MachineLearning-3.(回归)线性回归
条评论线性模型描述了一个或多个自变量对另一个因变量的影响所呈现的线性比例和关系。线性模型在二维空间内为一条直线,在三维空间中为一个平面,更高维度下的线性模型称为超平面。

|
|
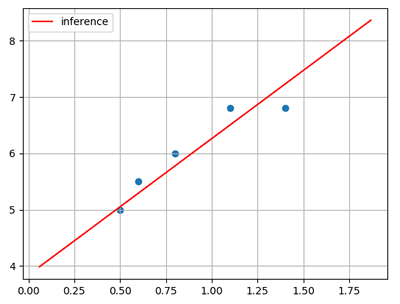
线性回归是要根据一组输入和输出数据(样本),寻找一个线性模型,能最佳程度拟合给定的数值分布,从而对新给定的输入数据进行输出预测。如:
| 输入(x) | 输出(y) |
|---|---|
| 0.5 | 5.0 |
| 0.6 | 5.5 |
| 0.8 | 6.0 |
| 1.1 | 6.8 |
| 1.4 | 6.8 |
根据样本拟合的线性模型:
线性模型定义
设给定一组属性$x, x=(x_1;x_2;…;x_n)$,线性方程的一般表达形式为:
$$
y = w_1x_1 + w_2x_2 + w_3x_3 + … + w_nx_n + b
$$
写成向量形式为:
$$
y = w^Tx + b
$$
其中,$w=(w_1;w_2;…;w_n), x=(x_1;x_2;…;x_n)$,w和b经过学习后,模型就可以确定. 当自变量数量为1时,上述线性模型即为平面下的直线方程:
$$
y = wx + b
$$
线性模型形式简单、易于建模,却蕴含着机器学习中一些重要的基本思想。许多功能强大的非线性模型可以在线性模型基础上引入层级结构或高维映射而得。此外,由于$w$直观表达了各属性在预测中的重要性,因此线性模型具有很好的可解释性。
例如,判断一个西瓜是否为好瓜,可以用如下表达式来判断:(参考周志华机器学习及西瓜书案例)
$$
f_{好瓜}(x) = 0.2x_{色泽} + 0.5x_{根蒂} + 0.3x_{敲声} + 1
$$
上述公式可以解释为,一个西瓜是否为好瓜,可以通过色泽、根蒂、敲声等因素共同判断,其中根蒂最重要(权重最高),其次是敲声和色泽.
模型训练
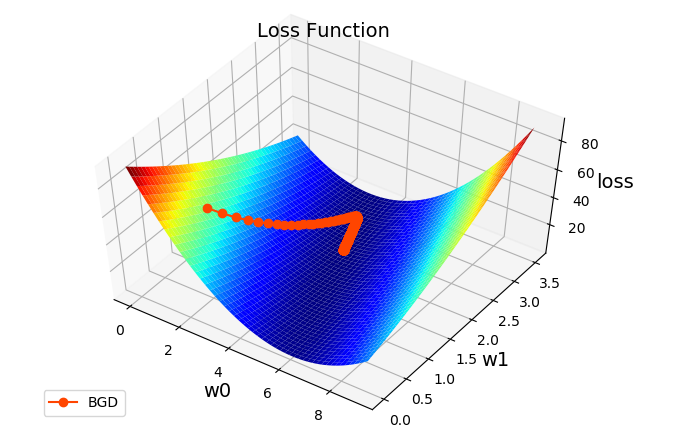
在二维平面中,给定两点可以确定一条直线。但在实际工程中,很多个样本点,无法找到一条直线精确穿过所有样本点,只能找到一条与样本“足够接近”或“距离足够小”的直线,近似拟合给定的样本,如:
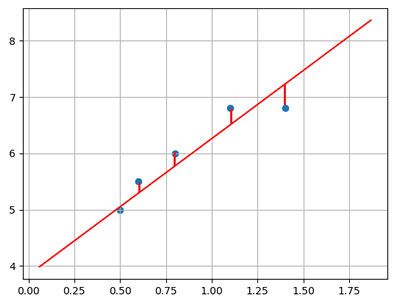
可使用损失函数度量所有样本到直线的距离。
损失函数
损失函数用来度量真实值(由样本中给出)和预测值(由模型算出)之间的差异。
- 损失函数值越小,表明模型预测值和真实值之间差异越小,模型性能越好;
- 损失函数值越大,模型预测值和真实值之间差异越大,模型性能越差。
在回归问题中,均方差是常用的损失函数,其表达式如下所示:
$$
E = \frac{1}{2}\sum_{i=1}^{n}{(y - y’)^2}
$$
其中,y为模型预测值,y’为真实值。线性回归的任务是寻找最优线性模型,损失函数值最小,即:
$$
(w^*, b^*) = arg min \frac{1}{2}\sum_{i=1}^{n}{(y - y’)^2} \
= arg min \frac{1}{2}\sum_{i=1}^{n}{(y’ - wx_i - b)^2}
$$
基于均方误差最小化来进行模型求解的方法称为“最小二乘法”。线性回归中,最小二乘法试图找到一条直线,使所有样本到直线的欧式距离之和最小。可将损失函数对w和b分别求导,得到损失函数的导函数,并令导函数为0即可得到w和b的最优解。
梯度下降
为什么使用梯度下降
在实际计算中,通过最小二乘法求解最优参数有一定的问题:
- 最小二乘法需要计算逆矩阵,有可能逆矩阵不存在;
- 当样本特征数量较多时,计算逆矩阵非常耗时甚至不可行.
所以,在实际计算中,通常采用梯度下降法来求解损失函数的极小值,从而找到模型的最优参数.
什么是梯度下降
已在DeepLearning学习笔记-4-数值计算/#基于梯度的优化方法中对梯度下降做了详细介绍。
线性回归实现
编程实现
1 | # 线性回归示例 |
程序执行结果:
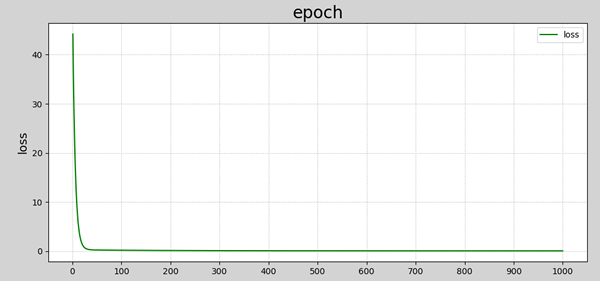
1 | 1 w0=1.00000000 w1=1.00000000 loss=44.17500000 |
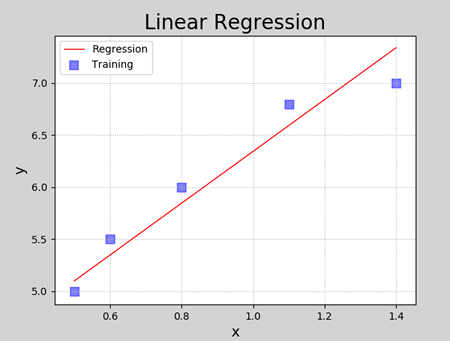
数据可视化:
1 | ###################### 训练过程可视化 ###################### |
通过sklearn API实现
同样,可以使用sklearn库提供的API实现线性回归。
1 | # 利用LinearRegression实现线性回归 |
执行结果:
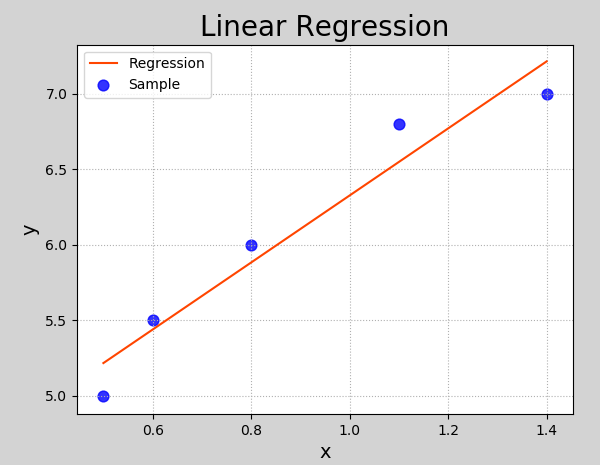
模型评价指标
平均绝对误差(Mean Absolute Deviation):单个观测值与算术平均值的偏差的绝对值的平均;
均方误差:单个样本到平均值差值的平方平均值;
MAD(中位数绝对偏差):与数据中值绝对偏差的中值;
R2决定系数:趋向于1,模型越好;趋向于0,模型越差.