LLama3.2调研报告
条评论1B和3B,小模型用于边缘计算的,可以用移动设备推理了。HER时代真要到来了。
一、介绍
本次LLama3.2发布两款模型:
- 小参数量文本生成模型(可在移动设备/CPU设备上推理):
- 1B
- 3B
- 多模态(Text/Image-To-Text)模型:
- 11B
- 90B

二、收益
- LLama3.2的发布,丰富了LLama全家桶,参数量上,从小模型到405B的Dense模型,全部覆盖,并且扩充了多模态的Vision模型:
- 2023年,LLama2 7B/70B
- 2024年,LLama3 8B/70B
- 2024年,LLama3.1 8B/70B/405B
- 2024年,LLama3.2 1B/3B,Vision 11B/90B
- 1B和3B模型,支持128K的Tokens,使得在设备上,进行summarization, instruction following, and rewriting 等任务,变得可能。
- LLama3.2 11B和90B多模态模型,可以平替文本生成模型,并且在图片理解任务上,优于闭源模型Claude 3 ,并且可以使用torchtune等进行自定义微调,可以进行本地torchchat部署。
- 发布第一个LLama Stack,简化了开发人员针对LLama系列在不同环境下的部署、使用等操作。
三、能干什么
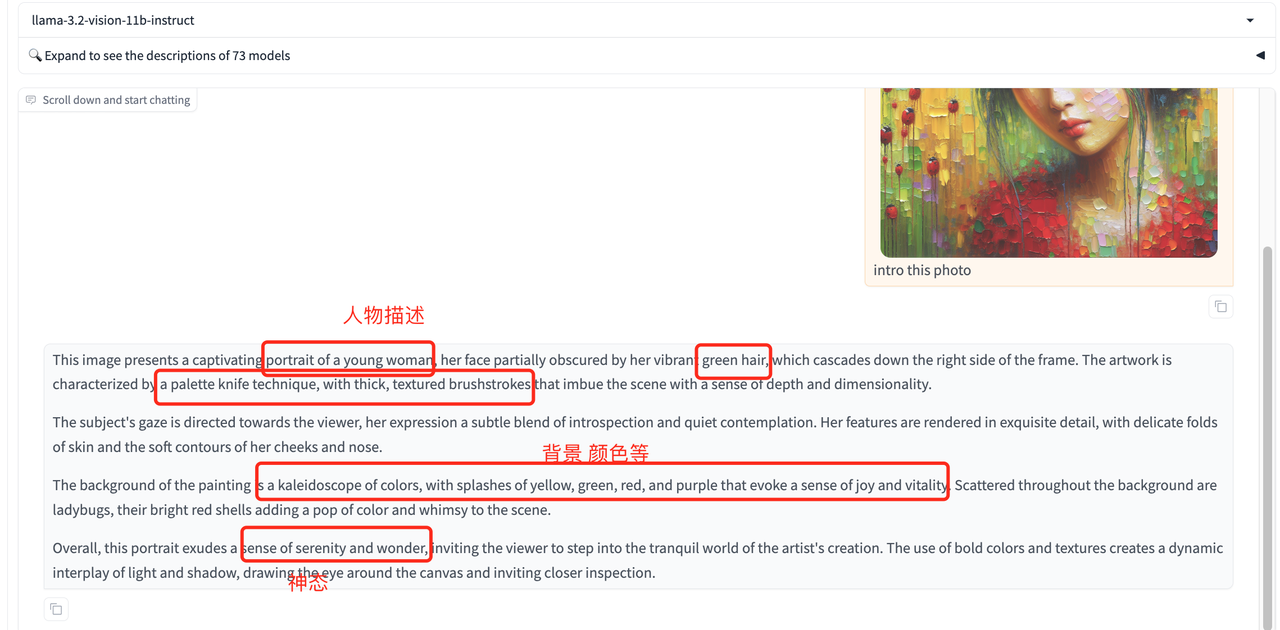
可以提取图片细节,理解图片场景,使得在语言和视觉之间建立起桥梁。
- LightWeight Model(1B/3B):
- 强大的文本生成能力和工具调用能力。
- 可以在设备上部署,数据隐私方面得到改进。
- MultiModel(11B/90B):
- 文档级理解:
- 图表、图形的理解。
- 如,根据图表的数据,进行推理,给出需要推理的答案。
- 图像标题和基础视觉任务:
- 如用自然语言对图片中的内容进行描述,方位描述等。
- 如,对地图进行理解,给出最优路线等。
四、模型评估
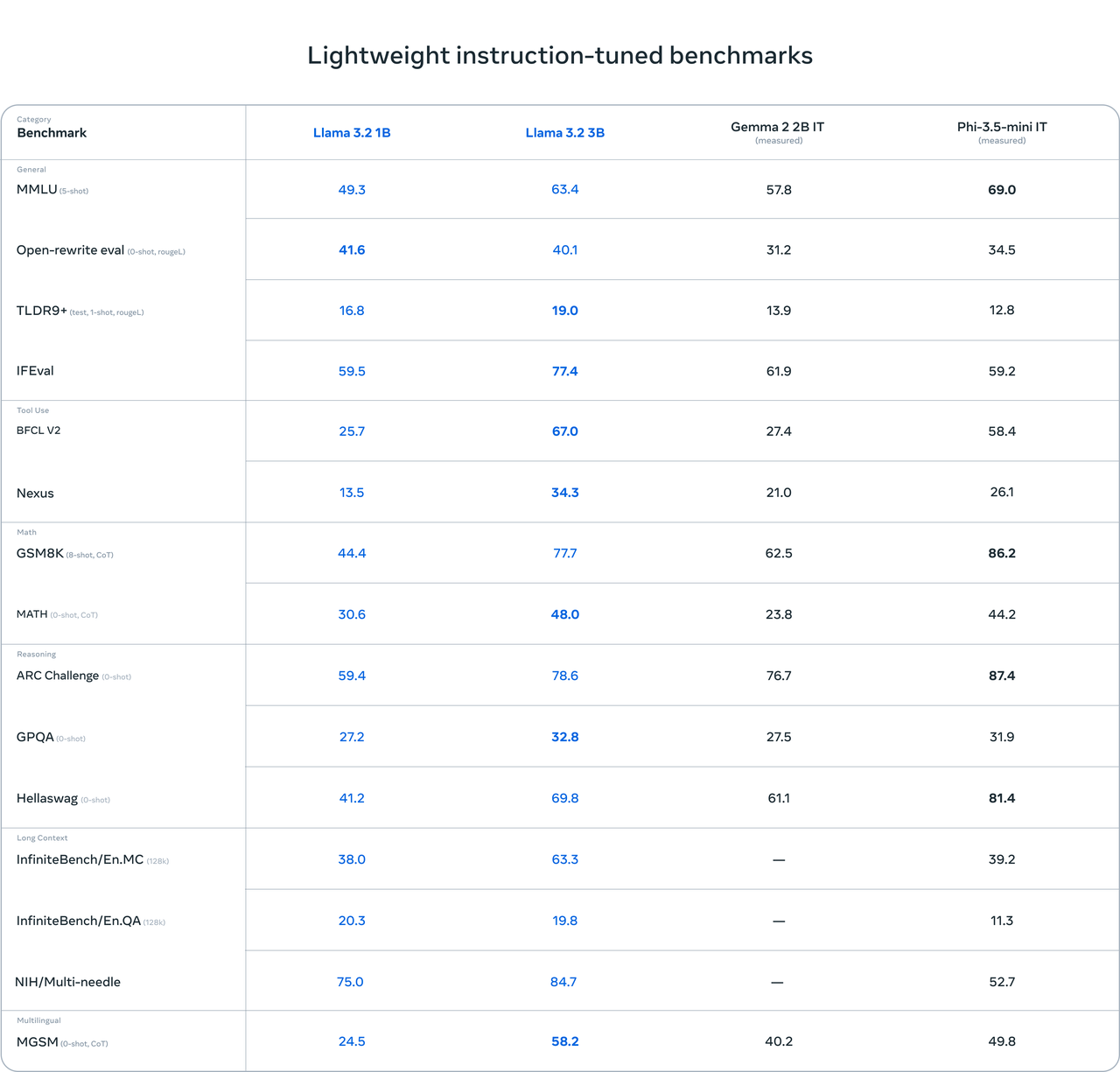
Benchmark评测,LLama3.2 3B 在Few-Shot和Tool Use以及上下文理解方面要优于Gemma2 2B和Phi-3.5 mini。Math和推理任务上,优于Gemma2 2B ,比Phi-3.5 mini稍差。
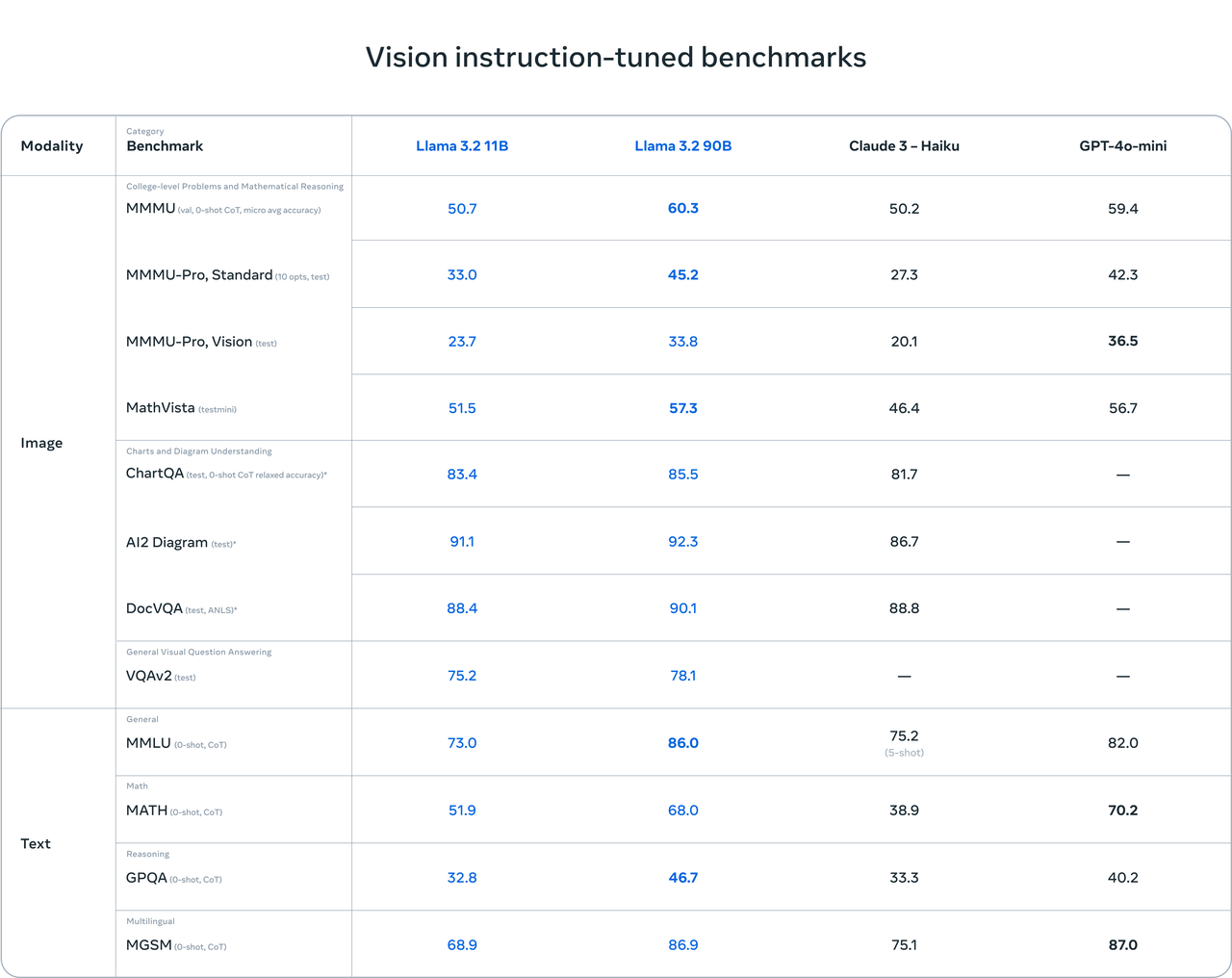
多模态模型,全面优于Gemma2 和 Phi-3.5。
五、模型原理
- LightWeight
预训练阶段,LLama3.2 使用了,剪枝和知识蒸馏两种方法。基于LLama3.1 的8B和70B 作为教师模型,来训练小模型。
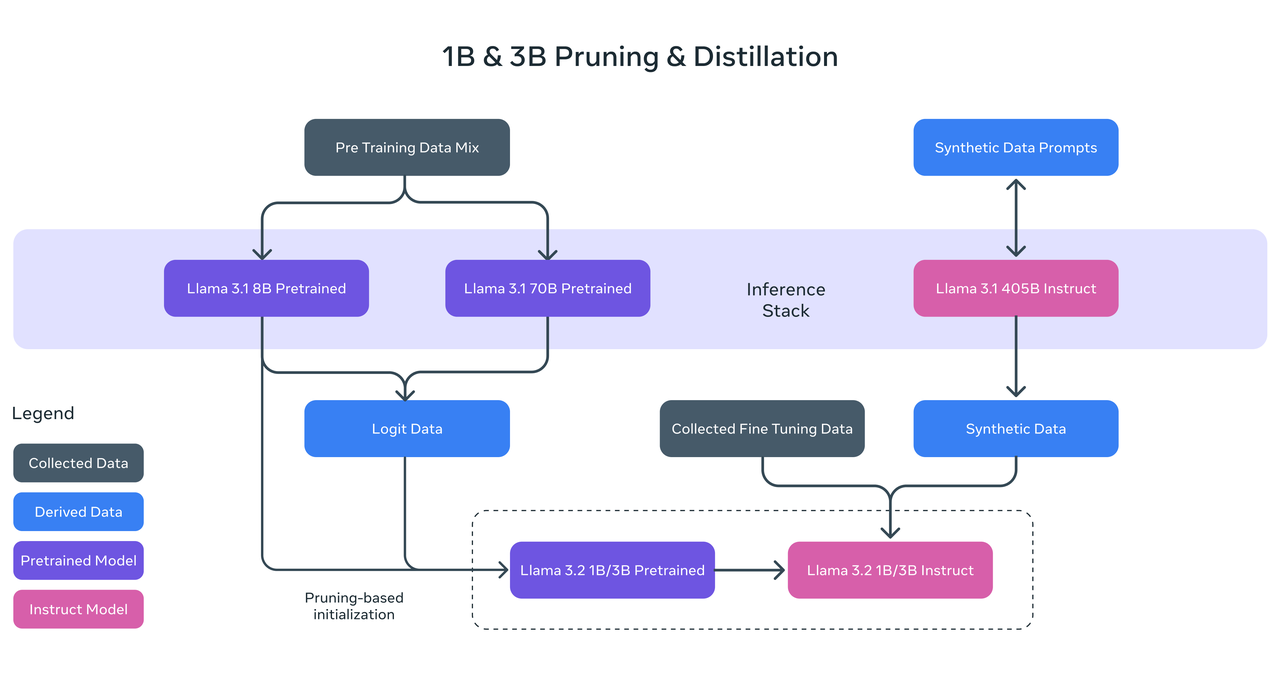
后训练阶段,使用了fine-tuning (SFT), rejection sampling (RS), and direct preference optimization (DPO).来提升模型性能,支持了128K Tokens。
- Vision models
设计了一个新的模型结构,在增加对图像输入的支持,训练了一组权重适配器,将预先训练好的图像编码器整合到预训练语言模型中。适配器有一系列的Cross Attention组成,可以将图像编码器特征输入语言模型,然后对文本和图像进行 适配器训练,使得图像和语言的表征保持一致。其实就是统一输入特征,只是将图像和文本的输入表示无限逼近即可。
六、试用
- LightWeight Model:
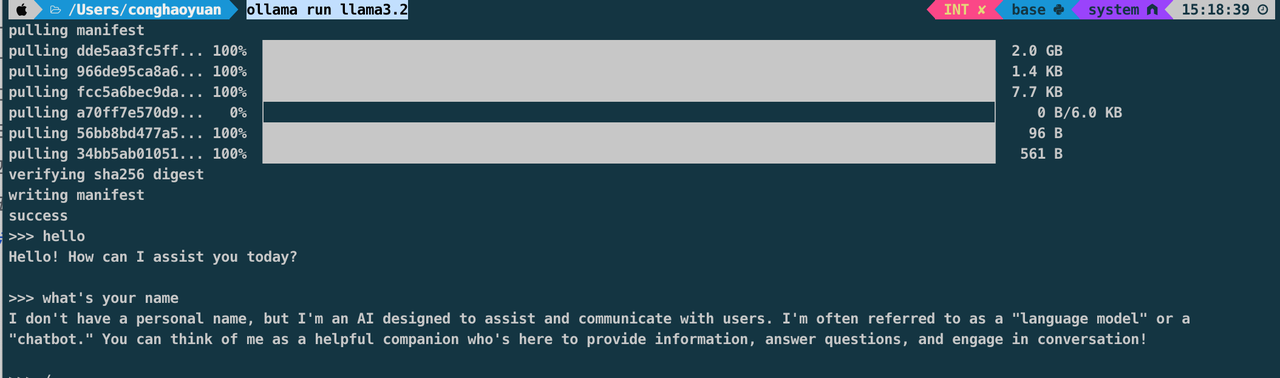
- Mac上部署:
- 安装ollama,https://ollama.com/
- terminal中运行:
ollama run llama3.2或着ollama run llama3.2:1b
- Groq试用:https://groq.com/#

- Vision Models:
- HuggingFace Space: https://huggingface.co/spaces/huggingface-projects/llama-3.2-vision-11B

 * https://lmarena.ai/ 选择Direct Chat Tab
* https://lmarena.ai/ 选择Direct Chat Tab