DeepLearning-4.数值计算
条评论机器学习算法需要大量数值计算,通常是指通过迭代过程更新解得估计值来解决数学问题的算法,而不是通过解析过程推导出公式来提供正确解的方法。常见的操作包括优化和线性方程组的求解。
上溢和下溢
无限多的实数无法在计算机内精确保存,因此计算机保存实数时,几乎总会引入一些近似误差,单纯的舍入误差会导致一些问题,特别是当操作复合时,即使是理论上可行的算法,如果没有考虑最小化舍入误差的累积,在实践时也会导致算法失效。
下溢(Underflow) : 当接近零的数被四舍五入为零时发生下溢。
上溢(Overflow) : 当大量级的数被近似为$\propto $或$-\propto $时发生上溢。
必须对上溢和下溢进行数值稳定的一个例子是softmax函数(解决上溢和下溢)。softmax函数经常用于预测和范畴分布相关联的概率,定义为:
当所有$x_{i}$都等于某个常数$c$时,所有的输出都应该为$\frac{1}{n}$,当$$是很小的负数,$exp(c)$就会下溢,函数分母会变为0,所以结果是未定义的。当$c$是非常大的正数时,$exp(c)$的上溢再次导致整个表达式未定义。
两个困难都通过计算$softmax(z)$同时解决,其中$z=x-max_{i}x_{i}$ 。
代码实现
1 | import numpy as np |
1 | x = np.array([1e7, 1e8, 2e5, 2e7]) |
1 | x = np.array([-1e10, -1e9, -2e10, -1e10]) |
手动推算
病态矩阵与条件数
在求解方程组时,如果对数据进行较小的扰动,则结果有很大的波动,这样的矩阵称为病态矩阵 。病态矩阵是一种特殊矩阵。指条件数很大的非奇异矩阵。病态矩阵的逆和以其为系数矩阵的方程组的界对微小扰动十分敏感,对数值求解会带来很大困难。[1]
例如:现在有线性方程组,$Ax = b$, 解方程:
很容易得到解为:$x1 = -100, x2 = -200$。如果在样本采集时存在一个微小的误差,比如,将$A$矩阵的系数400改变成401:则得到一个截然不同的解: $x1 = 40000, x2 = 79800$.
当解集 $x$ 对 $A$ 和 $b$ 的系数高度敏感,那么这样的方程组就是病态的 (ill-conditioned)。
条件数 :判断矩阵是否病态以及衡量矩阵的病态程度通常看矩阵$A$的条件数$K(A)$的大小:
$K(A)$称为$A$的条件数,很大时,称$A$为病态,否则称良态;$K(A)$俞大,$A$的病态程度俞严重。
基于梯度的优化方法
深度学习算法都涉及到某种形式的优化,优化指改变$x$以最小化或最大化某个函数$f(x)$的任务。目标函数(Objective Function) :把要最小化或最大化的函数称为目标函数。对其进行最小化时,称为损失函数(Loss Function) 或 误差函数(Error Function)。梯度下降时无约束优化最常用的方法之一,另一种为最小二乘法。
梯度下降(Gradient Descent) [2][3]: 梯度下降简单来说就是一种寻找目标函数最小化的方法,导数对于最小化一个函数很有用,代表更改$x$来略微改善$y$,因此可以将$x$往导数的反方向移动一小步来减小$f(x)$,这种技术称为梯度下降。如图所示,梯度下降算法,沿着函数的下坡方向(导数反方向)直到最小。
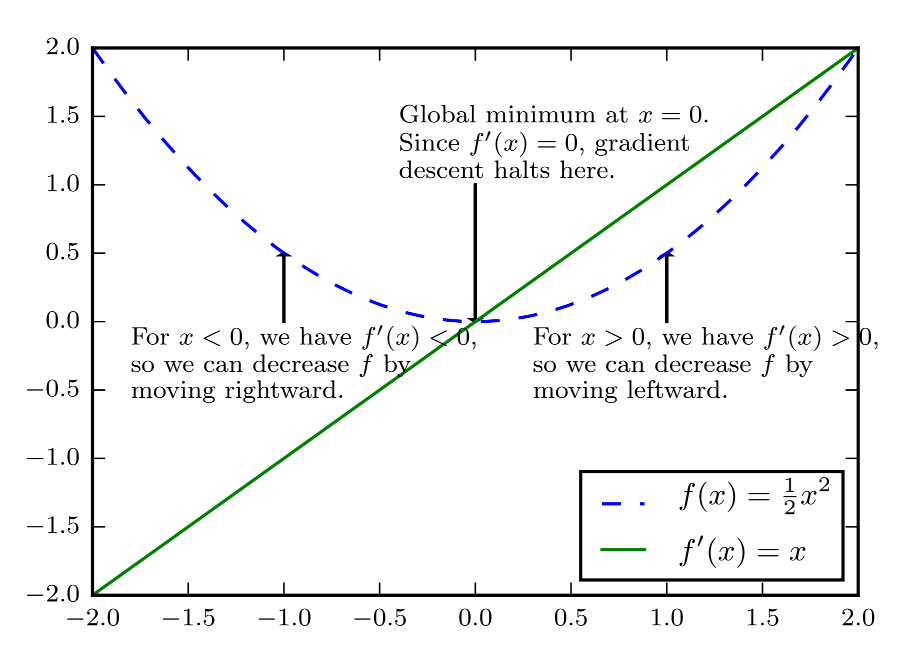
- 对于$x>0$,有$f’(x)>0$,左移来减小$f$。
- 对于$x<0$,有$f’(x)<0$,右移来减小$f$。
- 当$f’(x)=0$时,导数无法提供往哪个方向移动,$f’(x)=0$的点称为临界点(Critical Point) 。
临界点分局部极小点、局部极大点、鞍点。当存在多个局部极小点或平坦区域时,优化算法可能无法找到全局最小点,在深度学习背景下,即使找到的解不是真正最小的,但只要对应于代价函数显著低的值,通常可以接受这样的解。
针对多维输入的函数,需要用到偏导数(Partial Detrivatice),梯度(Gradient)是相对于一个向量求导的导数:$f$的梯度是包含所有偏导数的向量,记为$\bigtriangledown_{x}f(x)$。在多维情况下,临界点是梯度中所有元素都为零点。
梯度下降建议新的点为:
其中$\epsilon$为学习率(Learning Rate),是一个确定步长大小的正标量。$\epsilon$的选择方法:选择一个小常数;根据几个$\epsilon$计算$x’$,选择能产生最小目标函数值的$\epsilon$,称为在线搜索。
代码实现
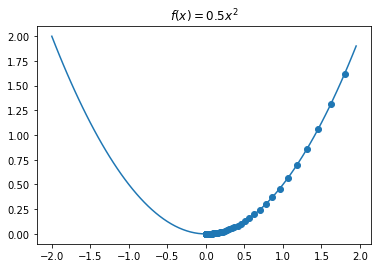
1 | # 上图中函数公式 f(x)=0.5x^2 梯度下降算法演示 |
1 | # 可视化梯度下降过程 |
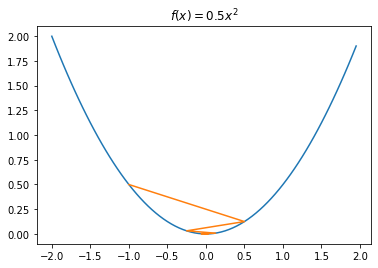
1 | # 调整学习率为1.5 |
手动推算
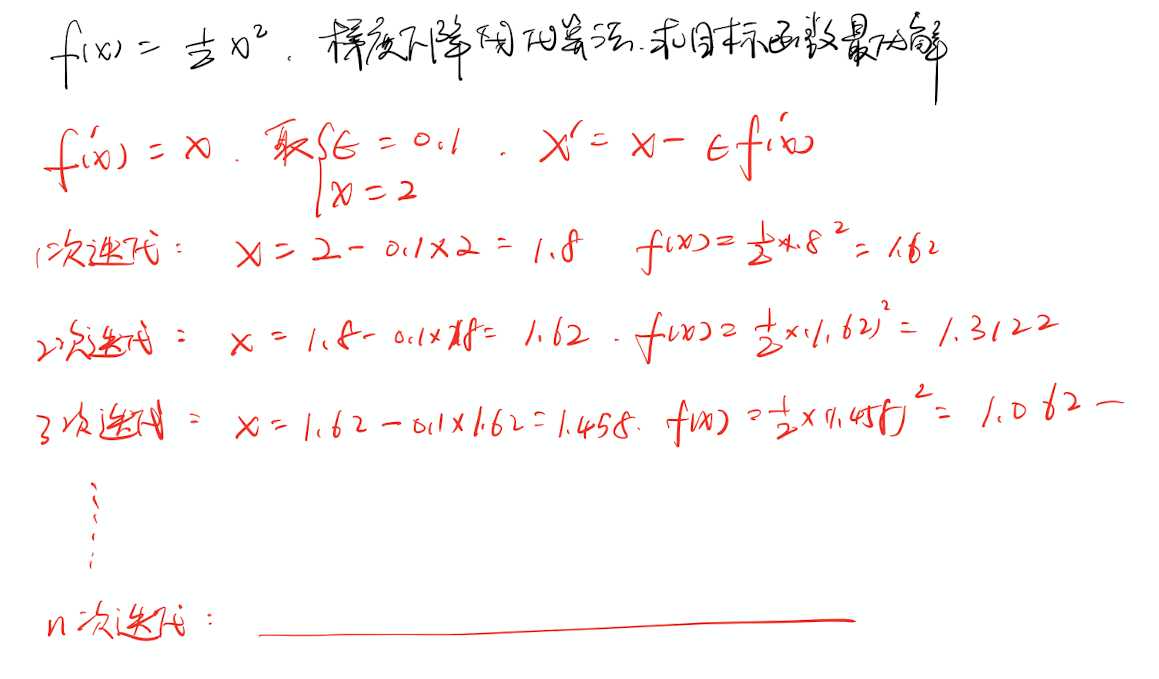
Jacobian矩阵和Hessian矩阵
Jacobian矩阵 :有时我们需要计算输入和输出都为向量的函数的所有偏导数,包含所有这样的偏导数的矩阵称为Jacobian矩阵。定义:有一个函数$f:\mathbb{R}^{m}\rightarrow \mathbb{R}^{n}$,$f$的Jacobian矩阵$J\in \mathbb{R}^{n\times m}$,定义为$J_{i,j}=\frac{\partial }{\partial x_{j}}f(x)_{i}$。
Hessian矩阵:当函数具有多维输入时,二阶导数有很多。将这些导数合并为一个矩阵,称为Hessian矩阵,定义为:
Hessian矩阵等价于梯度的Jacobian矩阵。
牛顿法
牛顿法(Newton’s Method):基于宇哥二阶泰勒展开来近似$x^{(0)}$附近的$f(x)$:
接着通过计算,可以得到这个函数的临界点:
牛顿法迭代更新近似函数和跳到近似函数的最小点可以比梯度下降法更快地到达临界点。这在接近全局极小时是一个特别有用的性质,但在鞍点附近是有害的。
针对上述实例,计算得到:$H=A^{\top}A$,进一步计算得到最优解:
手动推算
约束优化
约束优化(Constrained Optimization) : $x$在某些集合$S$中找$f(x)$的最大值和最小值,而非在所有值下的最大和最小值,这称为约束优化。
通过$m$个函数$g^{(i)}$和$n$个函数$h^{(j)}$描述$S$,那么$S$可以表示为$S=\left\{x\mid \forall i,g^{(i)}(x)=0 and \forall j,h^{(j)}(x)\leqslant 0 \right\}$。其中涉及$g^{(i)}$的等式称为等式约束,涉及$h^{(j)}$的不等式称为不等式约束。
为每个约束引入新的变量$\lambda _{i}$和$\alpha _{j}$,这些新变量被称为KKT乘子。广义拉格朗日式定义:
可以通过优化无约束的广义拉格朗日式解决约束最小化问题:
优化该式与下式等价:
针对上述实例,约束优化:$x^{\top}x\leqslant 1$
引入广义拉格朗日式:
解决以下问题:
关于$x$对于Lagrangian微分,我们得到方程:
得到解的形式:
$\lambda$的选择必须使结果服从约束,可以对$\lambda$梯度上升找到这个值:
手动推算
线性最小二乘
最小二乘法:[4][5][6]用来做函数拟合或者求函数极值的方法,在机器学习中,在回归模型中较为常见。
例如:引入实例:
假设我们希望找到最⼩化该式的$x$值,计算梯度得到:
手动推算
代码实现
1 | import numpy as np |