AIGC-大模型微调-LLama2-QLoRA微调
条评论QLoRA, 它是一种”高效的微调方法”, 以LLama 65B参数模型为例,常规16 bit微调需要超过780GB的GPU内存,而QLoRA可以在保持完整的16 bit微调任务性能的情况下, 将内存使用降低到48GB,即可完成微调。
环境搭建
- Hardware
- CPU: Arch x86_64 Intel(R) Xeon(R) Platinum 8163 CPU @ 2.50GHz 8Core
- Mem: 32G
- GPU: GPU 0: Tesla T4 15109 MB
- OS
- CentOS7.9.2009
- cuda 11.4
- Software
- Python3.10 / pip 22.3.1
- Model
- [accelerate][1]
- [peft][2]
- [alpaca-lora][3]
- [transformers][4]
- [qlora][5]
- Datasets
- [alpaca_data_zh_51k.json][6]
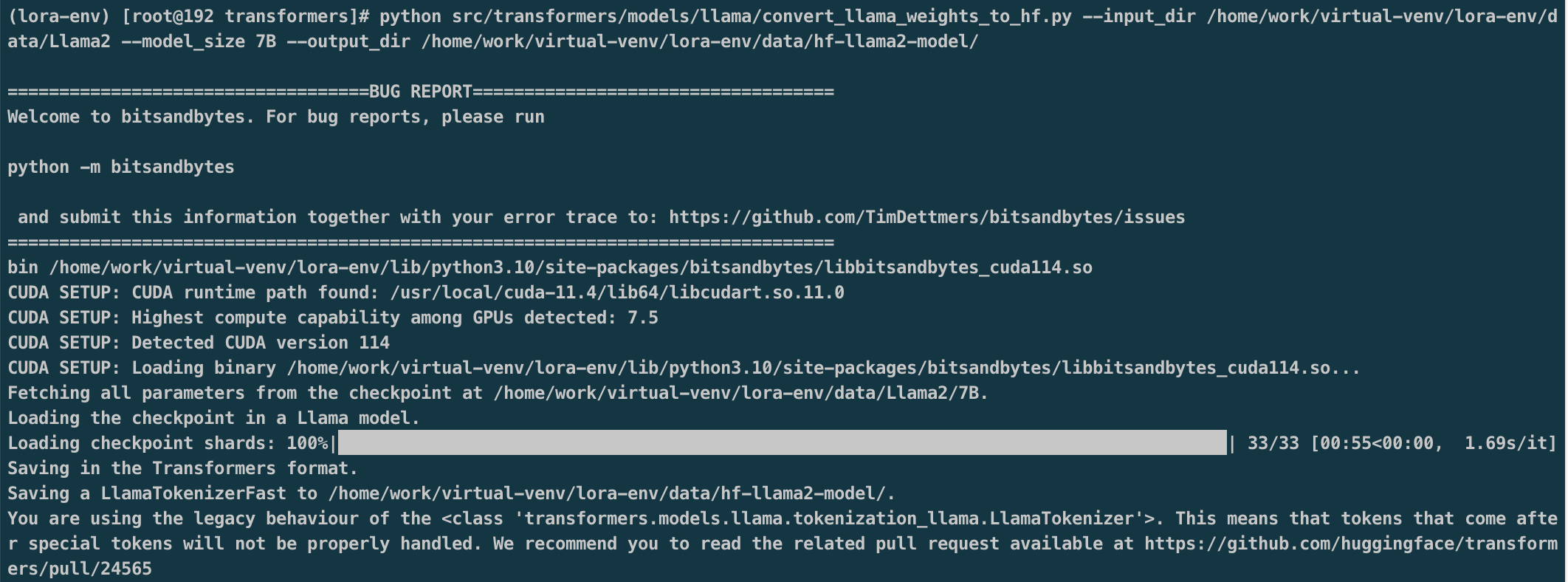
模型格式转换
将LLaMA原始权重文件转换为Transformers库对应的模型文件格式。
1 | python src/transformers/models/llama/convert_llama_weights_to_hf.py \ |
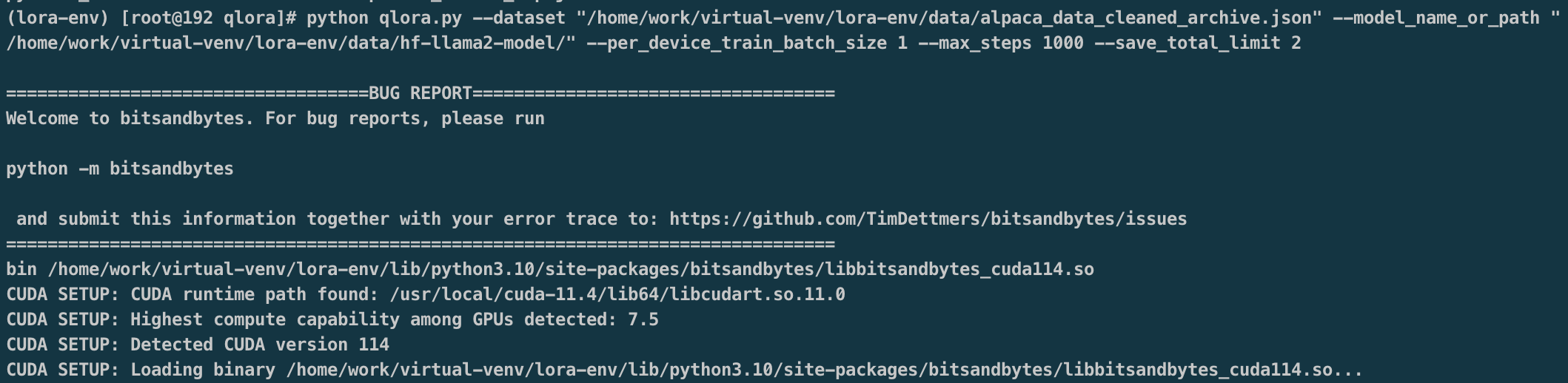
模型微调
1 | python qlora.py \ |
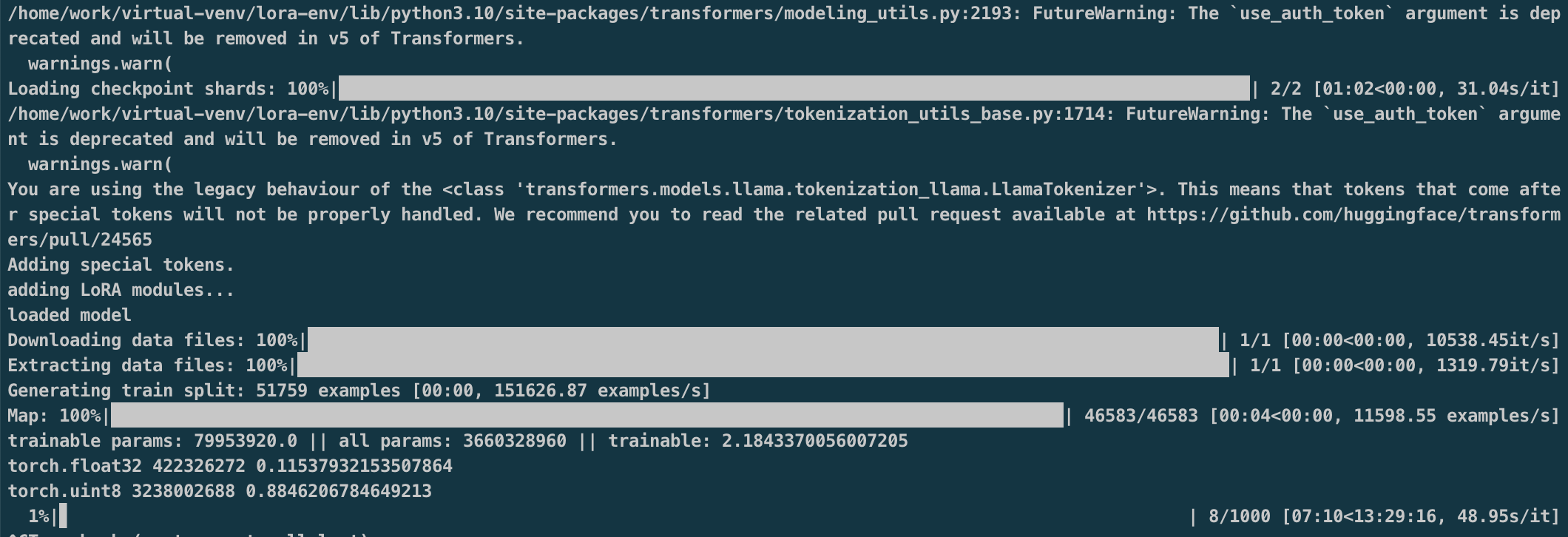
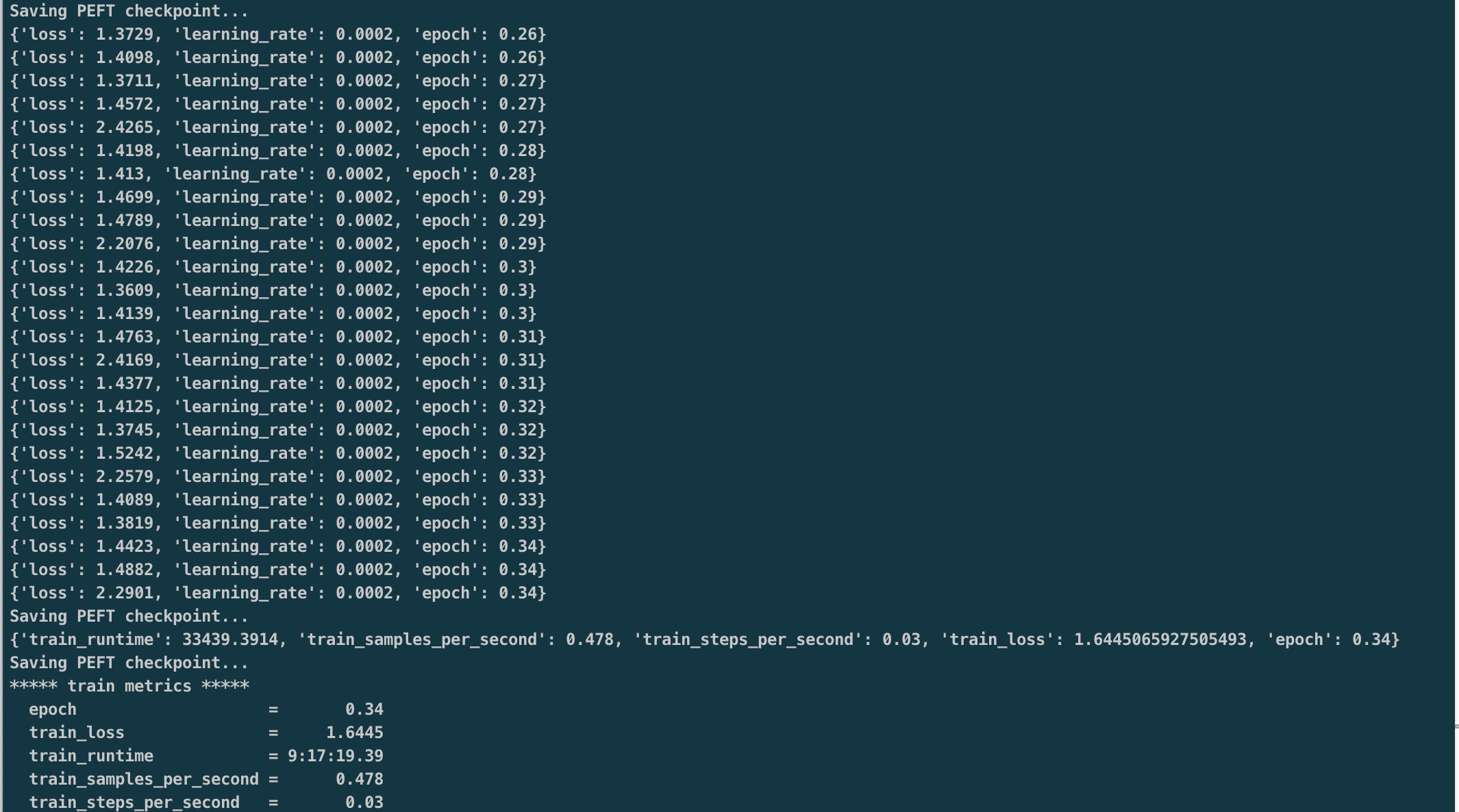
GPU使用
微调完,生成模型目录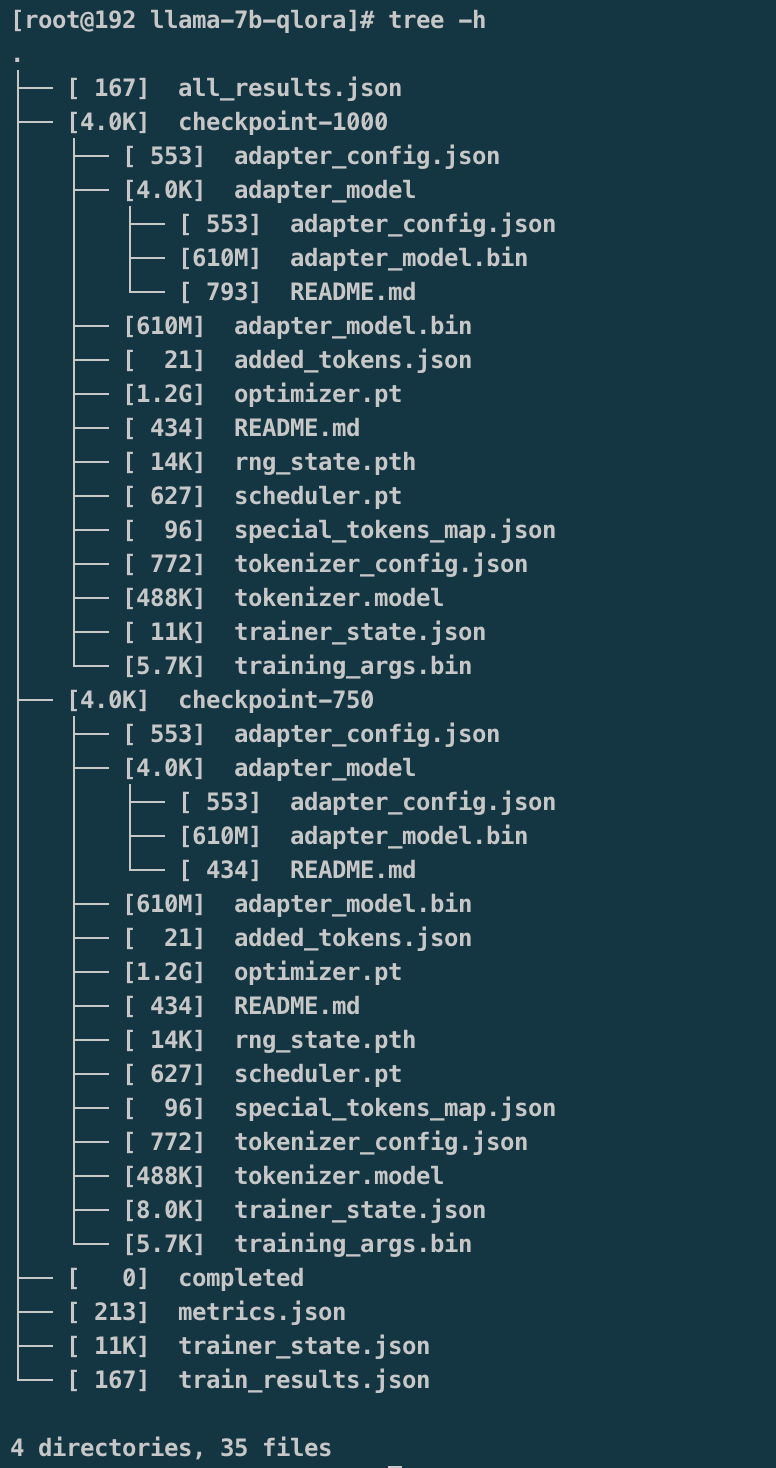
模型权重合并
1 | BASE_MODEL=/home/work/virtual-venv/lora-env/data/hf-llama2-model \ |
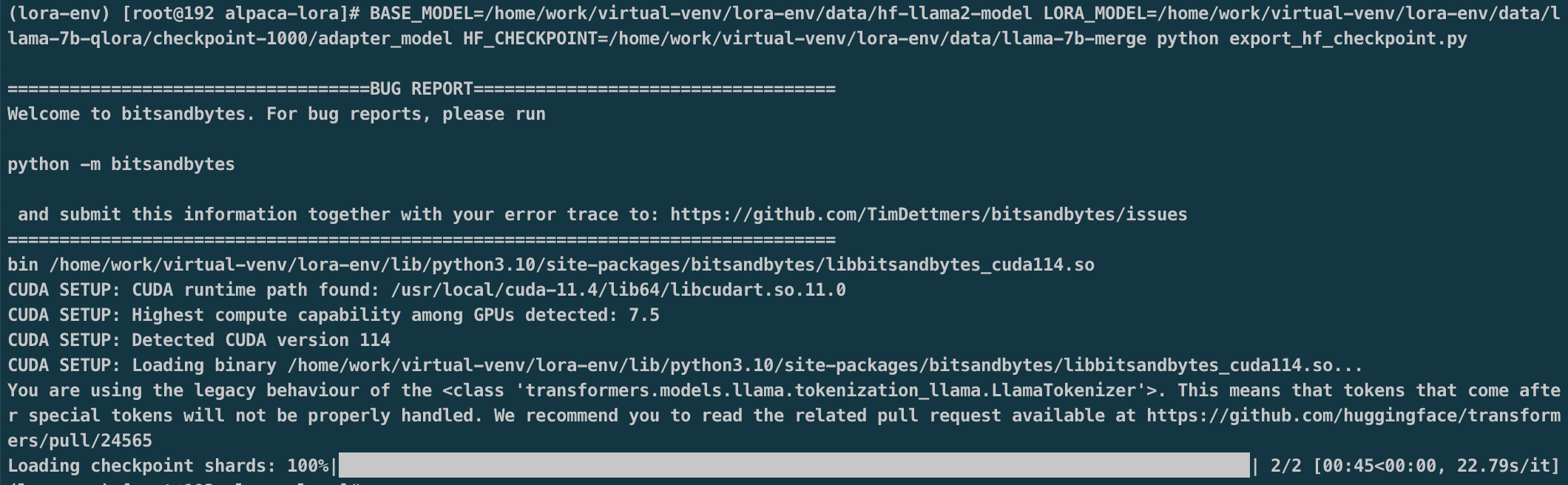
GPU使用
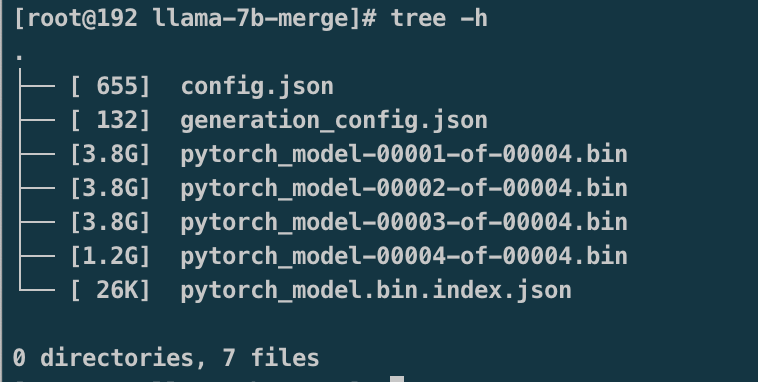
模型合并完成目录
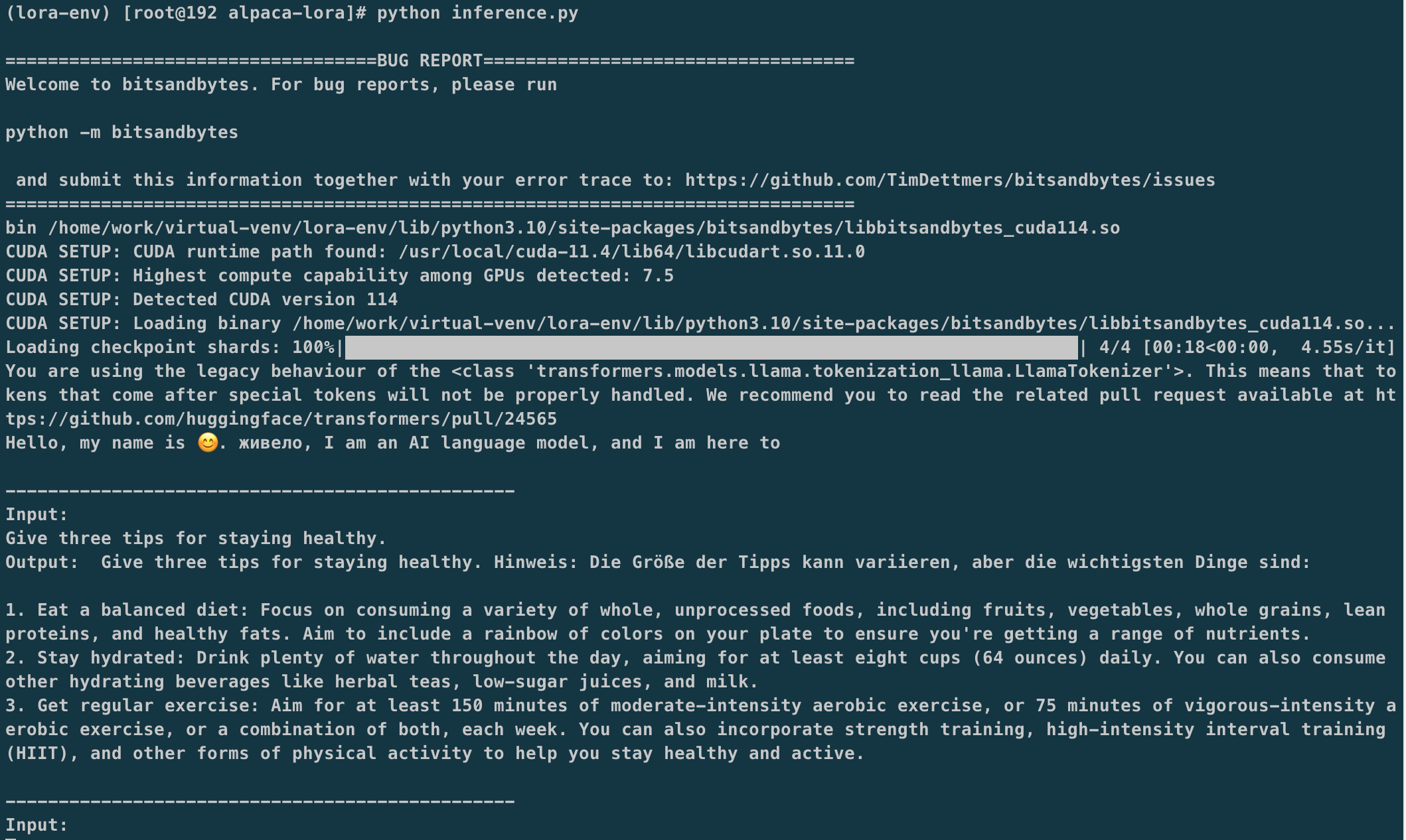
模型推理
1 | python inference.py |