40
随笔文章
记录问题、方法和阶段性思考
40
随笔文章
记录问题、方法和阶段性思考
34
课程专题
把知识点整理成结构化学习入口
24
研究专题
面向具体研究问题的持续沉淀
198
主题标签
内容覆盖自 2020 年以来的多条学习线
Core Entry Points
首页最重要的任务不是“展示所有内容”,而是帮助访客快速判断该从哪里开始。
Current Highlights
让新访客先看到每个栏目当前最有代表性的入口,而不是被最新文章列表直接淹没。
持续记录
从零开始在 Mac 上安装 Claude Code,在 VSCode 中配置 Claude Code 插件,并绑定 DeepSeek 等第三方 API 做模型驱动的完整教程。
继续阅读结构化学习

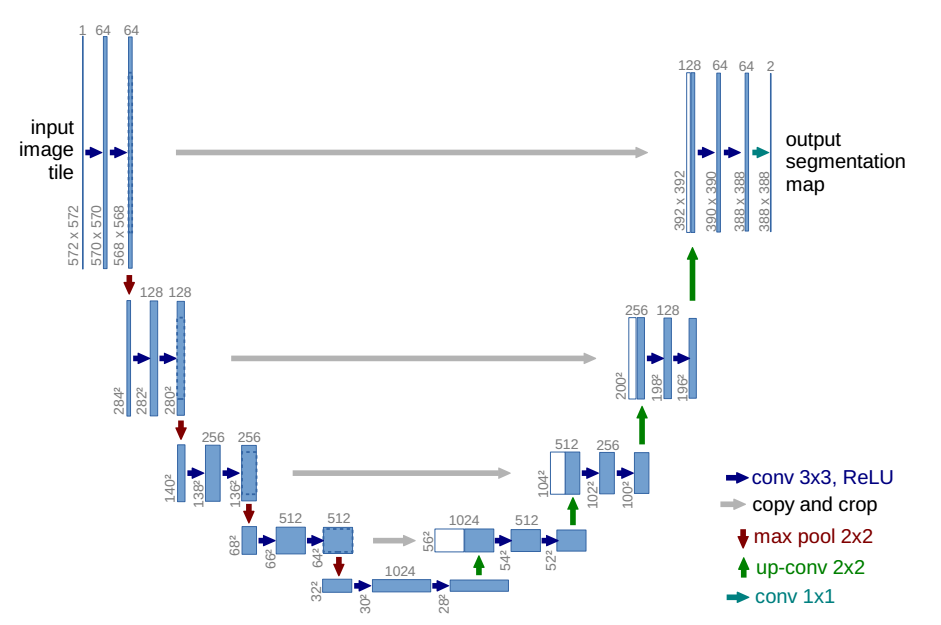
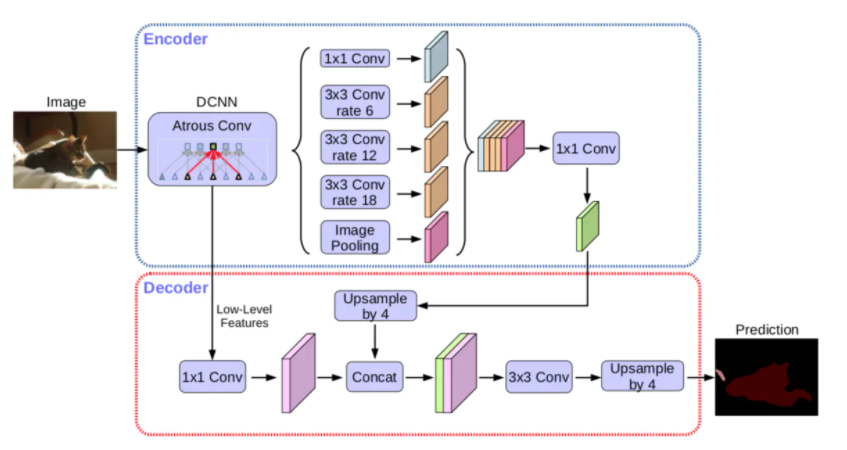
语义分割(Semantic Segmentation)是图像处理和机器视觉一个重要分支,其目标是精确理解图像场景与内容。语义分割是在像素级别上的分类,属于同一类的像素都要被归为一类,因此语义分割...
继续阅读问题驱动
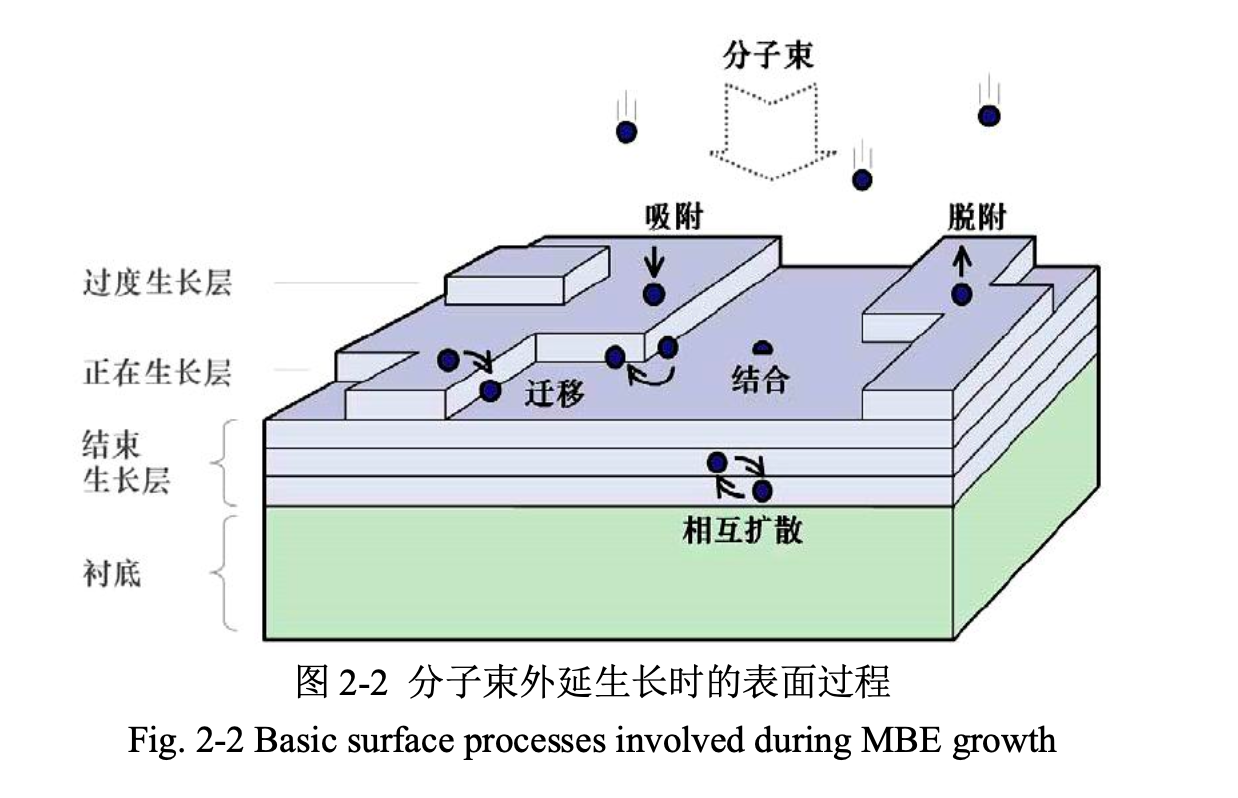
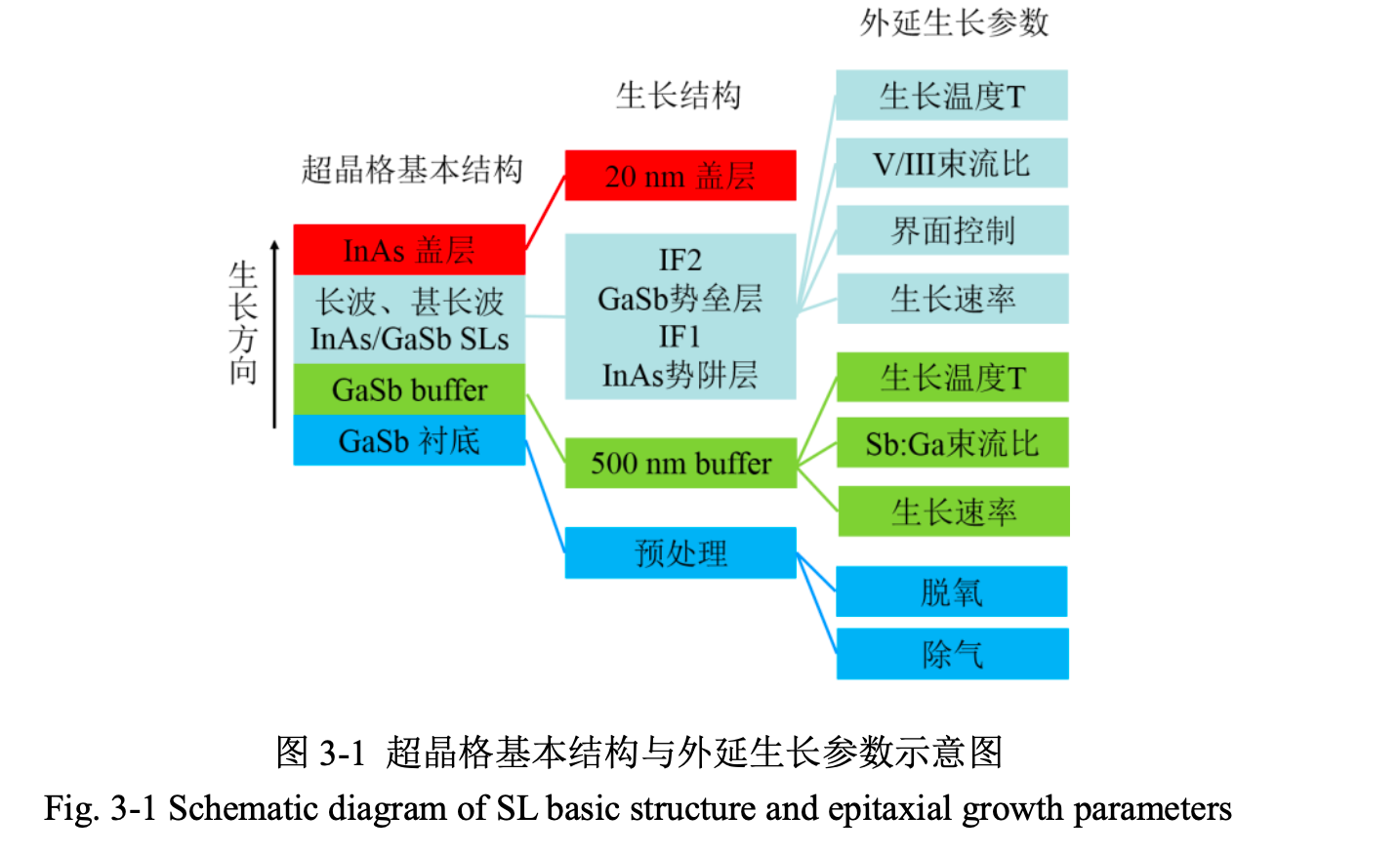
合并长波红外探测器工作原理与 InAs/GaSb 二类超晶格 MBE 生长学习笔记,从热辐射、制冷/非制冷路线、微测辐射热计、HgCdTe、QWIP、T2SL、器件工艺、表征方法一直串到 AI 辅助材料生长和红外图像理解。
继续阅读Recent Updates
首页保留最近动态,但它现在只承担“更新提醒”的职责,而不是整站的唯一入口。
Design Rationale
一个内容平台的首页,职责应该是定位、分发、引导与信任建立,而不仅仅是时间流列表。
首页先给出清晰入口,让新访客知道内容边界、适合人群和最佳起点,降低第一次进入平台的认知成本。
无论用户是想查一篇文章、学一个专题,还是看研究方向,首页都应该在第一屏附近提供直接路径。
当内容越来越多,首页的职责不再是简单展示最新文章,而是承担定位、分发、引导与品牌表达。
Platform Context
这里汇集了个人在 AI、深度学习、计算机视觉、自然语言处理以及研究实践中的学习记录与问题沉淀。它既服务于未来的自己,也服务于希望快速理解主题、建立知识路径的读者。