ Sports)*P(close|Not \ Sports)*P(game|Not \ Sports)= \
0.087 * 0.043 * 0.087 * 0.043 = 0.000013996
$$
分类结果:P(Sports) = 0.00004608 , P(Not Sports) = 0.000013996, 是体育运动.
朴素贝叶斯分类器实现
在sklearn中,提供了三个朴素贝叶斯分类器,分别是:
- GaussianNB(高斯朴素贝叶斯分类器):适合用于样本的值是连续的,数据呈正态分布的情况(比如人的身高、城市家庭收入、一次考试的成绩等等)
- MultinominalNB(多项式朴素贝叶斯分类器):适合用于大部分属性为离散值的数据集
- BernoulliNB(伯努利朴素贝叶斯分类器):适合用于特征值为二元离散值或是稀疏的多元离散值的数据集
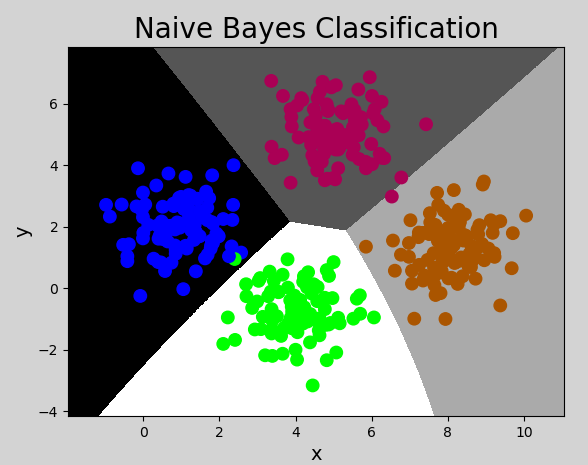
该示例中,样本的值为连续值,且呈正态分布,所以采用GaussianNB模型. 代码如下:
1 | # 朴素贝叶斯分类示例 |
执行结果: